Hibernate04-HQL连接查询和Hibernate注解
一、使用HQL连接查询
和SQL查询一样,HQL也支持多种连接查询,如内连接查询、外连接查询。在SQL中可通过join子句实现多表之间的连接查询。HQL同样提供了连接查询机制,还允许显式指定迫切内连接和迫切左外连接。迫切连接是指不仅指定了连接查询方式,而且显式的指定了关联级别的查询策略。迫切连接使用fetch关键字实现,fetch关键字表明“左边”对象用来与“右边”对象关联的属性会立即被初始化。
HQL常用连接类型:
- 内连接:inner join 或 join
- 迫切内连接:inner join fetch 或join fetch
- 左外连接:left outer join或left join
- 迫切左外连接:left outer join fetch 或left join fetch
- 右外连接:right outer join或right join
适用范围: 适用于有关联关系的持久化类,并且在映射文件中对这种关联关系做了映射。
1、内连接
语法:
from Entity [inner] join [fetch] Entity.property;
【范例1】
/*** 使用内连接:查询部门和员工的信息*/@Testpublic void testListAllEmpAndDept(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Object[]> list=HibernateUtil.currentSession().createQuery("from Dept d inner join d.emps").list(); //inner可以省略for (Object[] obj:list){System.out.println(obj[0]+"\t"+obj[1]);}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果如下: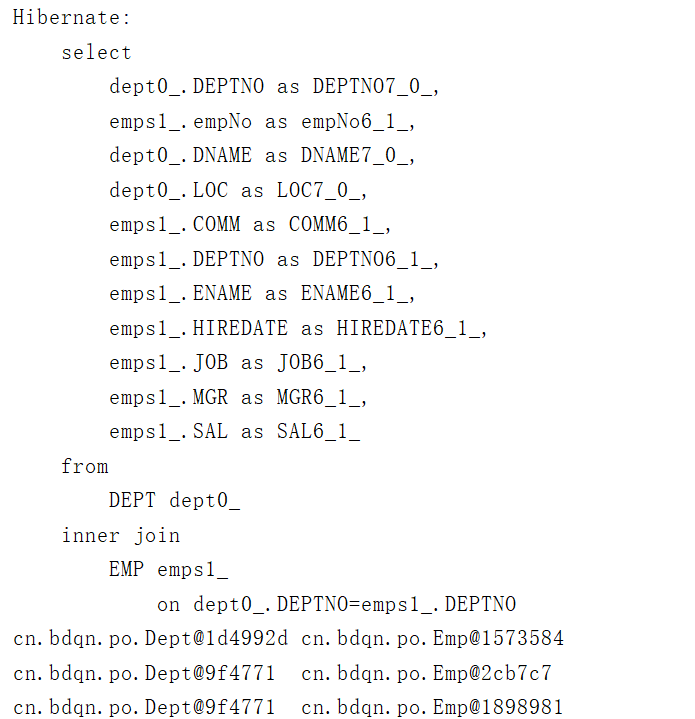
说明: list集合中的每个元素都是一个Object数组,数组的第一个元素是Dept对象,第二个元素是Emp对象,Dept对象的emps集合元素没有被初始化,即emps集合没有存放关联的Emp对象。
【范例2:迫切内连接】
/*** 使用迫切内连接:查询部门和员工的信息*/@Testpublic void testListAllEmpAndDept2(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d inner join fetch d.emps").list(); //inner可以省略for (Dept d:list){System.out.println(d.getdName()+"\n\t"+d.getEmps());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果: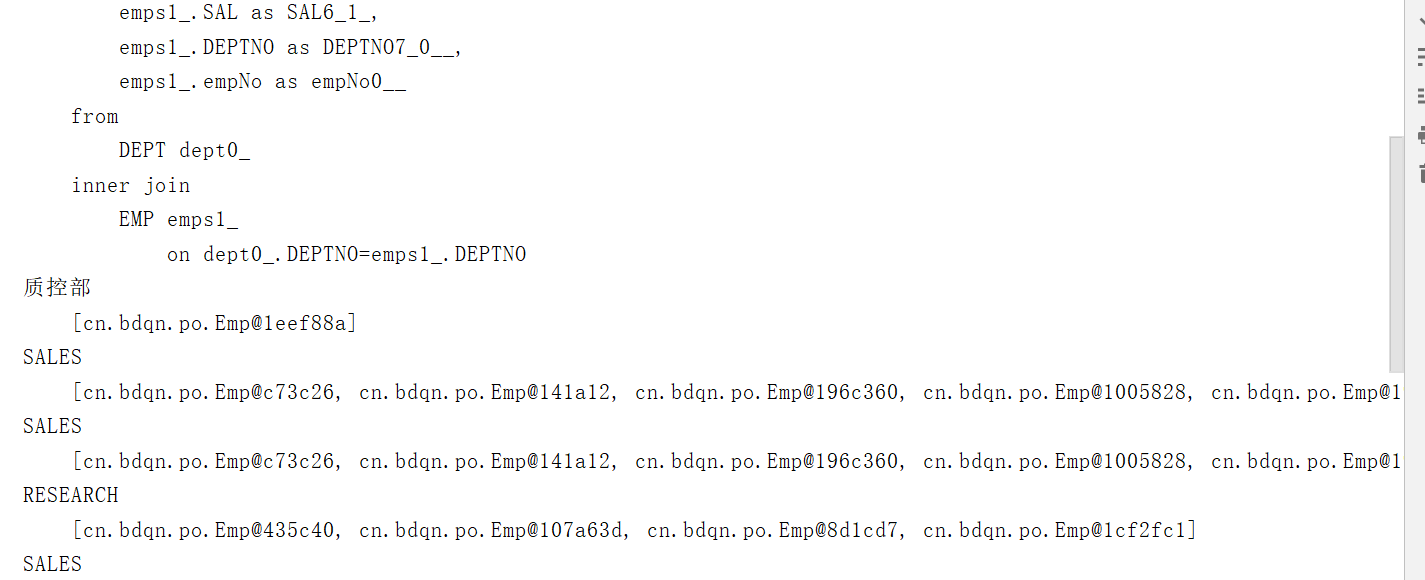
说明: 以上demo中,list集合中的每个元素都是Dept对象,Hibernate使用fetch关键字实现了将Emp对象读出来后立即填充到对应的Dept对象的集合属性中。
2、外连接
(1)Hibernate的左外连接语法如下,fetch关键字用来指定查询策略:
from Entity left [outer] join [fetch] Entity.property
【范例1:使用左外连接】
