Python 爬虫入门 requests lxml bs4
一:前言
正式学习爬虫的第一天,感觉信息量巨大。用此篇博客来快速入门爬虫并爬取古诗文网的内容。(使用 requests lxml bs4)

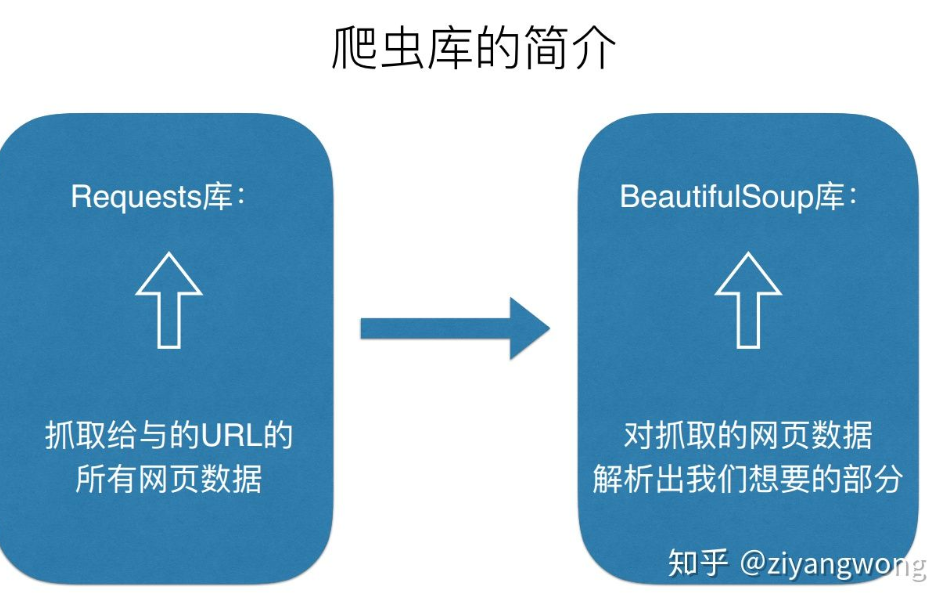
二:过程
2.1 获取 url 中的 html 代码
中文官方文档指引(http://docs.python-requests.org/zh_CN/latest/user/quickstart.html),内容繁琐比较多,本文精简整理必要内容。
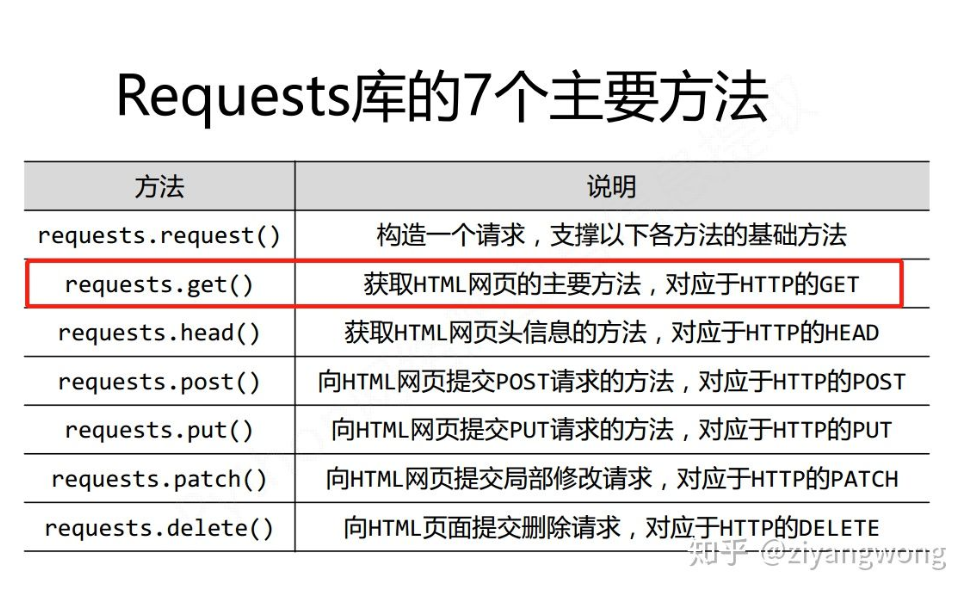
先安装requests
