Slipstream中的高可用(HA)
一个Application或者一个StreamJob,如果上游的流发生故障(例如意外退出)无法及时恢复,可能会导致整个系统的瘫痪。因此,流处理系统的高可用性显得尤为重要。
目录
一、Server HA
1.1 Server HA的原理
1.2 Server HA的配置
1.3 小结
二、Zookeeper模式的流处理高可用
2.1 Zookeeper模式的配置
2.2 注意事项
三、Slipstream HA的测试
一、Server HA
Slipstream InceptorServer的\{autofailover\}提供了InceptorServer级别的HA保证,可以保证在一台InceptorServer意外退出后,流任务会自动在另外一台InceptorServer上重新启动。Slipstream InceptorServer级别的\{autofailover\}需要部署至少两台Slipstream InceptorServer,其中一台工作在\{active\}模式,负责接收和处理流任务;剩余的Slipstream InceptorServer工作在\{standby\}模式,不负责接收和处理流任务。当\{active\} Slipstream InceptorServer意外退出后,其中一台\{standby\} Slipstream InceptorServer会切换成为\{active\} Slipstream InceptorServer并恢复流任务以及接收和处理新的流任务。
1.1 Server HA的原理
Slipstream InceptorServer级别的的\{autofailover\}需要与Inceptor Gateway配合实现。Inceptor Gateway配置与多台Slipstream InceptorServer的连接。这些配置的Slipstream InceptorServer共享与Metastore, Zookeeper和HDFS(以下简称共享元数据)的连接。Inceptor Gateway与多台Slipstream InceptorServer及Slipstream InceptorServer与共享元数据的连接关系如下图所示:
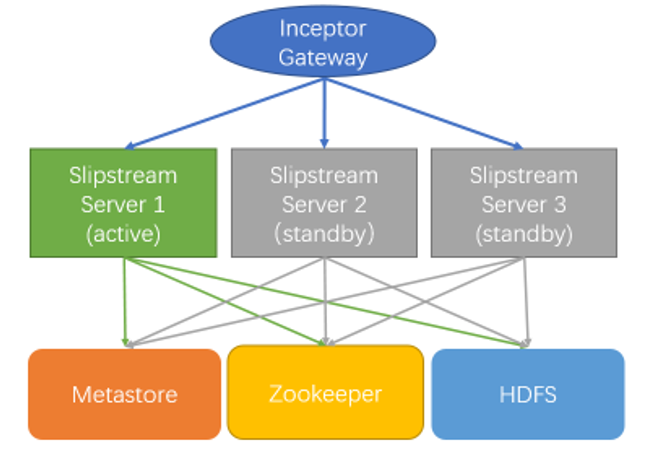