/*** 使用左外连接:查询部门和员工的信息*/@Testpublic void testListAllEmpAndDept3(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d left join fetch d.emps").list(); //inner可以省略for (Dept d:list){System.out.println(d.getdName()+"\n\t"+d.getEmps());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果: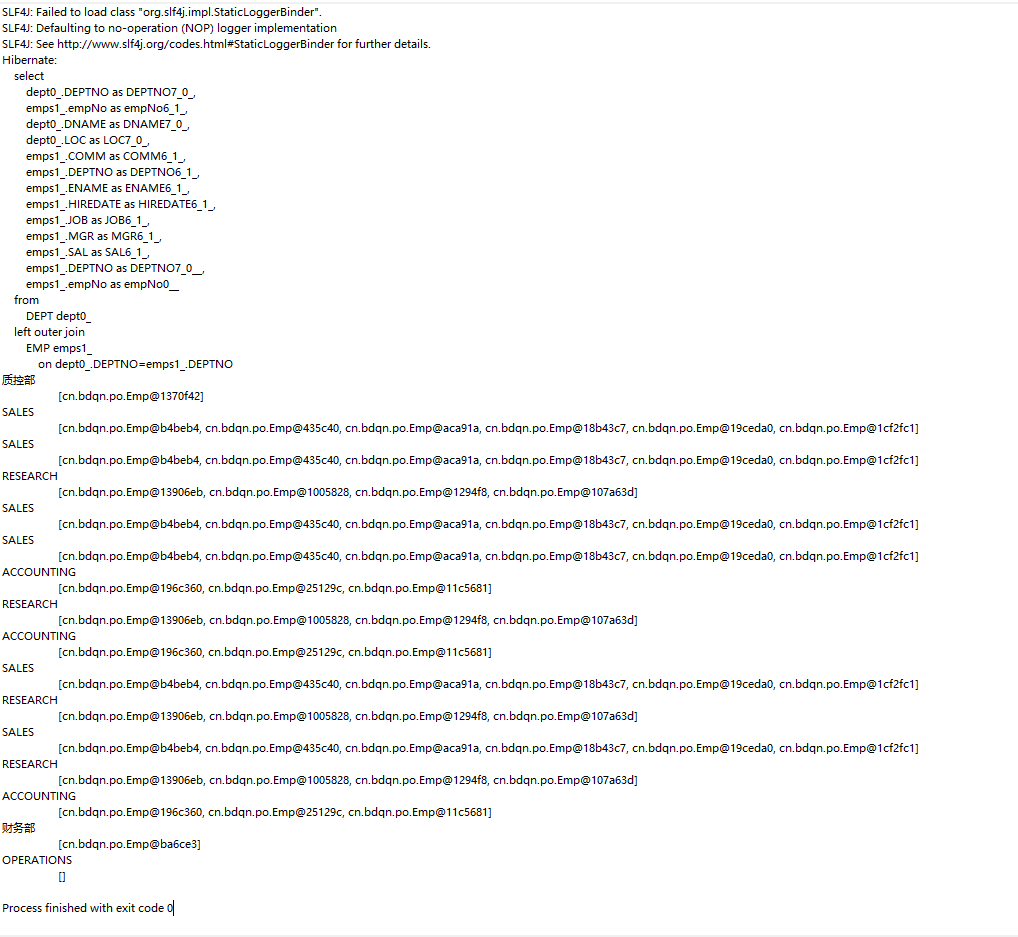
(2)右连接语法如下:
from Entity right [outer] join Entity.property
注: fetch关键字只对inner join和left outer join有效。对于right outer join而言,由于作为关联对象容器的“左边”对象可能为null,所以也就无法通过fetch关键字强制Hibernate进行集合填充操作。
3、等值连接
HQL支持SQL风格的等值连接查询。等值连接适用于两个类之间没有定义任何关联时,如统计报表数据。在where子句中,通过属性作为筛选条件,其语法如下:
from Dept d,Emp e where d=e.dept
使用等值连接时应避免”from Dept,Emp”这样的语句出现。执行这条HQL查询语句,将返回DEPT表和EMP表的交叉组合,结果集的记录数为两个表的记录数之积,也就是数据库中的笛卡尔积。
4、隐式内连接
在HQL查询语句中,对Emp类可以通过dept.dName的形式访问其关联的dept对象的dName属性。使用隐式内连接按部门条件查询员工信息。
【范例1:使用隐式内连接】
/*** 使用隐式内连接:根据部门条件查询员工信息*/@Testpublic void testListAllEmpAndDept4(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Emp> list=HibernateUtil.currentSession().createQuery("from Emp e where e.dept.dName=?").setString(0,"SALES").list();for (Emp emp:list){System.out.println("部门名称:"+emp.getEname());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果:
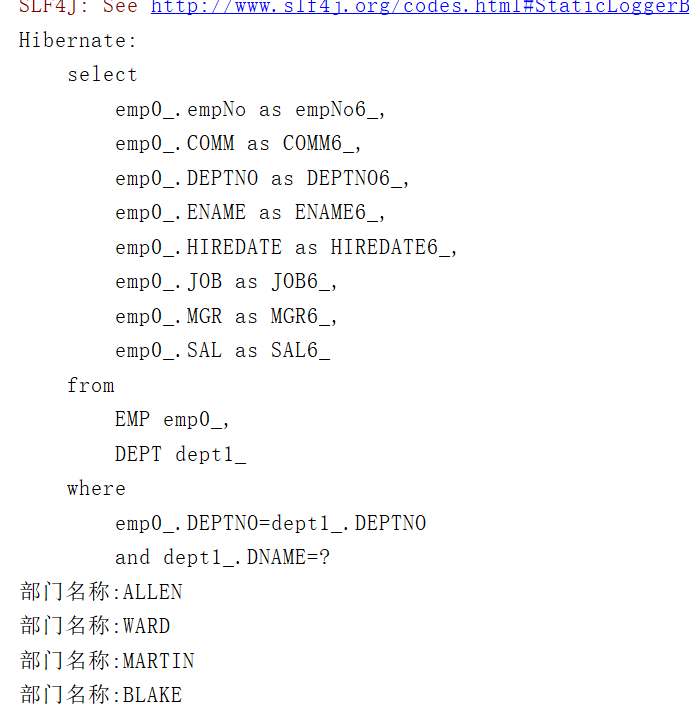
说明: 上面方法中的HQL语句未使用任何连接的语法,而Hibernate会根据类型间的关联关系,自动使用等值连接(等效于内连接)的方式实现查询。隐式内连接使得编写HQL语句时能够以更加面向对象的方式进行思考,更多的依据对象之间的关系,而不必过多考虑数据库表的结构。
隐式内连接也可以用在select子句中,例如:
select e.empName,e.dept.dName from Emp e
二、分组进行数据统计
HQL和SQL一样,使用group by关键字对数据分组,使用having关键字对分组数据设定约束条件,从而完成对数据分组和统计。基本语法如下:
[select ...] from ... [where ...] [group by...[having...] ] [order by...]
