k均值图像分割的GPU加速
图像分割是指把图像分成各具特性的区域并提取出感兴趣目标的技术和过程,是从图像处理到图像分析的关键步骤。K均值聚类算法是目前最受欢迎和应用最为广泛的聚类分析方法之一。K均值聚类算法用于图像分割具有直观、快速、易于实现的特点。不过当图像很大或者k很大时,采用k均值算法进行图像分割会异常缓慢,所以我们需要对其进行加速。幸运的是,k均值算法最核心的步骤具有很高的并行性,这给我们加速带来了很大遍历。我们既可以通过openmp对其进行加速,也可以利用最新的GPU对其进行加速。在本文中我们着重介绍如何利用GPU加速k均值算法,使其可以更快地进行图像分割。要进行图像分割的原始图片如下:
k均值算法
k均值算法是最常用和最简单的聚类算法,原理很简单,但是效果还不错。使用k均值算法进行图像分割通常包含如下步骤:
- 确定k的个数,可以人为指定也可以通过算法确定;
- 选择k个初始的像素点当做最初的类别,可以随机初始化也可以划区域初始化;
- 将每一个像素点和k个类别像素点进行距离计算,将其归入距离最小的类别中;
- 根据3中计算的每一个像素点类别重新计算k个类别的像素值;
- 迭代步骤3和4直到精度足够。
在单次迭代中,步骤3的复杂度为O(nk),其中n为图片大小,k为选择的聚类个数;步骤4的复杂度为O(n+k),所以算法的瓶颈为步骤3。幸运的是,步骤3在计算每个像素点属于哪一类时没有任何依赖性,不同的像素点之间可以并行去做,使其具有极大的加速比。相反,步骤4虽然复杂度低,但是在并行化过程中会遇到极高的写冲突,从而限制了其加速效果。
由于步骤3具有很好的并行性,即使没有GPU我们也可以很方便地通过其他手段进行加速,最容易的就是利用openmp并行化for循环。当计算机的核数很多时,此种方法也可以获得比较明显的收益。由于k均值理解比较容易,我们就不给出串行代码实现了。当k为4时,原始图像分割的效果如下:
可以看出当k等于4时,我们已经能比较清晰的看出原图的轮廓了。
k均值算法的GPU加速
用GPU加速k均值算法也就是加速步骤3和4,步骤3的kernel称为gen_category,步骤4的kernel称为gen_new_anchor。因为简单来说步骤3就是分类,步骤4就是求新类别。先看一下步骤3的kernel:
__global__ void gen_category(pixel* d_in,pixel* d_anchor,unsigned char* d_category,int len,int k){extern __shared__ pixel shared_anchor[];if(threadIdx.x<k){shared_anchor[threadIdx.x]=d_anchor[threadIdx.x];}__syncthreads();int idx=blockDim.x*blockIdx.x+threadIdx.x;if(idx<len){float min_d=9999999.0;for(int i=0;i<k;i++){float d=manhattan_distance(d_in[idx],shared_anchor[i]);if(min_d>d){d_category[idx]=i;min_d=d;}}}}
输入参数d_in表示图片的所有像素,len表示像素的个数,d_anchor表示k个初始聚类像素点,d_category表示执行完毕之后每个像素点的类别。在启动kernel的时候,我们每个block启动1024线程,然后启动足够多的block使其能覆盖所有的像素点,所以在上面的kernel中没有for循环。block内的每个线程执行操作都一样,就是和k个初始聚类点进行距离比较,然后归类。因为k个初始聚类点会被多次访问,为了加速其访问我们将k个聚类点放入共享内存中,由于k不确定所以我们采用动态方式分配共享内存。
相比之下,步骤4的kernel要复杂很多。因为在求新聚类点的操作中,我们面临n个元素要写入k个元素的问题,实际中n远大于k,所以在步骤4中存在非常严重的写冲突,必须要通过原子操作进行串行化,这就大大限制了步骤4的加速能力。kernel如下:
__device__ int count=0;__global__ void gen_new_anchor(pixel* d_in,unsigned char* d_category,pixel* d_anchor,unsigned int* sum_R,unsigned int* sum_G,unsigned int* sum_B,int* total_count,int len,int k){extern __shared__ unsigned int dis_sum[];const int tid=threadIdx.x;__shared__ bool isLast;if(tid<4*k){dis_sum[tid]=0.0;}__syncthreads();int