上述Slipstream InceptorServer工作在一种\{active\}/\{standby\}模式下,即只有在与Inceptor Gateway的连接中,上述Slipstream InceptorServer才有\{active\}/\{standby\}模式的区分,其中的\{active\} Slipstream InceptorServer负责接收Inceptor Gateway提交的流任务并进行处理,而\{standby\} Slipstream InceptorServer不会接收到Inceptor Gateway提交的流任务。在\{active\} Slipstream InceptorServer发生意外退出后, Inceptor Gateway会检测到与\{active\} Slipstream InceptorServer的连接中断。在Inceptor Gateway检测到与\{active\} Slipstream InceptorServer的连接中断后, Inceptor Gateway会选择一台\{standby\} Slipstream InceptorServer成为新的\{active\} Slipstream InceptorServer,并在这台Slipstream InceptorServer上尝试恢复在原来的\{active\} Slipstream InceptorServer上运行的流任务。
1.2 Server HA的配置
如果需要开启Slipstream InceptorServer级别的\{autofailover\},需要部署多台(至少2台)Slipstream InceptorServer,配置这些Slipstream InceptorServer共享Metastore、Zookeeper和HDFS,安装配置方法如下:1、在8180监控界面选择“+服务”,选择Slipstream组件,点击“下一步”。
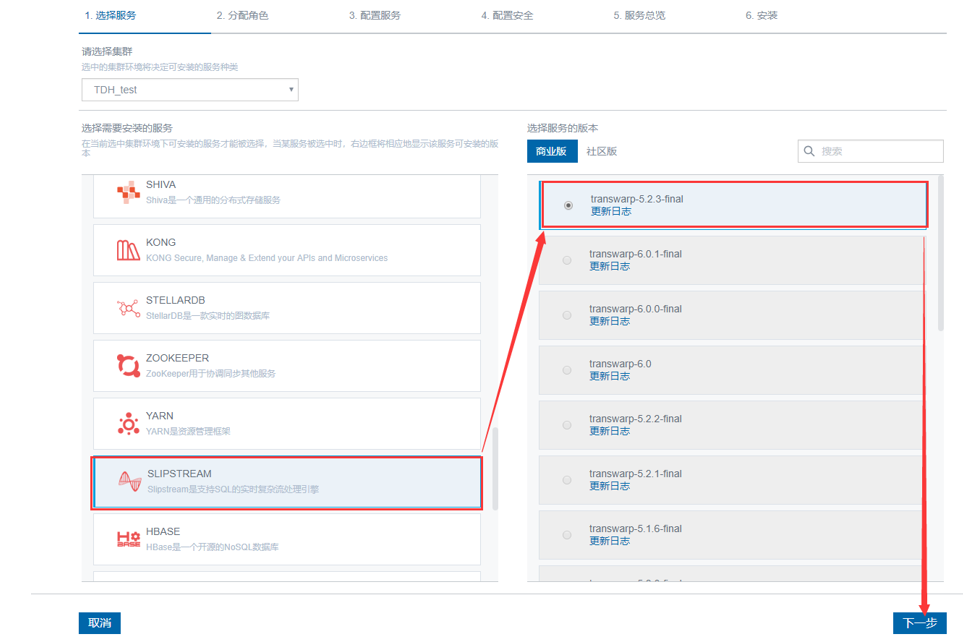
如果要配置Slipstream高可用的话,需要共享MetaStore,此时不需要选择Slipstream的MetaStore,选择共享Inceptor MetaStore,其余的配置可按照默认或者自定义均可。注意:此时若集群中已经安装了Slipstream,安装的Slipstream也需选择共享Inceptor MetaStore,而且不需要配置Slipstream的MetaStore(如果在共享Inceptor MetaStore的同时开启了Slipstream的MetaStore那么组件在启动的时候回启动失败)。
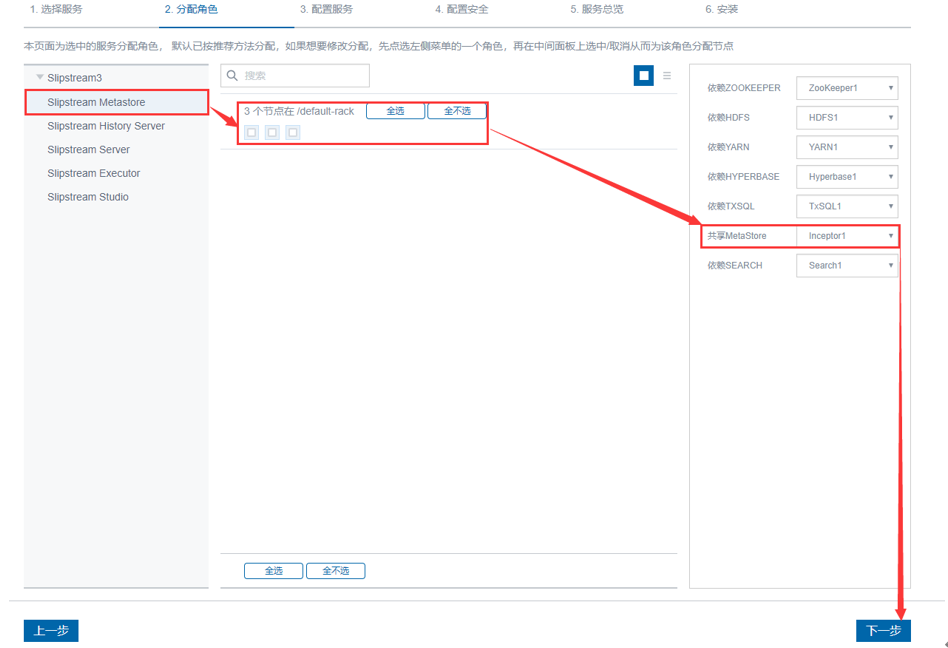
点击“下一步”,直至安装成功。2、安装多个Slipstream Server成功后,多台Slipstream InceptorServer需要配置使用相同的Zookeeper集群,并配置使用相同的Zookeeper目录,其中涉及到的配置项如下:
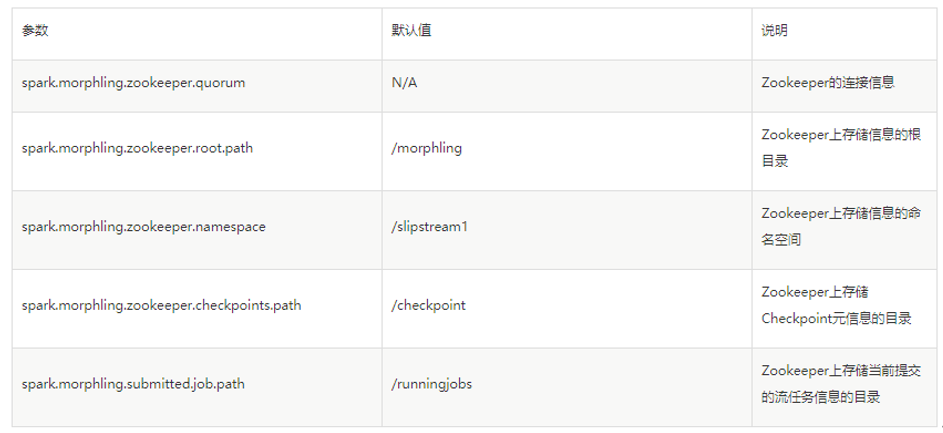