1、HQL查询语句中常用的聚合函数
(1)count():统计记录条数
//查询DEPT表中所有记录条数Long count=(Long)session.createQuery("select count(id) from Dept").uniqueResult();
(2)sum():求和
//计算所有员工应发的工资总和Double salarySum=(Double)session.createQuery("select sum(salary) from Emp").uniqueResult();
(3)min():求最小值
//员工的最低工资是多少Double salarySum=(Double)session.createQuery("select min(salary) from Emp").uniqueResult();
(4)max():求最大值
//员工的最高工资是多少Double salarySum=(Double)session.createQuery("select max(salary) from Emp").uniqueResult();
(5)avg():求平均值
//员工的平均工资是多少Double salarySum=(Double)session.createQuery("select avg(salary) from Emp").uniqueResult();
(6)HQL查询语句很灵活, 它提供了几乎所有SQL常用的功能,可以利用select子句同时查询出多个聚合函数的结果,如下:
Object[] salarys=(Object[] salarys)session.createQuery("select min(salary),max(salary),avg(salary) from Emp").uniqueResult();System.out.println(salarys[0]+","+salarys[1]+","+salarys[2]);
注: 因为选取多个对象,所以uniqueResult()方法返回的是一个Object数组。
补充: HQL查询语句可以返回各种类型的查询结果。当不能确定查询结果的类型时,可以使用以下方法来确定查询结果类型:
Object count=session.createQuery("select count(distinct job) from Emp").uniqueResult();System.out.println(count.getClass().getName());
说明: count.getClass().getName()显示查询结果类型为java.lang.Long。
2、编写HQL分组查询语句
HQL查询语句使用group by 子句进行分组查询,使用having子句筛选分组结果。
(1)按职位统计员工个数
/*** 按职位统计员工个数*/@Testpublic void testCountByJob(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Object[]> list=HibernateUtil.currentSession().createQuery("select e.job,count(e) from Emp e group by e.job").list();for (Object[] obj:list){System.out.println(obj[0]+","+obj[1]);}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果: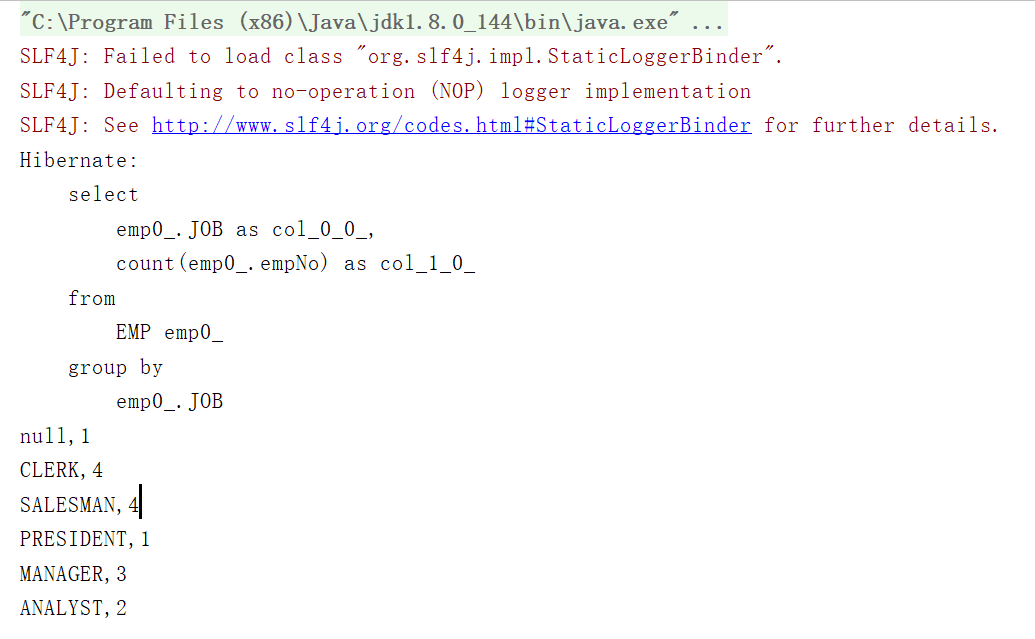
说明: Query接口的list()方法返回的集合中包含Object[] 类型的元素,每个Object[]对应查询结果中的一条记录,数组的第一个元素是职位名称,第二个元素是该职位的员工人数。
(2)统计各个部门的平均工资
/*** 统计各个部门的平均工资*/@Testpublic void testAvgSalaryByDept(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Object[]> list=HibernateUtil.currentSession().createQuery("select e.dept.dName,avg(e.sal) from Emp e group by e.dept.dName").list();for(Object[] obj:list){System.out.println(obj[0]+","+obj[1]);}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果: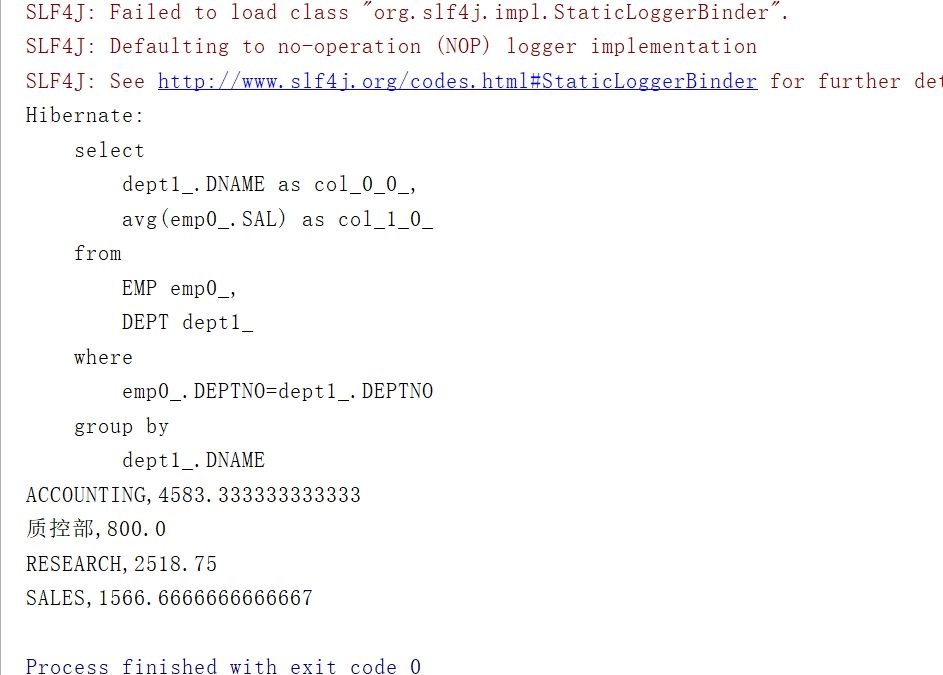