pip install requests
在文档中引入
import requests# url 是古诗文网的url = 'https://so.gushiwen.org/guwen/Default.aspx?p=1&type=%e6%ad%a3%e5%8f%b2%e7%b1%bb'html = requests.get(url)print('该响应状态码:', html.status_code)print('相应内容:', html.text)
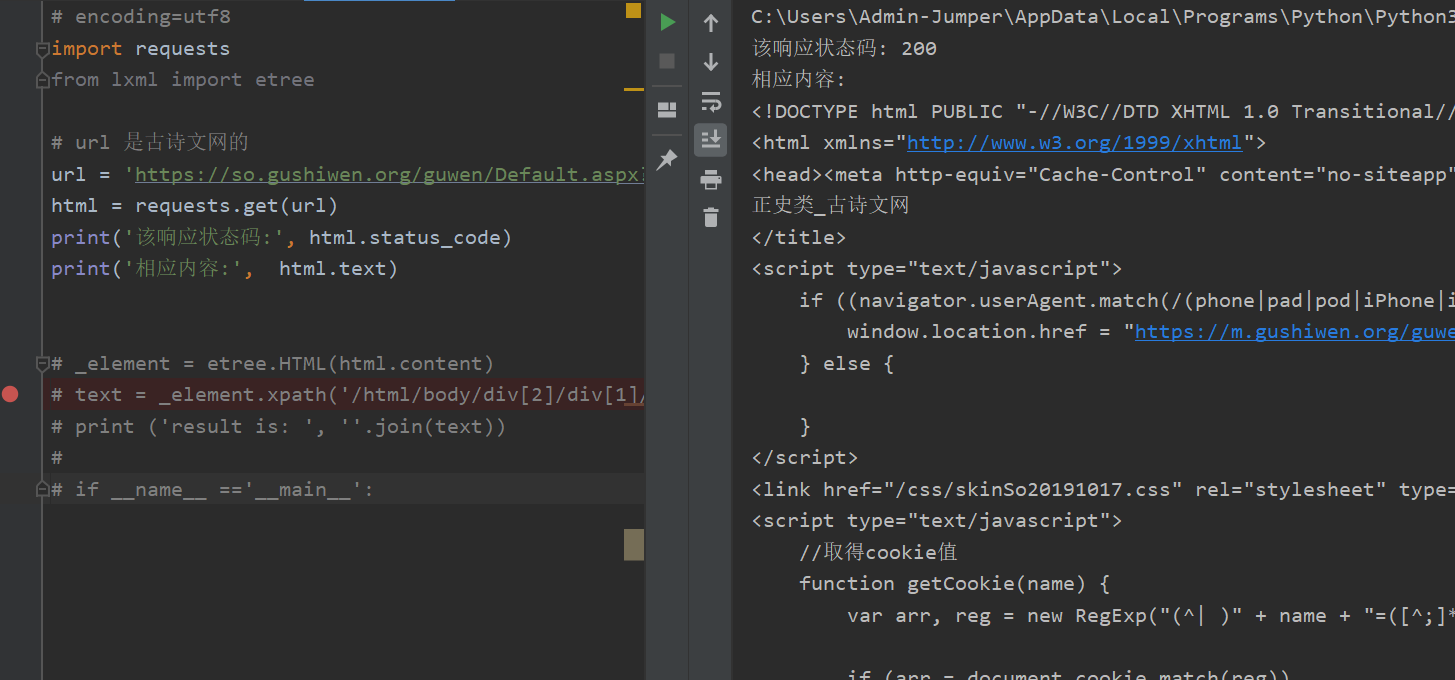
如此获得到相应页面的html代码
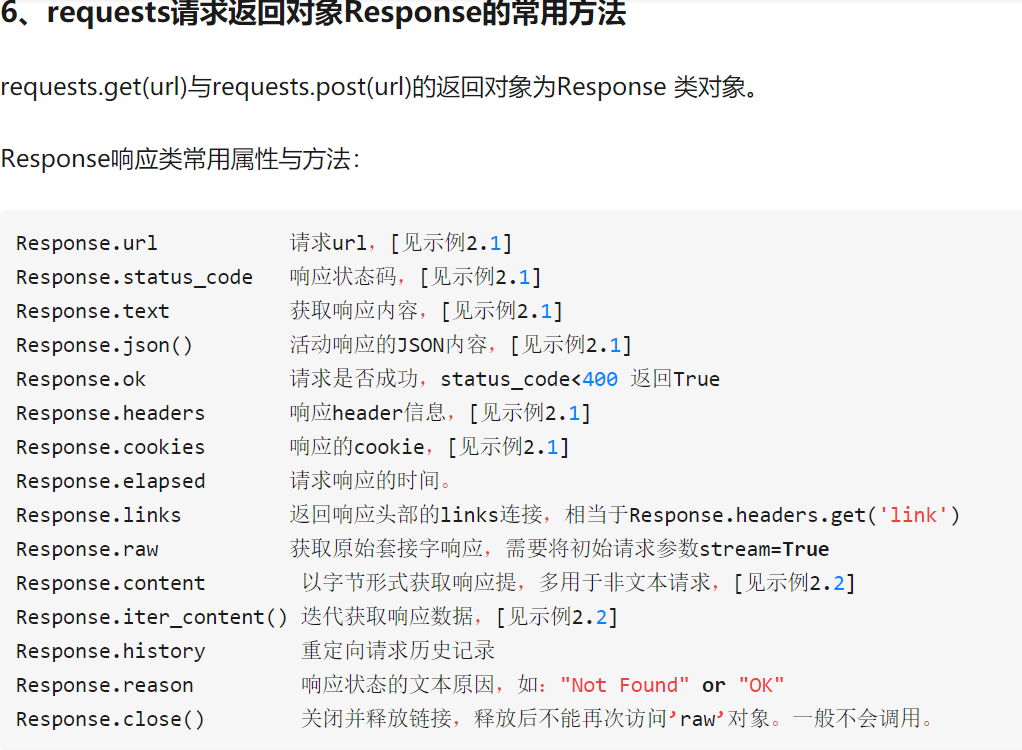