3、多台Slipstream InceptorServer需要配置使用相同的HDFS集群,并配置使用相同的HDFS目录,其中涉及到的配置项如下:
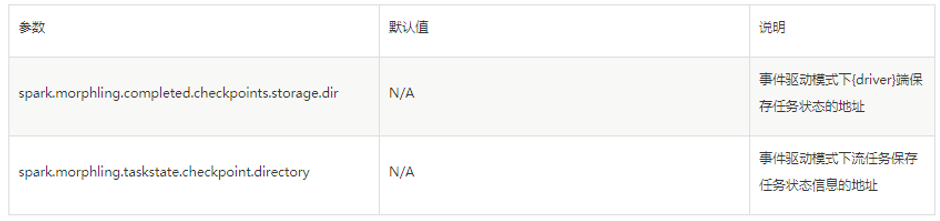
4、Inceptor Gateway需要配置和多台Slipstream InceptorServer的连接,如果集群中已经安装了Inceptor Gateway组件,可以直接对相关配置文件进行参数配置;如果集群中没有安装Inceptor Gateway组件,需要先去“应用市场”中安装该组件。Inceptor Gateway 的高可用配置包括宕机转发和超时转发两方面。宕机转发是指,当优先提供服务的InceptorServer发生宕机(连接不上或执行过程中发生异常)时,Inceptor Gateway会请求切换到另一InceptorServer。超时转发是指,当优先提供服务的InceptorServer执行超时时,Inceptor Gateway会请求切换到另一InceptorServer。该功能涉及到三个配置文件:servers.xml、route-rule.xml、route-cluster.xml。(1)servers.xml文件:Inceptor Gateway需要从servers.xml文件获取可用的InceptorServer的信息。
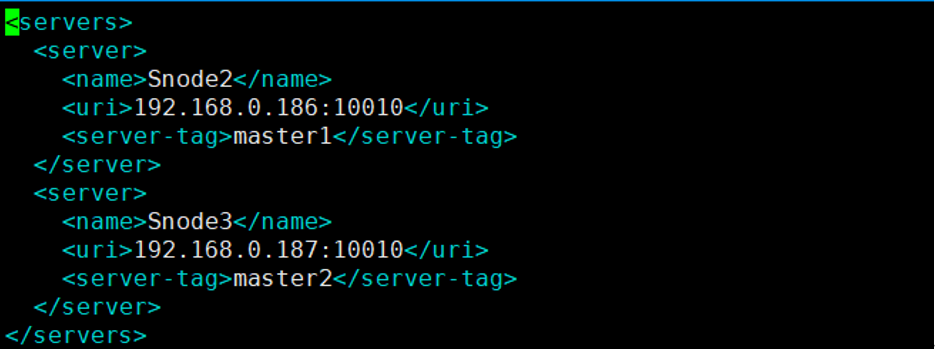
(2)route-rule.xml文件:将所有的请求导向集群TDH\_test。
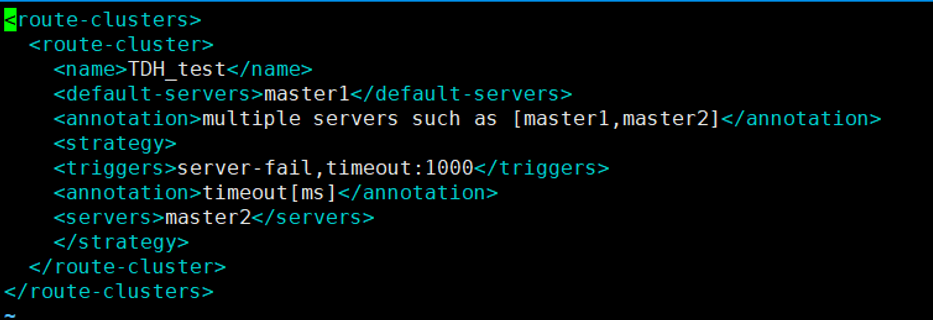
(3)route-cluster.xml文件:name为集群名称,default-servers为servers.xml文件中的server-tag名称并非servers.xml文件中的name名称,并配置可用的服务名称,服务名称也需为servers.xml文件中的server-tag名称。设置切换InceptorServer的策略为“server-fail”和“timeout:1000”。“server-fail”为宕机转发;“timeout:1000”为超时转发,例如当客户端向master1服务发出请求1000ms还未得到响应,Inceptor Gateway就将其转发到master2服务。
**注意:**对于开启了Kerberos的InceptorServer集群,Inceptor Gateway暂时不能支持使用。
1.3 小结