说明: Query接口的list()方法返回的集合中包含Object[]类型的元素,每个Object[]对应查询结果中的一条记录,数据中的第一个元素是部门名称,第二个元素是该部门员工的平均工资。
(3)统计各个职位的最低工资和最高工资
/*** 统计各个职位的最低工资和最高工资*/@Testpublic void testMaxAndMinSalByJob(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Object[]> list=HibernateUtil.currentSession().createQuery("select e.job,min(e.sal),max(e.sal) from Emp e group by e.job").list();for(Object[] obj:list){System.out.println(obj[0]+","+obj[1]+","+obj[2]);}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果: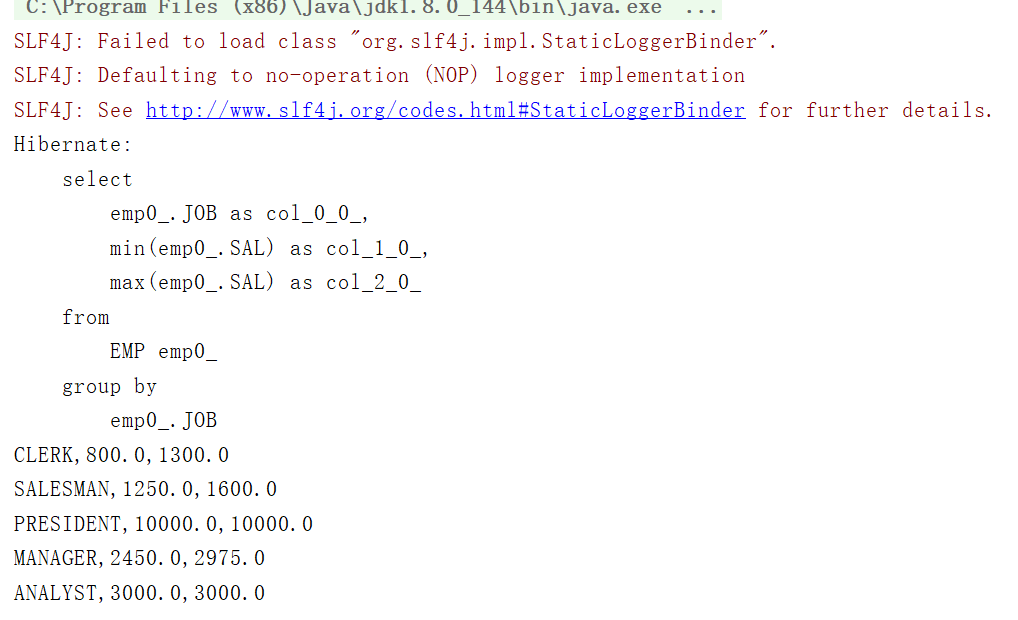
说明: Query接口的list()方法返回的集合中包含Object[]类型的元素,每个Object[]对应查询结果中的一条记录,数组的第一个元素是职位名称,第二个元素是该职位员工的最低工资,第三个元素是该职位员工的最高工资。
(4)统计平均工资>4000元的部门名称
/*** 统计平均工资>4000元的部门名称,输出部门名称,部门平均工资*/@Testpublic void testGetAvgByCondition(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Object[]> list=HibernateUtil.currentSession().createQuery("select e.dept.dName,avg(e.sal)from Emp e"+" group by e.dept.dName having avg(e.sal)>4000").list();for(Object[] obj:list){System.out.println(obj[0]+","+obj[1]);}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果:
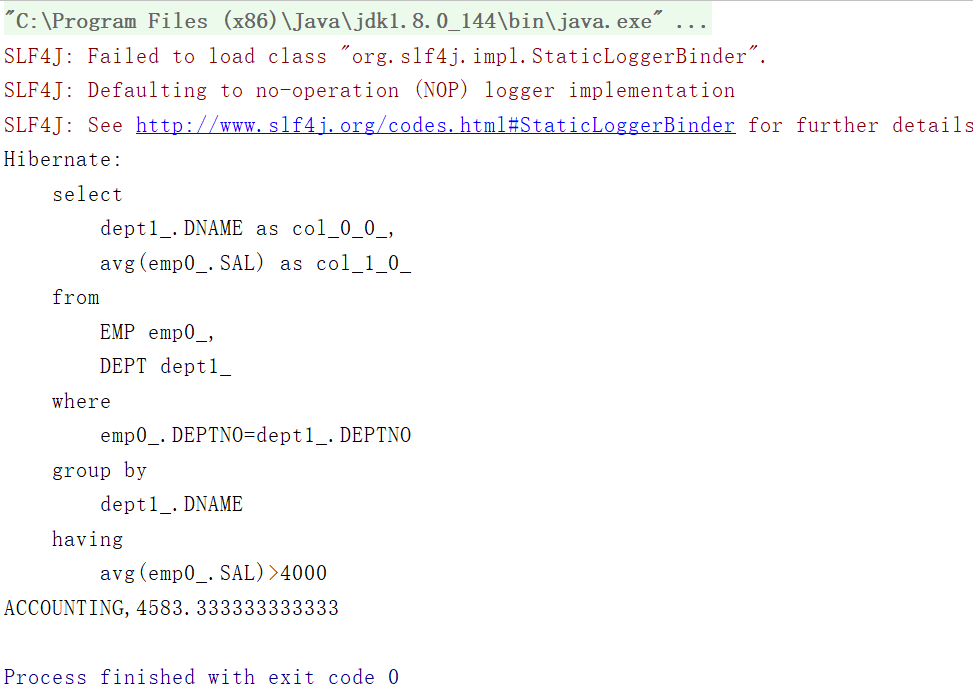
说明: having子句用于筛选分组结果。Query接口的list()方法返回的集合中包含Object[]类型的元素,每个Object[]对应查询结果中的一条记录,数组的第一个元素是部门名称,第二个元素是该部门员工的平均工资。
补充: 使用select子句时,Hibernate返回的查询结果为关系数据而不是持久化对象,不会占用Session缓存。为了方便访问,可以定义一个JavaBean来封装查询结果中的关系数据,使应用程序可以按照面向对象的方式来访问查询结果。代码如下:
/*** 统计平均工资>4000元的部门名称,输出部门名称,部门平均工资*/@Testpublic void testGetAvgByCondition2(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<DeptSalary> list=HibernateUtil.currentSession().createQuery("select new cn.demo.po.DeptSalary("+"e.dept.dName,avg(e.sal))"+"from Emp e group by e.dept.dName having avg(e.sal)>4000").list();for(DeptSalary deptSalary:list){System.out.println(deptSalary.getdName()+","+deptSalary.getSalary());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
说明: 其中DeptSalary不是持久化类,它的实例不会被加入Session缓存。DeptSalary类中需要有一个带参的构造方法:
public DeptSalary(String dName, Double salary) {this.dName = dName;this.salary = salary;}
三、使用子查询
1、使用子查询关键字进行查询结果量化
如果子查询语句返回多条记录,可以使用以下关键字进行量化:
- all:子查询语句返回的所有记录
- any:子查询语句返回的任意一条记录
- some: 与“any”意思相同
- in:与“=any”意思相同
- exists:子查询语句至少返回一条记录
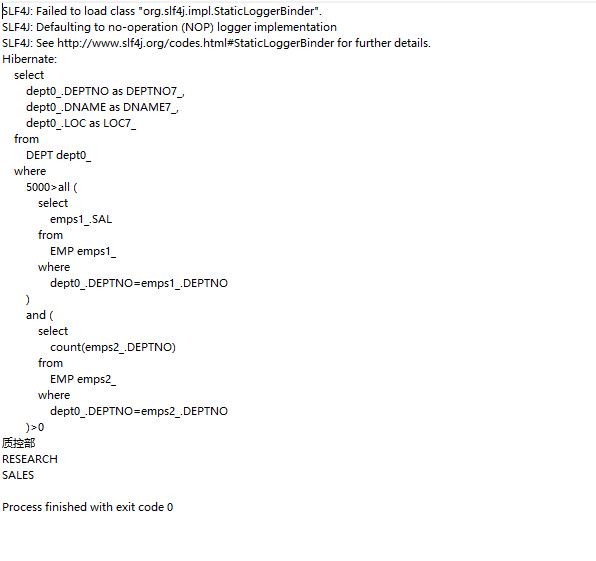
