深度学习之手写数字识别——用bp神经网络实现
任务
设计一个bp神经网络是实现对MNIST手写数字集的识别任务。
网路结构包含一个输入层、一个隐层和一个输出层。 其实总共只有两个层级结构。
包、数据集载入
我们使用tensorflow来简化我们的操作。
import tensorflow as tfimport numpy as npfrom tensorflow.examples.tutorials.mnist import input_data# 载入数据集data = input_data.read_data_sets('MNIST_data/', one_hot=True)
层级结构设计
输入层中输入的张量设为x,类型为32位浮点型,x以占位符形式定义,并且其维度为784。并且每次迭代样本个数并不确定,主要由迭代batch的大小决定。
x = tf.placeholder(dtype=tf.float32, shape=[None, 784])
隐层牵涉到权值参数与偏置项的设定。在未运行算法之前,需要对权重参数与偏置项进行初始化。
为防止权重参数恒为0,我们采用tensorflow的内置方法,将权重参数初始化为拥有固定标准差的高斯分布的张量,方法如下:
def weight_variable(shape):#权重的初始化initial = tf.truncated_normal(shape, stddev=0.1)return tf.Variable(initial)
对于偏置项,我们可以直接将其初始化为某一固定常量,方法如下:
def bias_variable(shape):#偏置项的初始化initial = tf.constant(0.5, shape=shape)return tf.Variable(initial)
为了增强模型的复杂度,令其拥有较强的识别能力,定义一个隐层来对输入的图像数据(28*28*1)进行相应的非线性映射和梯度传播。
为了防止命名冲突也为了代码逻辑清晰,设立两个命名空间来存储对应变量,其中隐层1位于命名空间hidden_layer中,输出层位于命名空间output_layer中。
hidden_layer、output_layer中分别牵涉到变量w1、b1、w2、b2,分别代表隐层的突触权重、偏置项,输出层的突触权重、偏置项。激活函数设定为relu函数,隐层末尾添加dropout来随机的断开连接。
在经过两个层级结构的计算和映射之后,将得到一个预测结果。故输出层是一个由softmax函数作为输出单元,最终输出是一个含10个概率值的行向量。设输出为y,则y的得出将根据上一个隐层计算出的张量L1得出,实现代码如下:
# 定义神经网络结构def bp_nn(x, keep_prob):with tf.name_scope('hidden_layer'):w1 = weight_varibal([784, 500])b1 = bias_variabl([500])h1 = tf.nn.relu(tf.matmul(x, w1) + b1)L1 = tf.nn.dropout(h1, keep_prob=keep_prob)with tf.name_scope('output_layer'):w2 = weight_varibal([500, 10])b2 = bias_variabl([10])y = tf.nn.softmax(tf.matmul(L1, w2) + b2)return y
实现过程
在定义好了层级结构之后,我们还需要定义超参数、标签、梯度下降优化器、损失函数等。
代码如下:
# dropout随机断开的概率keep_prob = tf.placeholder(dtype=tf.float32)# 标签y_ = tf.placeholder(dtype=tf.float32, shape=[None, 10])# 最终预测值y = bp_nn(x, keep_prob)# 定义交叉熵损失函数cross_entropy = -tf.reduce_sum(y_ * tf.log(y))# 梯度下降优化目标函数train_step = tf.train.GradientDescentOptimizer(0.001).minimize(cross_entropy)# 这是我们算法运行过程中需要判断的模型准确率correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
要知道tensorflow是基于运算图的框架,所以我们在定义了一系列占位符、操作、变量等tensor后,需要在会话里跑起来,不断地迭代!
迭代代码如下:
with tf.Session() as sess:sess.run(tf.global_variables_initializer())for i in range(10000):x_batch, y_batch = data.train.next_batch(100)sess.run(train_step, feed_dict={ x: x_batch, y_: y_batch, keep_prob: 0.8,})if i % 1000 == 0:train_accuracy = sess.run(accuracy, feed_dict={ x: x_batch, y_:y_batch, keep_prob:1.0})print('精度' + str(train_accuracy))print('-----------------------载入测试集----------------------')acc = []for i in range(1000):batch = data.test.next_batch(100)test_accuracy = sess.run(accuracy, feed_dict={ x: batch[0], y_:batch[1], keep_prob:1.0})acc.append(test_accuracy)mean_accuracy = np.mean(acc)print(mean_accuracy)
最终输出如下:
精度0.25
精度0.95
精度0.99
精度1.0
精度0.99
精度0.98
精度0.98
精度1.0
精度0.99
精度0.99
-———————————载入测试集———————————
0.97859997
精度不断上升,并在dropout的作用下,并不稳定。最终测试集上的精度达到0.98。
我们将损失函数的变化记录在tensorboard中,变化如下图所示,可以看出来loss呈现明显下降趋势。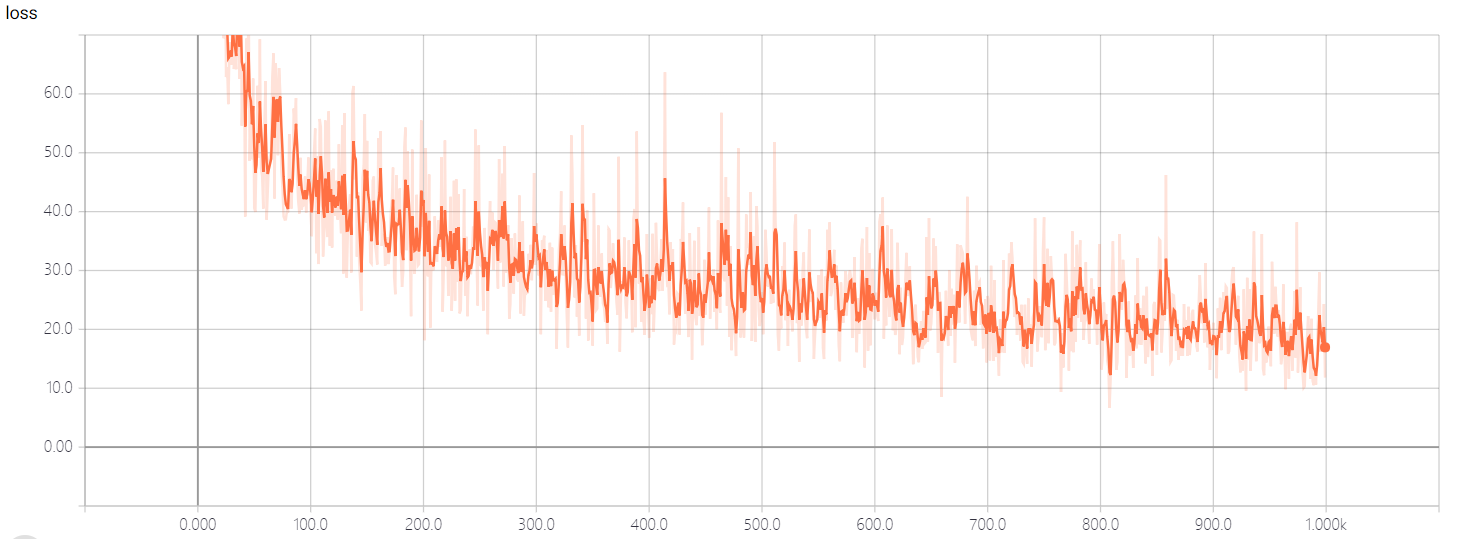
改进
为了进一步提升模型准确率,我将在下一篇文章中采用卷积神经网络(CNN)来解决该问题。

























")








还没有评论,来说两句吧...