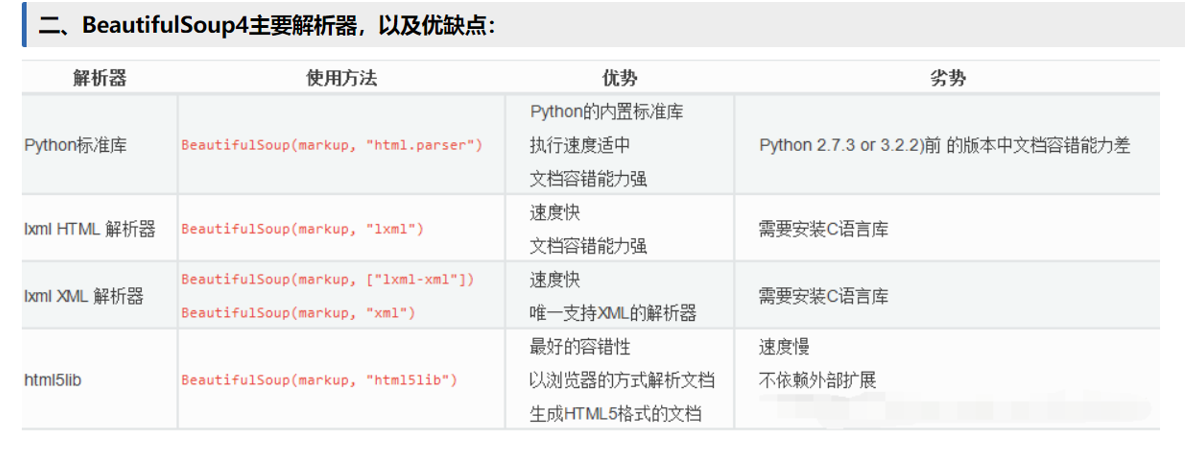
2.2 解析所需要的HTML代码(beautifulsoup 和lxml是两种解析方式,推荐lxml方式,简单快速)
2.2.1 使用BeautifulSoup来解析
先安装bs4
pip install bs4
用靓汤来对response进行解析,获取网页源代码
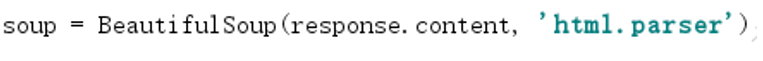
方法:
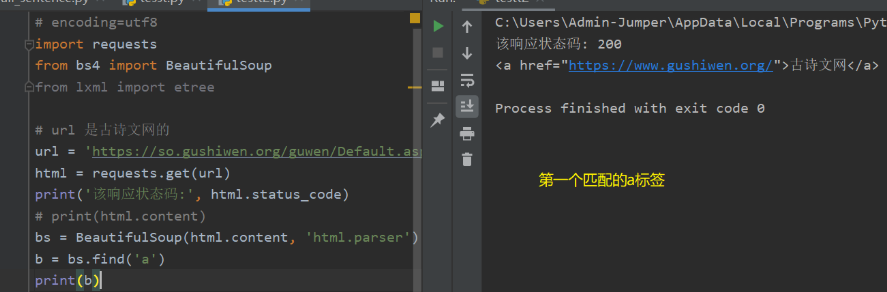
1.find(name,attrs,recursive,text,**wargs) find(‘p’)即寻找第一个匹配的p节点