(1)查询所有员工工资都<5000元的部门
/*** 测试使用子查询all:查询所有员工工资都小于<5000元的部门*/@Testpublic void testGetAllDeptBySalary(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d where 5000>all(select e.sal from d.emps e)").list();for (Dept dept:list){System.out.println(dept.getdName());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果:
(2)查询至少有一位员工的工资低于5000元的部门
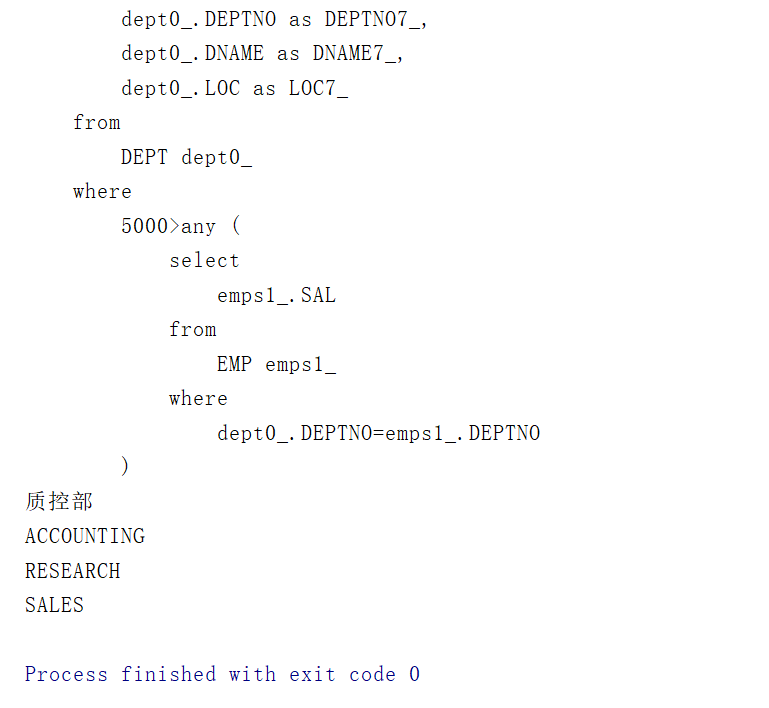
/*** 测试使用子查询any:至少有一位员工的工资小于<5000元的部门*/@Testpublic void testGetAnyDeptBySalary(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d where 5000>any(select e.sal from d.emps e)").list();for (Dept dept:list){System.out.println(dept.getdName());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果
(3)查询有员工工资正好是5000元的部门
/*** 测试使用子查询 =any:查询有员工工资正好是5000元的部门*/@Testpublic void testGetSomeDeptBySalary(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d where 5000=any(select e.sal from d.emps e)").list();for (Dept dept:list){System.out.println(dept.getdName());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
补充: 这条HQL查询语句也可以采用以下两种形式
from Dept d where 5000=some(select e.sal from d.emps e)
或
from Dept d where 5000 in(select e.sal from d.emps e)
(4)查询至少有一位员工的部门
/*** 测试使用子查询 exists关键字:查询至少有一位员工的部门*/@Testpublic void testGetDeptByExists(){Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d where exists(from d.emps)").list();for (Dept dept:list){System.out.println(dept.getdName());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果

2、操作集合的函数或属性
HQL提供操作集合的函数或属性如下:
- size()或size:获取集合中元素的数目。
- minIndex()或minIndex:对于建立了索引的集合,获得最小的索引。
- maxIndex()或maxIndex:对于建立了索引的集合,获得最大的索引。
- minElement()或minElment:对于包含基本类型元素的集合,获得集合中取值最小的元素。
- maxElement()或maxElment:对于包含基本类型元素的集合,获得集合中取值最大的元素。
- elements():获取集合中的所有元素。
(1)查询指定员工所在部门
/*** 使用elements函数:查询指定员工所在部门*/@Testpublic void testGetDeptByEmp(){//构造查询条件Emp emp=new Emp();emp.setEmpNo(7369);Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d where ? in elements(d.emps) ").setParameter(0,emp).list();for (Dept dept:list){System.out.println(dept.getdName());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果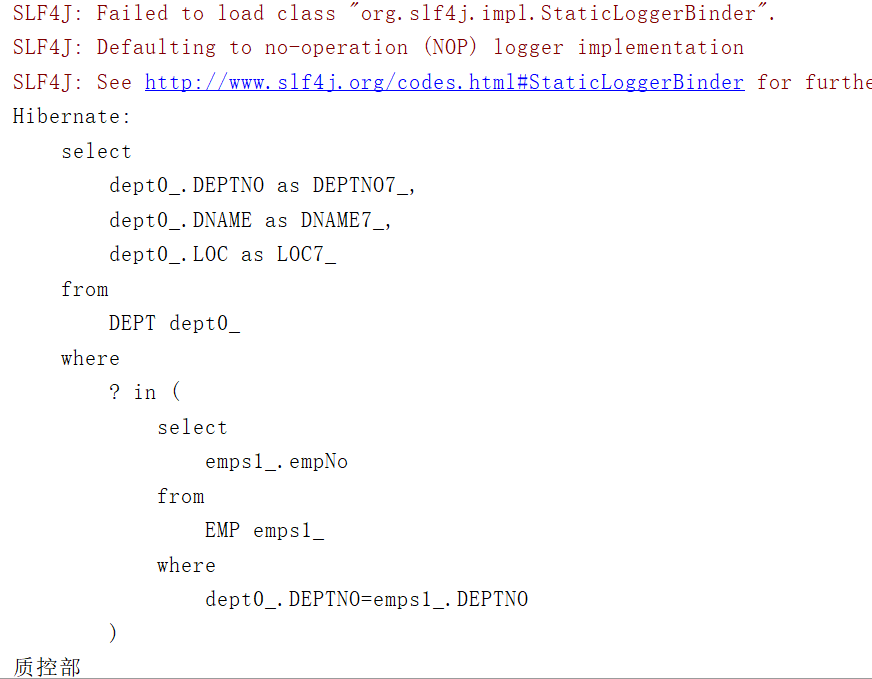
(2)查询员工人数>5的部门