Slipstream InceptorServer的\{active\}/\{standby\}模式并非真正意义上的\{active\}/\{standby\}模式。对处于\{standby\}模式的Slipstream InceptorServer,仍然可以直接连接到这台Slipstream 的InceptorServer,并进行流任务的提交与处理。但是这样做会带来流任务重复提交,从而造成数据不一致的风险。在\{active\} Slipstream InceptorServer意外退出并重新上线后,Inceptor Gateway仍然会将新的流任务提交到该Slipstream InceptorServer上,而非提交到已经切换为\{active\}模式的Slipstream InceptorServer上。Slipstream InceptorServer级别的\{autofailover\}只对事件驱动模式下的流任务可用,微批模式不支持InceptorServer级别的\{autofailover\}。要开启Slipstream InceptorServer级别的\{autofailover\},必须要开启流任务级别的HA。
二、Zookeeper模式的流处理高可用
Zookeeper模式下的流任务元信息保存在Zookeeper上,此外该模式下还会保存某个任务每次已经完成的Checkpoint信息到HDFS上。这样就保证了即使整个Slipstream集群发生异常退出后重启恢复的时候,流任务还能保证计算结果的准确性。
2.1 Zookeeper模式的配置
Zookeeper模式需要在8180界面配置如下参数:1、基础参数
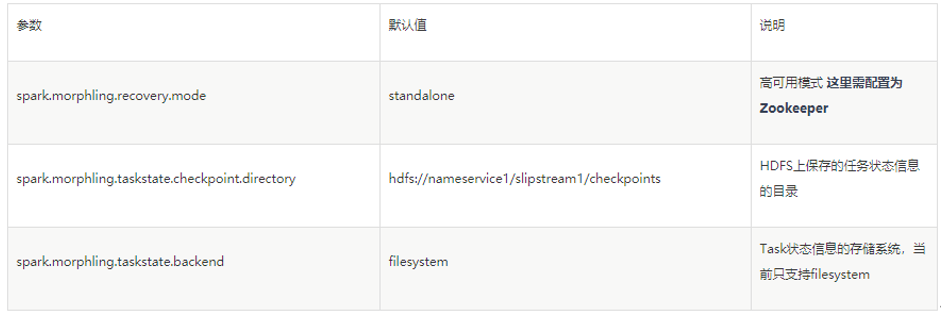
2、Zookeeper相关配置

3、Checkpoint相关配置

2.2 注意事项
Zookeeper上的目录以及HDFS的目录为Slipstream启动时生成的,若不慎删除可能导致开启Checkpoint的流任务无法正常启动,此时需要手动创建该目录并赋相应的权限。
三、Slipstream HA的测试
Slipstream HA 配好之后,使用流与表之间的GlobalLookupJoin进行相关测试。首先使用[《Slipstream中流与流、流与表之间的join》][Slipstream_join]中“流与表之间的GlobalLookupJoin”的方法创建相关的流与表,值得注意的是,Slipstream流任务高可用性只在事件驱动模式下支持,即流任务中需要设置了"streamsql.use.eventmode"="true"。要使用Slipstream流任务级别的高可用性,必须通过使用CREATE STREAMJOB的方式来定义流任务,所对应的任务级别的参数则是在JOBPROPERTIES中指定。