2.find_all(name,attrs,recursive,text,**wargs) find_all(‘p’)即寻找所有p节点
attrs
有两种情况则要用到参数attrs:一是标签字符中带有-,比如data-custom;二是class不能看作标签属性。解决的办法是在attrs属性用字典进行传递参数
css选择器 select()

实例解析:
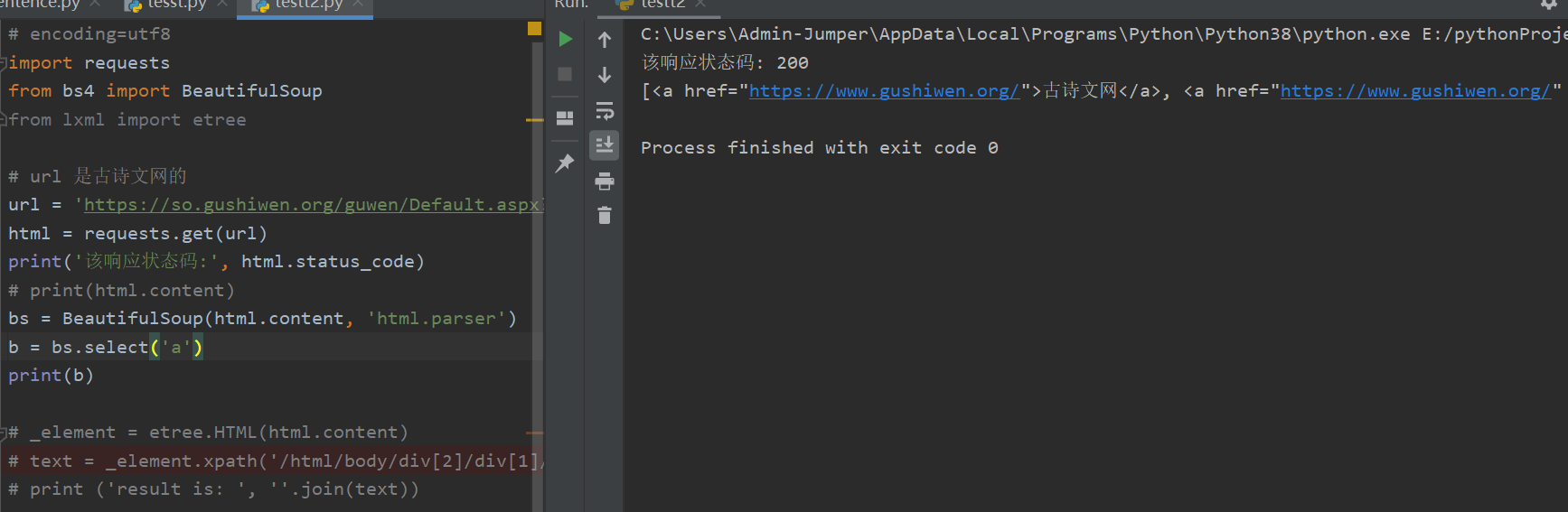
# 首先引入BeautifulSoupimport requestsfrom bs4 import BeautifulSoup# url 是古诗文网的url = 