/*** 使用size属性:查询员工人数>5人的部门*/@Testpublic void testGetCountByEmp(){//构造查询条件Emp emp=new Emp();emp.setEmpNo(7369);Transaction tx=null;try {tx= HibernateUtil.currentSession().beginTransaction();List<Dept> list=HibernateUtil.currentSession().createQuery("from Dept d where d.emps.size>5 ").list();for (Dept dept:list){System.out.println(dept.getdName());}tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}
运行结果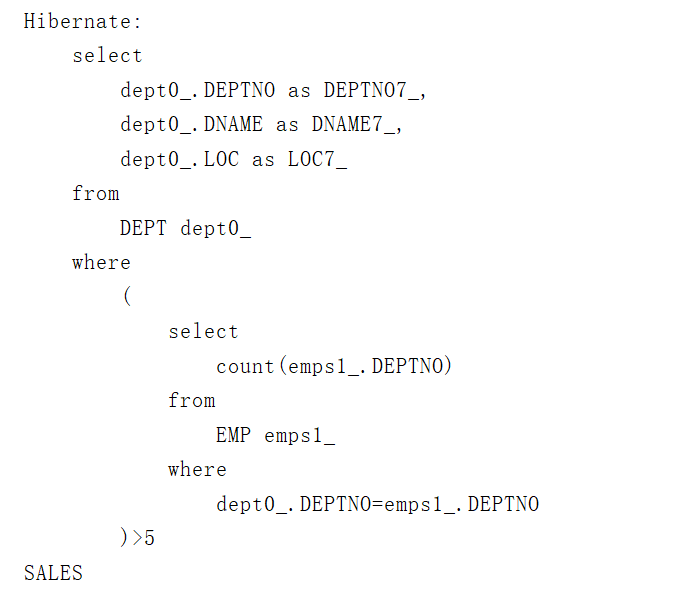
这条HQL查询语句也可以采用以下形式:
from Dept d where size(d.emps)>5
四、优化查询性能
1、Hibernate查询优化策略
- (1)使用迫切左外连接或迫切内连接查询策略、配置二级缓存和查询缓存等方式,减少select语句的数目,降低访问访问数据库的频率。
- (2)使用延迟加载等方式避免加载多余的不需要访问的数据。
- (3)使用Query接口的iterate()方法减少select语句中的字段,减少访问数据库的数据量,并结合缓存等机制减少数据库访问次数,提高查询效率。
补充:Query接口的list()方法和iterate()方法都可以执行查询,而iterate()方法能够利用延迟加载和缓存的机制提高查询性能。iterate()方法执行时仅查询ID资源以节省资源,需要使用数据时再根据ID字段到缓存中检索匹配的实例,如果存在就直接使用,只有当缓存中没有所需的数据时,iterate()方法才会执行select语句根据ID字段到数据库中查询。iterate()方法更适用于查询对象开启二级缓存的情况。
2、HQL优化
HQL优化是Hibernate程序性能优化的一个方面,HQL的语法与SQL非常类似。HQL是基于SQL的,只是增加了面向对象的封装。如果抛开HQL同Hibernate本身一些缓存机制的关联,HQL的优化技巧同SQL的优化技巧一样。在编写HQL时,需注意以下几个原则:
(1)避免or操作的使用不当。如果where子句中有多个条件,并且其中某个条件没有索引,使用or将导致全表扫描。假定在House表中title字段有索引,price字段没有索引,执行以下HQL语句:
from House where title=’出租一居室’ or price<1500
当比较price时,会引起全表扫描
(2)避免使用not。 如果where子句的条件包含not关键字,那么执行该字段的索引失效。这些语句需要分成不同情况区别对待,如查询租金不多于1800元的租房信息的HQL语句为:
from House as h where not(h.price>1800)
对于这种不大于(不多于)、不小于(不少于)的条件,建议使用比较运算符来替代not,如不大于就是<=,所以上述查询的HQL语句也可以为:
from House as h where h.price<=1800
- (3)避免like的特殊形式。 某些情况下,会在where子句中使用like。如果like以一个”%“或”_“开始,则该字段的索引不起作用。但是对于这种问题并没有较好的解决方法,只能通过改变索引字段的形式变相的解决。
- (4)避免使用having子句。 在分组的查询语句中,可在两个位置指定条件,一是在where子句中,二是在having子句中。要尽可能的在where子句中而不是having子句中指定条件。因为having是在检索出所有记录后才对结果集进行过滤的,这个处理需要一定的开销,而where子句限制记录数目,能减少这方面的开销。
- (5)避免使用distinct。 指定distinct会导致在结果中删除重复的行,这会对处理时间造成一定的影响,因此在不要求或允许冗余时,应避免使用distinct。
(6)索引在以下情况下失效,使用时应注意:
- 对字段使用函数,该字段的索引将不起作用,如substring(aa,1,2)=‘XX’
- 对字段进行计算,该字段的索引将不起作用,如price+10
五、使用注解配置持久化类和关联关系
1、认识Hibernate注解
Hibernate提供了注解来进行对象–关系映射,它可以代替大量的hbm.xml文件,
使得Hibernate程序的文件数量大大精简。使用注解,可以直接将映射信息定义在持久化类中,而无需编写对应的 *.hbm.xml文件。
使用Hibernate注解的步骤如下:
- 使用注解配置持久化类及对象关联关系
在Hibernate配置文件(hibernate.cfg.xml)中声明持久化类,语法如下:
2、使用Hibernate注解配置持久化类
配置持久化类的常用注解如下:
- @Entity:将一个类声明为一个持久化类
- @Table:为持久化类映射指定表(table)、目录(catalog)和schema的名称。
默认值:持久化类名,不带包名 - @Id:声明了持久化类的标识属性(相当于数据表的主键)
- @GeneratedValue:定义标识属性值的生成策略
- @UniqueConstraint:定义表的唯一约束
- @Lob:表示属性将被持久化为Blob或者Clob类型
- @Column:将属性映射到数据库字段
- @Transient:指定可以忽略的属性,不用持久化到数据库
注:使用Hibernate注解,需要导入javax.persistence包,常用注解都存放在这个包中。javax.persistence包是JPA ORM规范的组成部分。JPA全称Java Persistence API,它通过JDK5.0注解或XML描述对象–关系表的映射关系,并将运行时对象持久化到数据库中。Hibernate提供了对JPA的实现。
【例1】
Emp.java
/*** 员工类*/@Entity //标识是一个持久化类@Table(name="EMP") //对应的数据库表名为EMPpublic class Emp {/*** 员工编号*/@Id //标识为注解//标识主键生成策略为序列@GeneratedValue(strategy = GenerationType.SEQUENCE,generator = "seq_emp")@SequenceGenerator(name="seq_emp",sequenceName = "seq_emp_id",allocationSize=10,initialValue = 1)private Integer empNo;/*** 员工姓名*/@Column(name="ENAME") //标识数据库中该属性所对应的字段private String ename;/*** 员工职位*/@Column(name="JOB")private String job;/*** 上级编号*/@Column(name="MGR")private Integer mgr;/*** 入职日期*/@Column(name="HIREDATE")private Date hiredate;/*** 工资*/@Column(name="SAL")private Double sal;/*** 福利*/@Column(name="COMM")private Double comm;/*** 所属部门*/@Transient //指定无需持久化到数据库private Dept dept;//省略getter/setter}
hibernate.cfg.xml配置:
<mapping class="cn.demo.po.Emp"/>
说明:
(1)上面demo将Emp类映射到EMP表,empNo属性为OID,主键采用序列生成,需在数据库中创建名为seq_emp_id的序列。注解可以放置在属性定义的上方,或者getter方法的上方。
(2)@Table可以省略,省略时默认表名与持久化类名相同。
(3)@GeneratedValue指定了OID的生成策略,不使用此注解时,默认OID由程序赋值,相当于在映射文件中指定assigned。JPA提供了4种标准用法。
- AUTO:根据不同的数据库选择不同的策略,相当于Hibernate中的native。
- TABLE:使用表保存id值
- IDENTITY:使用数据库自动生成主键值(主要是自动增长型,如MySql、SQLServer)
- SEQUENCE:使用序列生成主键值(如Oracle),generator=”seq_emp”指定了生成器为seq_emp。
(4)@SequenceGenerator设置了序列生成器,name=”seq_emp”定义了序列生成器为seq_emp;sequenceName=”se q_emp_id”指定了序列的名称为seq_emp_id;initialValue设置了主键起始值;allocationSize设置了生成器分配id时的增量。
(5)@Column用于指定属性映射的数据库字段名,若不指定,则默认字段名和属性名相同。
(6)@Transient用于忽略不需要持久化到数据库中的属性。
3、使用Hibernate注解配置关联关系
对象关联关系的常用注解如下:
- @OneToOne:建立持久化类之间的一对一关联关系
- @OntToMany:建立持久化类之间的一对多关联关系
- @ManyToOne:建立持久化类之间的多对一关联关系
- @ManyToMany:建立持久化类之间的多对多关联关系
【范例】
Emp.java 为Dept属性添加注解,其他不做更改