所以在触发流的时候必须通过CREATE STREAMJOB的方式来触发,如下:CREATE STREAMJOB one AS ("insert into tab select * from s1")JOBPROPERTIES("streamsql.use.eventmode"="true","morphling.task.max.failures"="5","morphling.job.enable.checkpoint"="true","morphling.job.checkpoint.interval"="5000","morphling.job.enable.auto.failover"="true");CREATE STREAMJOB two AS ("insert into t1 select * from s3")JOBPROPERTIES("streamsql.use.eventmode"="true","morphling.task.max.failures"="5","morphling.job.enable.checkpoint"="true","morphling.job.checkpoint.interval"="5000","morphling.job.enable.auto.failover"="true");参数释义:(1)streamsql.use.eventmode:流任务使用事件驱动模式;(2)morphling.task.max.failures:Task失败最大重试次数;(3)morphling.job.enable.checkpoint:为流任务开启Checkpoint;(4)morphling.job.checkpoint.interval:流任务Checkpoint的时间间隔;(5)morphling.job.enable.auto.failover:开启流任务的Auto-Failover。创建StreamJob后可使用如下命令查看创建了哪些StreamJob:show streamjobs;
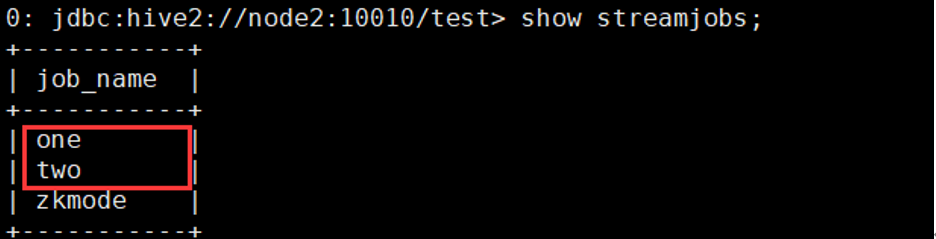
使用如下命令开启StreamJob:START STREAMJOB one;START STREAMJOB two;
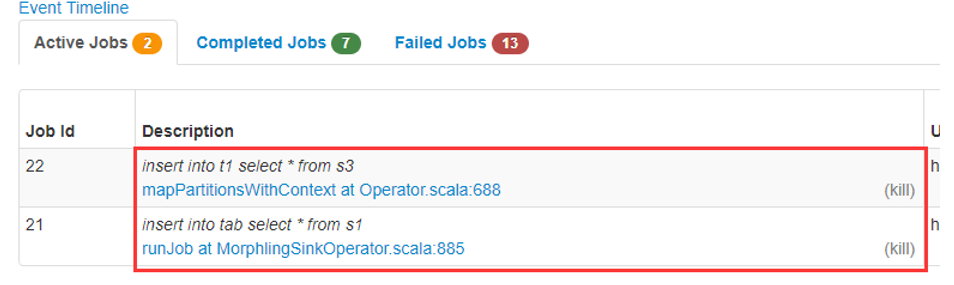
此时可以点击上图中的“kill”对之前配置的高可用进行测试,杀掉一条StreamJob后,对页面进行刷新,发现被杀死的StreamJob会自动重启。开启Kafka中的相关topic生产数据进行测试:
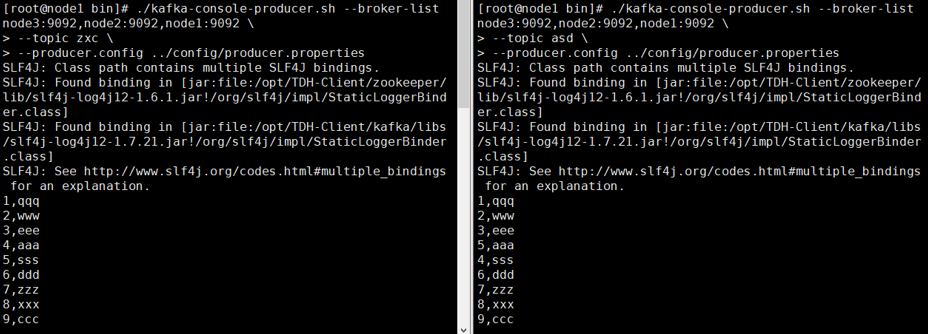
查询结果表可得:





























实验二")





还没有评论,来说两句吧...