人脸损失函数的各种变体
人脸损失函数的各种变体都是基于softmax的交叉熵损失函数进行改进的,因此本文首先介绍基础形式,然后对各种变体进行说明。
基于softmax的交叉熵损失函数
先放上两者的基本形式
CE形式,其中
为样本真实分布,
为该样本观察分布
Softmax形式
基于softmax的交叉熵损失函数,就是利用softmax的值替代CE中样本的观察分布,真实分布
为one-hot向量。具体计算过程可参考tf损失函数的参数,其中labels传入样本真实分布,logits值传入softmax计算所需要的
值。
- 人脸其他损失函数变体的由来
针对上述基本形式,真实分布的one-hot向量不会改变,指数和对数计算函数不改变的情况下,影响计算结果的只有标量的值。而
是通过
计算获得的,因此针对向量点乘的公式被拔得体无完肤。总的来说都是利用余弦函数在[0,
]区间单调递减的特性来达到目标的。
- L-Softmax Loss和A-Softmax(SphereFace)
其中
L-Softmax形式
其中
A-Softmax形式
上述两个损失函数主要是针对向量夹角进行的改进,即样本与对应权重间的夹角由变为
,由于当m>1时,
,这样以来当样本与权重在较大夹角情况下满足点乘值最大时,类别的泛化能力更好,另一方面使得类内间距更小,类间间距更大。
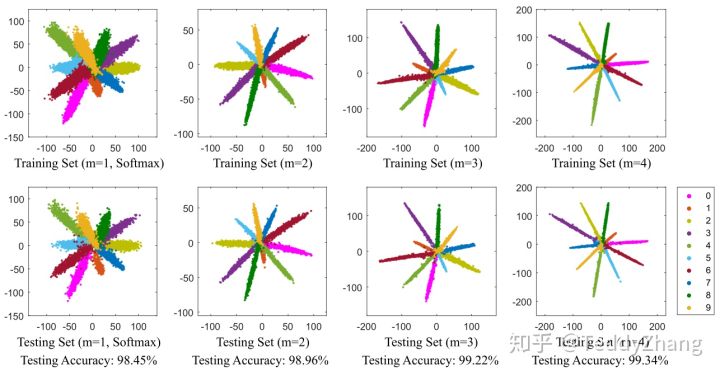 分别基于Softmax和L-Softmax训练后网络特征的可视化
分别基于Softmax和L-Softmax训练后网络特征的可视化
- LMCL(Large Margin Cosine Loss, CosFace)和AM-Softmax Loss
CosFace损失函数,![m\in [0, \frac{c}{c-1})]min _0 _frac_c_c-1
AM-Softmax 损失函数
两篇论文的损失函数都是通过对余弦距离的结果进行的改进,即在原来余弦距离的基础上增加m的冗余。针对余弦距离的修改比针对角度距离的修改后分类效果更佳明显。至于s的由来,可参考论文CosFace中的说法:对得分函数没有贡献,因此将该值使用s进行替代。
- ArcFace
ArcFace的损失函数
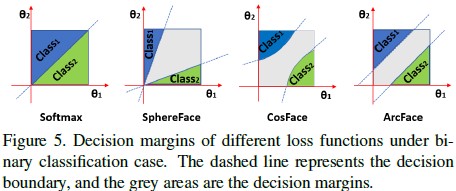
论文对向量夹角进行的改进,不同于L-Softmax和A-Softmax成倍增加夹角的是该损失函数在原夹角基础上增加m的冗余。下图直观的反映了不同损失函数的夹角对决策面的影响。
参考文献:
- 人脸识别:损失函数总结
- 人脸识别损失函数简介与Pytorch实现:ArcFace、SphereFace、CosFace





























的笨方法以及由此产生的String类型陷阱再复习")




还没有评论,来说两句吧...