/*** 所属部门*/// @Transient //指定无需持久化到数据库@ManyToOne(fetch = FetchType.LAZY)@JoinColumn(name="DEPTNO")private Dept dept;public Dept getDept() {return dept;}public void setDept(Dept dept) {this.dept = dept;}//省略其他属性
Dept.java
/*** 部门表*/@Entity@Table(name="DEPT")public class Dept implements Serializable {/*** 部门编号*/@Id@Column(name="DEPTNO")private Integer deptNo;/*** 部门名称*/@Column(name="DNAME")private String dName;/*** 部门地区*/@Column(name="LOC")private String loc;@OneToMany(mappedBy = "dept",cascade = {CascadeType.ALL})private Set<Emp> emps=new HashSet<Emp>(); //部门下所包含的员工public Set<Emp> getEmps() {return emps;}public void setEmps(Set<Emp> emps) {this.emps = emps;}}
hibernate.cfg.xml配置:
<mapping class="cn.demo.po.Dept"/>
说明:
(1)上面代码中使用@ManyToOne注解配置了Emp类和Dept类之间的多对一关联。注解属性fetch=FetchType.LAZY设置关联级别采用延迟加载策略;若不指定,改属性默认值是EAGER,查询Emp时,Hibernate将使用左外连接将相关Dept对象一并查出。注解JoinColumn(name=“DEPTNO”)指定了维护关系的外键字段是EMP表中的DEPTNO。
(2)注解@OneToMany配置了Dept类和Emp类之间的一对多关系。属性mappedBy=”dept”将关联关系的控制权交给Emp类这一方,相当于Dept.hbm.xml中配置的inverse=“true”。mappedBy属性的值是Emp类中与Dept类相关联的属性名。属性cascade={CascadeType.ALL}设置了级联操作的类型,可选的取值如下,以下取值在使用中可以多选,多选时用逗号隔开:
- CascadeType.REMOVE:级联删除
- CascadeType.PERSIST:persist()方法级联
- CascadeType.MERGE:级联更新
- CascadeType.REFRESH:级联刷新
- CascadeType.ALL:包含所有级联操作
(3)到现在使用注解的方式已经配置完成,可以编写一个添加方法进行测试
DeptDao.java
public class DeptDao{/*** 新增部门信息* @param dept*/public void save(Dept dept){this.currentSession().save(dept); //保存指定的Dept对象}}
DeptBiz.java
public class DeptBiz {private DeptDao deptDao=new DeptDao();/*** 新增部门* @param dept*/public void addNewDept(Dept dept){Transaction tx=null;try {tx=deptDao.currentSession().beginTransaction(); //开启事务deptDao.save(dept);tx.commit();}catch (HibernateException e){e.printStackTrace();if(tx!=null){tx.rollback();}}}}
测试类
/*** 添加Dept对象的同时对相关联的Emp对象进行持久化操作*/@Testpublic void testAddNewDept(){//创建一个Dept对象和一个Emp对象Dept dept=new Dept(22,"财务部","东部");Emp emp=new Emp();emp.setEname("王五");//建立Dept对象与Emp对象的双向关联关系emp.setDept(dept);dept.getEmps().add(emp);//保存Dept对象new DeptBiz().addNewDept(dept);}
运行结果如下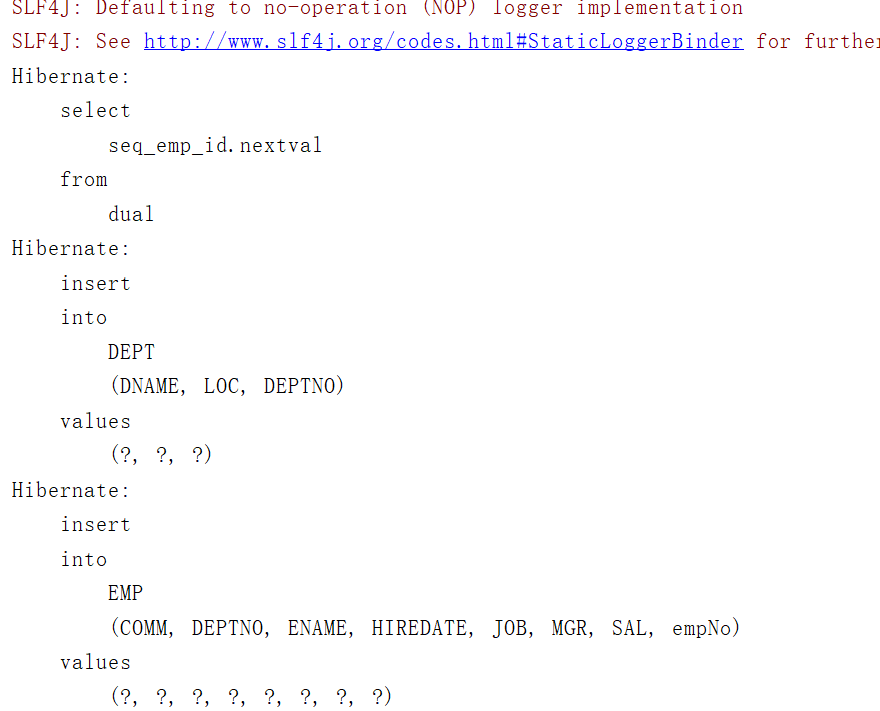
关注微信公众号【程序媛琬淇】,专注分享Java干货,给你意想不到的收获。


























Oracle中用Exp命令导出指定用户下的所有表的前N行数据,并用imp数据导入到本地数据库中--修改编码")








还没有评论,来说两句吧...