分布式文件存储系统HDFS 05
1.分布式文件系统详细介绍
在hadoop当中,分布式文件系统(HDFS),对文件系统有一个抽象,HDFS属于当中的一个实现类,也就是说分布式文件系统类似于一个接口,定义了标准,下面有很多的实现类,其中HDFS是一个子实现类而已,但是现在很多人都只知道一种就是HDFS的实现,并没有了解过其他的实现类,其实分布式文件系统的实现有很多种,
具体详细参见hadoop权威指南第三版第59页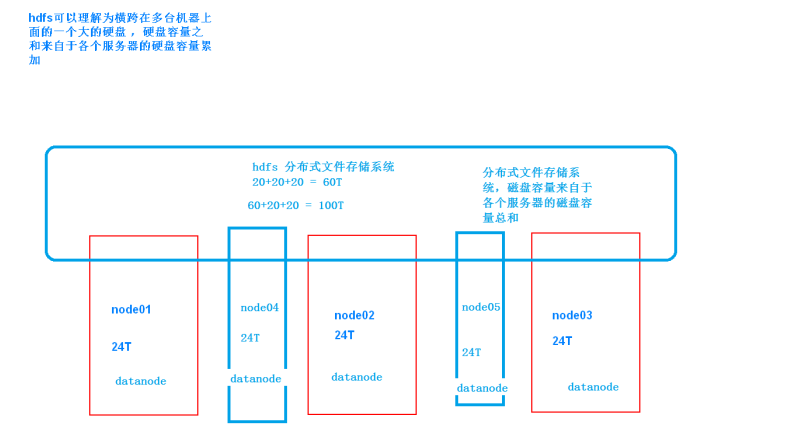
2. HDFS分布式文件系统设计目标
1、硬件错误 由于集群很多时候由数量众多的廉价机组成,使得硬件错误成为常态
2、数据流访问 所有应用以流的方式访问数据,设置之初便是为了用于批量的处理数据,而不是低延时的实时交互处理
3、大数据集 典型的HDFS集群上面的一个文件是以G或者T数量级的,支持一个集群当中的文件数量达到千万数量级
4、简单的相关模型 假定文件是一次写入,多次读取的操作
5、移动计算比移动数据便宜 一个应用请求的计算,离它操作的数据越近,就越高效
6、多种软硬件的可移植性
3. HDFS的来源
- HDFS起源于Google的GFS论文(GFS,Mapreduce,BigTable为google的旧的三驾马车)
- 发表于2003年10月
HDFS是GFS的克隆版
Hadoop Distributed File system
易于扩展的分布式文件系统
运行在大量普通廉价机器上,提供容错机制
为大量用户提供性能不错的文件存取服务
4. HDFS分块原理
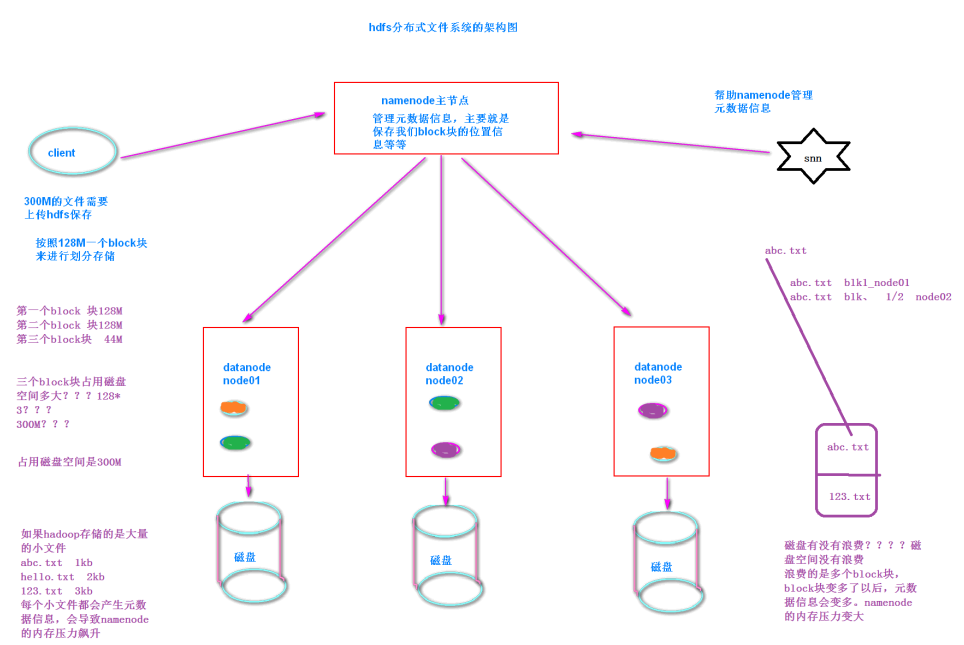