'https://so.gushiwen.org/guwen/Default.aspx?p=1&type=%e6%ad%a3%e5%8f%b2%e7%b1%bb'html = requests.get(url)print('该响应状态码:', html.status_code)# print(html.content)bs = BeautifulSoup(html.content, 'html.parser')b = bs.select('a')print(b)
2.2.2 使用lxml来解析
先安装lxml
pip install lxml
requests是用来获取网页源代码,lxml.etree是用来解析网页的,和beautifulsoup中的html.parser或者lxml解析是一个作用。
# encoding=utf8import requestsfrom lxml import etree# url 是古诗文网的url = 'https://so.gushiwen.org/guwen/Default.aspx?p=1&type=%e6%ad%a3%e5%8f%b2%e7%b1%bb'html = requests.get(url)print('该响应状态码:', html.status_code)et = etree.HTML(html.content)t = et.xpath('/html/body/div[2]/div[1]/div[3]/div[1]/p[2]/text()')print(t)
效果:

如何获取xpath:
1.打开F12 ,选取所需要的元素
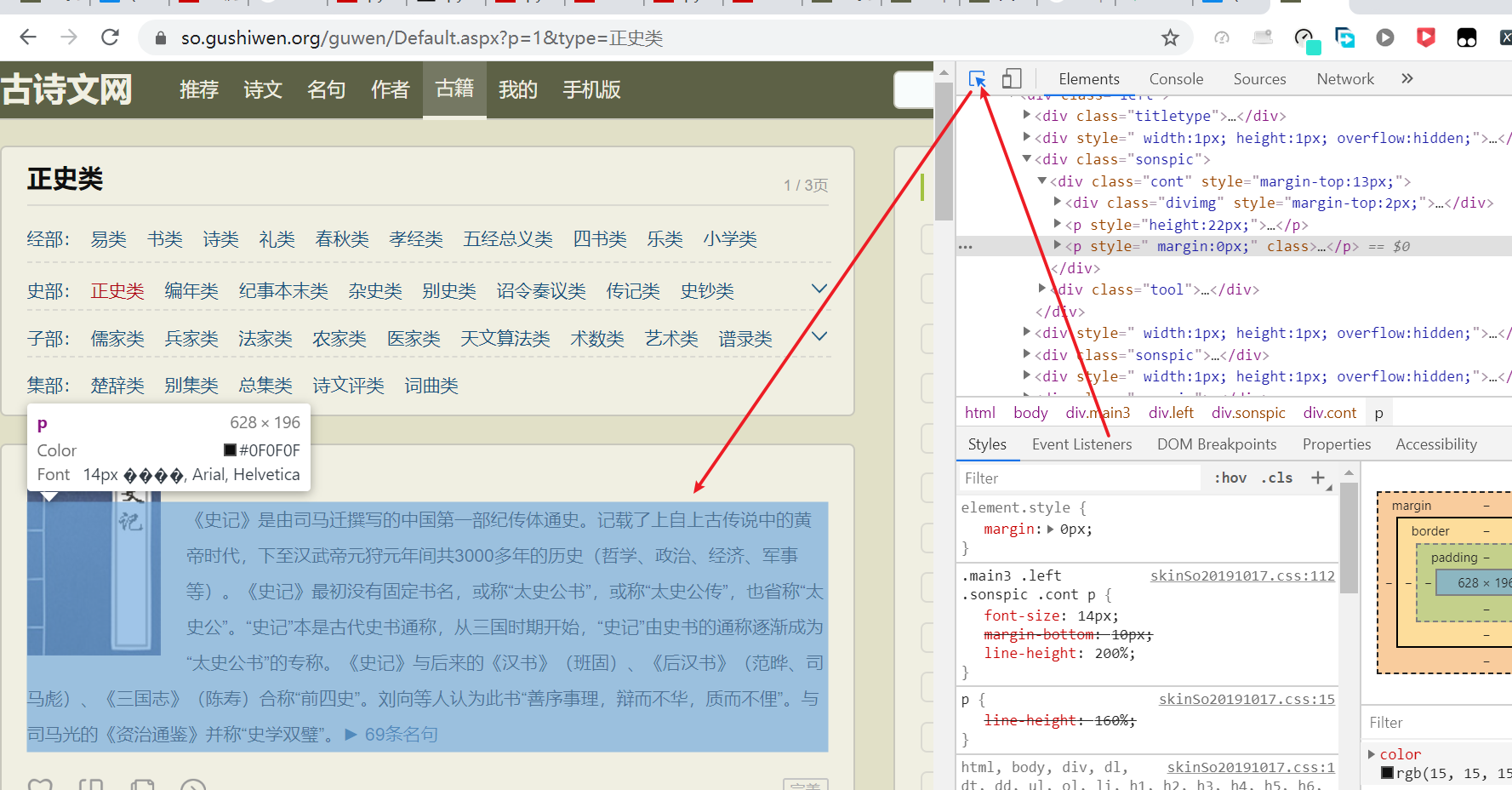
- 复制xpath
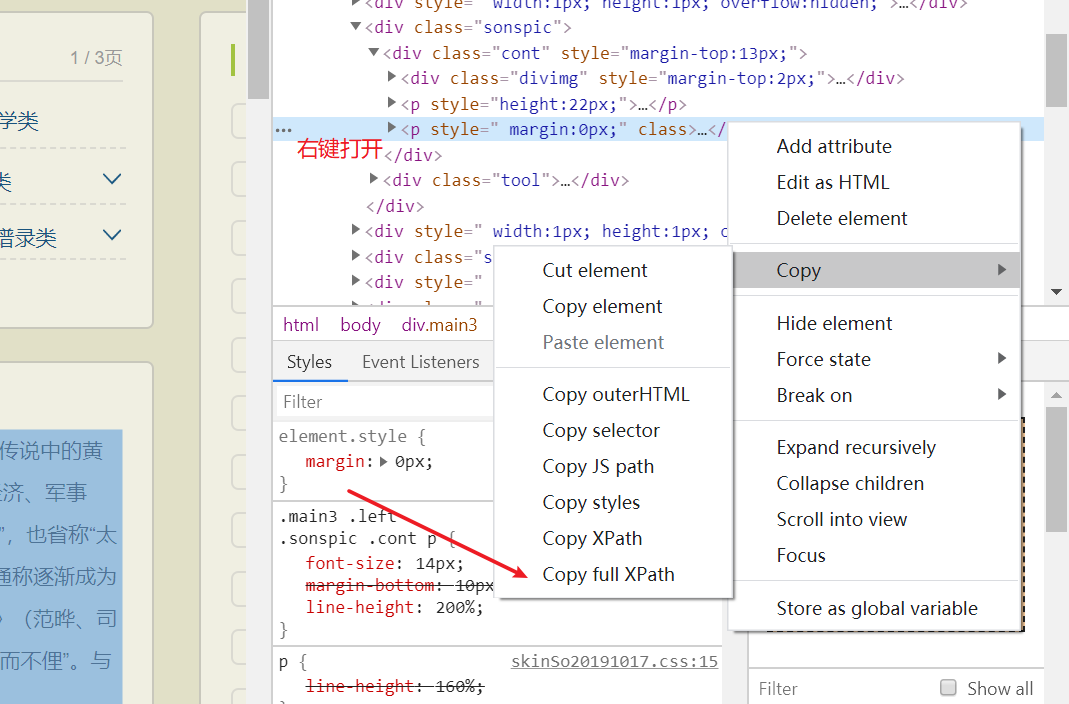
- 替换,发现没有效果。。。。
原来是开头那里有一个这个东西
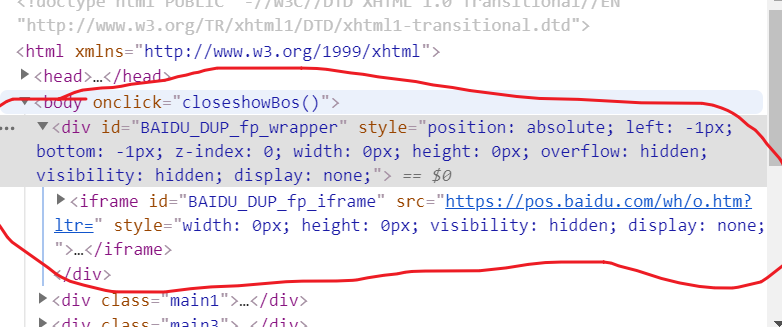
导致爬下来的内容中缺了这东西导致爬下来的内容不对称(可能是标签iframe爬不下来。。。。。。)
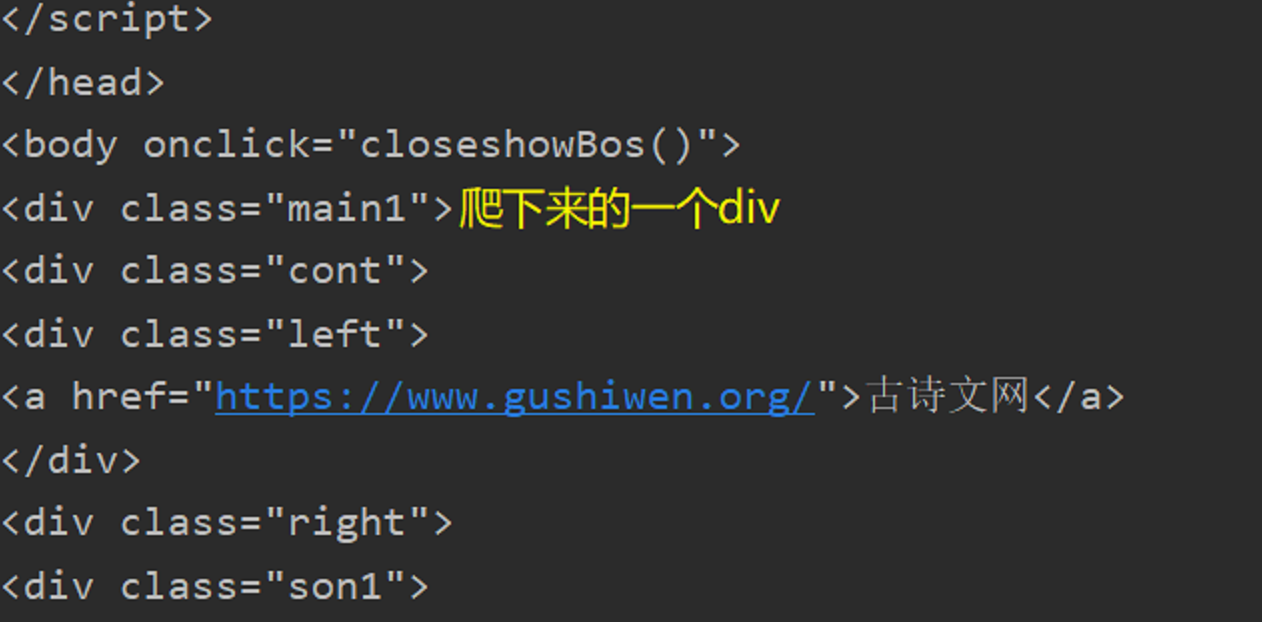
所以它的xpath应该改一改
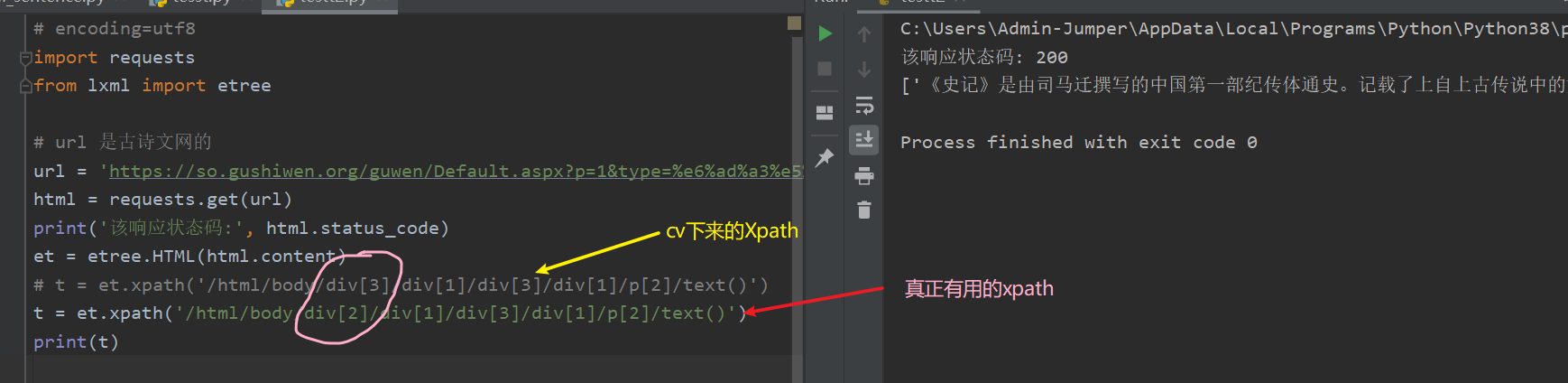