idx=blockDim.x*blockIdx.x+threadIdx.x;if(idx<len){atomicAdd(&dis_sum[d_category[idx]],d_in[idx].R);atomicAdd(&dis_sum[k+d_category[idx]],d_in[idx].G);atomicAdd(&dis_sum[2*k+d_category[idx]],d_in[idx].B);atomicAdd(&dis_sum[3*k+d_category[idx]],1);}__syncthreads();if(tid<k){atomicAdd(&sum_R[tid],dis_sum[tid]);atomicAdd(&sum_G[tid],dis_sum[k+tid]);atomicAdd(&sum_B[tid],dis_sum[2*k+tid]);atomicAdd(&total_count[tid],dis_sum[3*k+tid]);__threadfence();}if(tid==0){int value=atomicAdd(&count,1);isLast=(value==gridDim.x-1);}__syncthreads();if(isLast&&tid<k){d_anchor[tid].R=sum_R[tid]/total_count[tid];d_anchor[tid].G=sum_G[tid]/total_count[tid];d_anchor[tid].B=sum_B[tid]/total_count[tid];if(tid==0) count=0;}}
上述代码和nvidia官方给出的跨block求和有些相似,每个block利用共享内存先部分累加像素值,然后跨block将部分累加像素值再进行累加得到最终的累加像素值,之后让最后一个block求平均值。为了获得最后一个block,我们用原子操作累加一个在全局内存中的计数变量。当然不止获取最后一个block利用了原子操作,上面每个block中的累加和跨block之间的累加都用了原子加来保证正确性。正是由于大量原子操作的存在导致上述kernel的加速比比较低。如果大家觉得上述代码难以理解,我们可以只启动一个block,将涉及跨block之间同步和累加的操作去掉,这样代码就会简化很多,当然性能也会下降不少,不过该步骤不是瓶颈,所以为了正确性简化代码也是可以接受的。简化之后的kernel如下:
//only one block is executed__global__ void gen_new_anchor(pixel* d_in,unsigned char* d_category,pixel* d_anchor,int len,int k){extern __shared__ unsigned int dis_sum[];const int tid=threadIdx.x;if(tid<4*k){dis_sum[tid]=0.0;}__syncthreads();for(int i=tid;i<len;i+=blockDim.x){atomicAdd(&dis_sum[d_category[i]],d_in[i].R);atomicAdd(&dis_sum[k+d_category[i]],d_in[i].G);atomicAdd(&dis_sum[2*k+d_category[i]],d_in[i].B);atomicAdd(&dis_sum[3*k+d_category[i]],1);}__syncthreads();if(tid<k){d_anchor[tid].R=dis_sum[tid]/dis_sum[3*k+tid];d_anchor[tid].G=dis_sum[k+tid]/dis_sum[3*k+tid];d_anchor[tid].B=dis_sum[2*k+tid]/dis_sum[3*k+tid];}}
代码在两款GPU上进行了测试:GTX 860m和Tesla P4,CPU为i5四核,针对不同的聚类个数k,代码运行时间如下: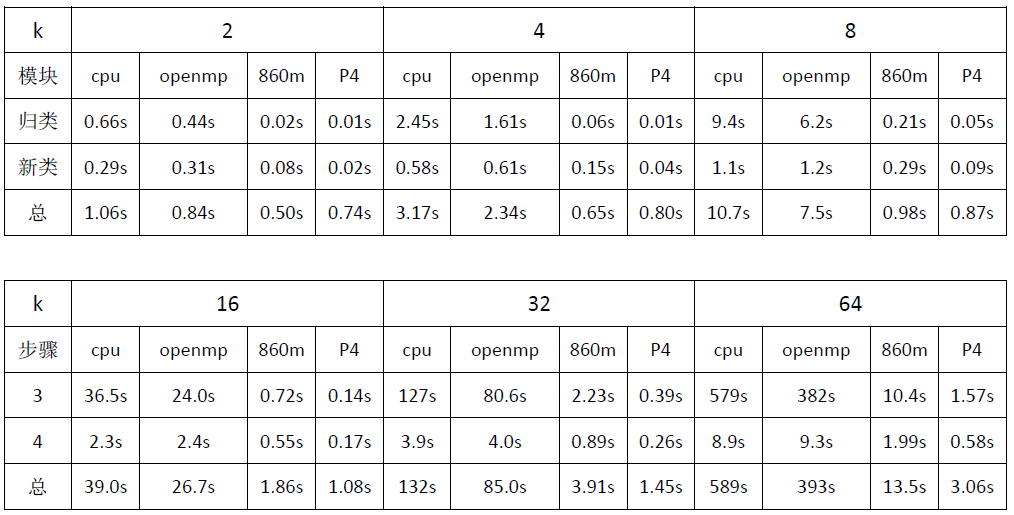
首先可以看出,当在CPU上运行时,随着k的增大,步骤3时间成平方级别增长。这是因为为了让精度更高,我们迭代的次数和k成正比,所以步骤3的时间和k的平方成正比。其次,GTX 860m是14年的老显卡,计算能力5.0,核心个数为640个,相比CPU依旧可以取得明显的加速,而且加速比随着k的增大而增大,当k等于64时,步骤3的加速比大约为57倍,步骤4为4.5倍。Tesla P4是16年的显卡,也算是比较老了,计算能力6.1,核心个数2560。从核心个数上加速比要比GTX 860m快4倍左右,实际上步骤3要大于4倍,步骤4小于4倍。最后,通过简单的openmp也可以加速步骤3,在四核的笔记本上大约有33%左右的加速,核数越多加速越多。
当k为64时,在CPU上大约需要跑10分钟,当k为128时可以预估时间大约为40分钟,k为255时大约为160分钟,这已经远远超过我们能忍受的极限。在P4上,当k为128时,处理时间为6.8s;k为255时,处理时间为28s均在可接受范围内。所以用GPU加速基于k均值的图像分割确实可以获得非常高的加速比。当k为255时,原图进行图像分割的效果如下:
可以看出已经和原图没有太大区别,代码下载:http://www.demodashi.com/demo/15470.html

























(sink端)")
")

使用 Kibana 操作 ES")





还没有评论,来说两句吧...