这样就可以弄下来了。
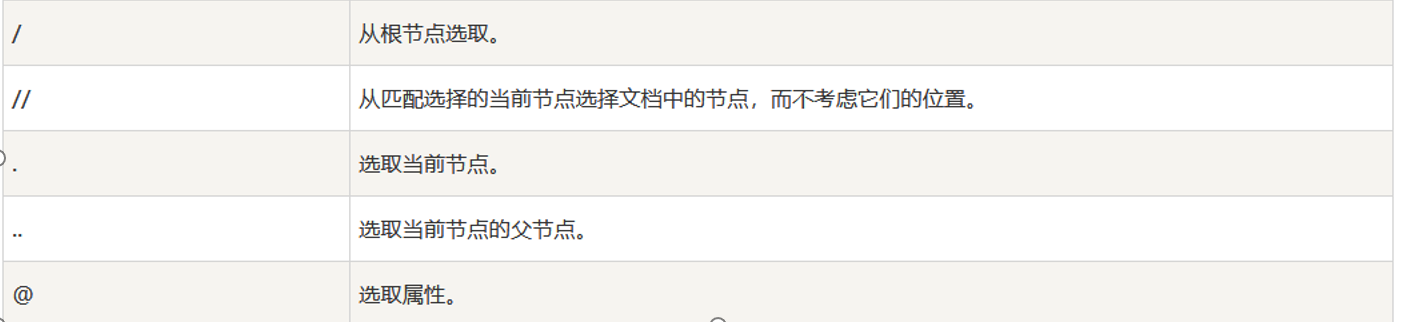
xpath语法:
Xpath的使用要用到lxml库解析
@lang 使用@获取属性
@href
详细语法: https://www.runoob.com/xpath/xpath-syntax.html
2.3 装饰器

三:总结
最后发现爬虫也太难搞了吧,一不小心就掉坑里了,找了好久才发现问题。
这个可能要多练习,多熟悉套路啊!!
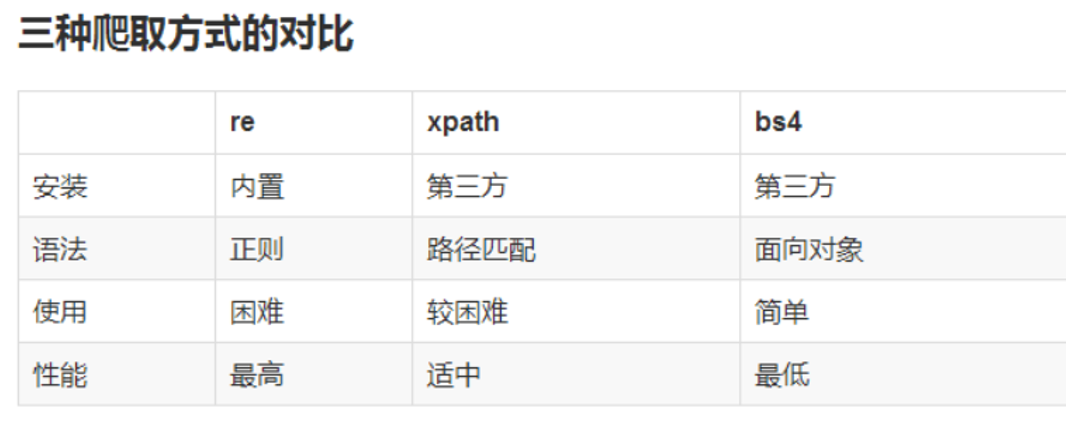
这几种方法多练习吧,一种不行就换另一种。



























")






还没有评论,来说两句吧...