- 一个block 默认128M, 3个副本 hdfs-site.xml进行设置
- 小文件会占用元数据内存,但不会占用磁盘空间
- hdfs写入数据时, packet 64KB 会有acs检查机制 使用UDP协议
假设数据1G, 需要准备13倍的内存(至少准备13倍)
- flume数据先采集过来 3倍
- 清洗非结构化数据–>结构化数据 6倍
- ods 构建外部表, 会将flume数据采集的位置剪切到对应的hive文件夹下面–> 不重新占内存
- dw —> 会映射过来(3份), 9倍
- app —> 会映射过来(3份), 12倍
- mr程序,会产生中间数据(1份), 13倍
5. 元数据管理
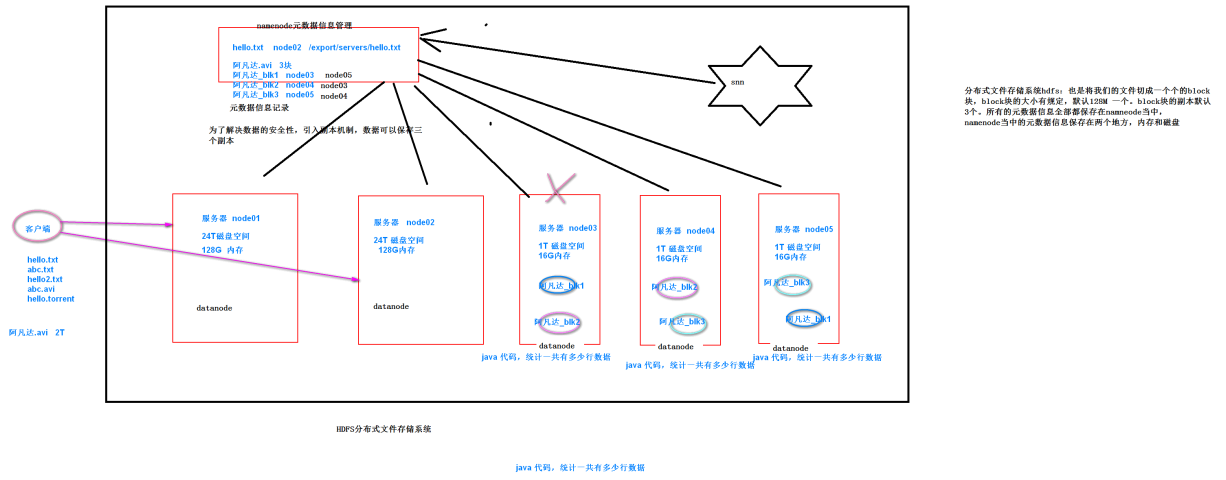
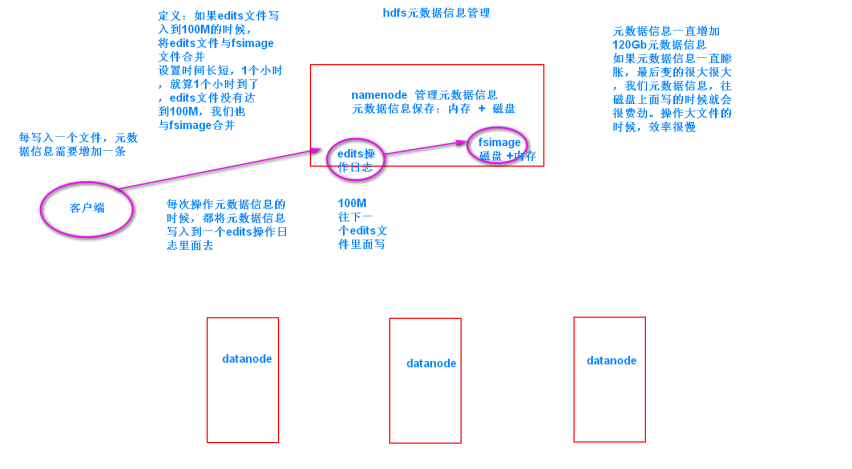
- Fsimage:存放的是一份比较完整的元数据信息
- Edits:存放的是最近一段时间的元数据信息的操作日志
- SNN:合并fsiamge与edist文件成为一个新的fsimage。fsimage的冷备份
6. hdfs写入流程
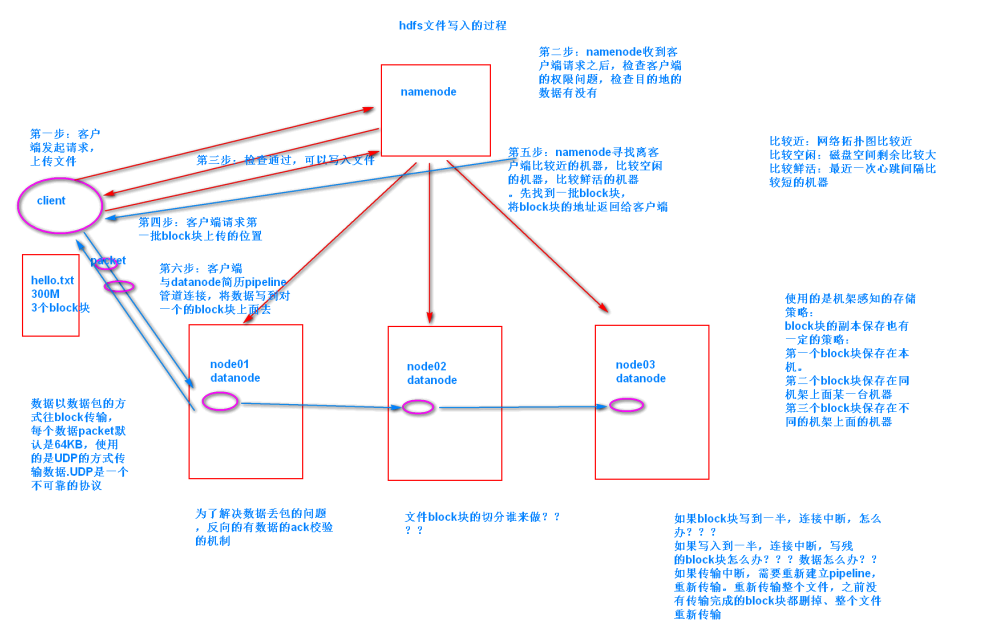
- 第一步:客户端请求上传
- 第二步:namneode校验
- 第三步:客户端请求第一批block块
- 第四步:namenode找block块返回给客户端
- 第五步:客户端与datanode通信,建立pipeline管道连接
- 第六步:数据以packet的方式发送上传,反向的进行ack数据的校验。一直往上写入数据,直到数据上传完成
7. 读取流程
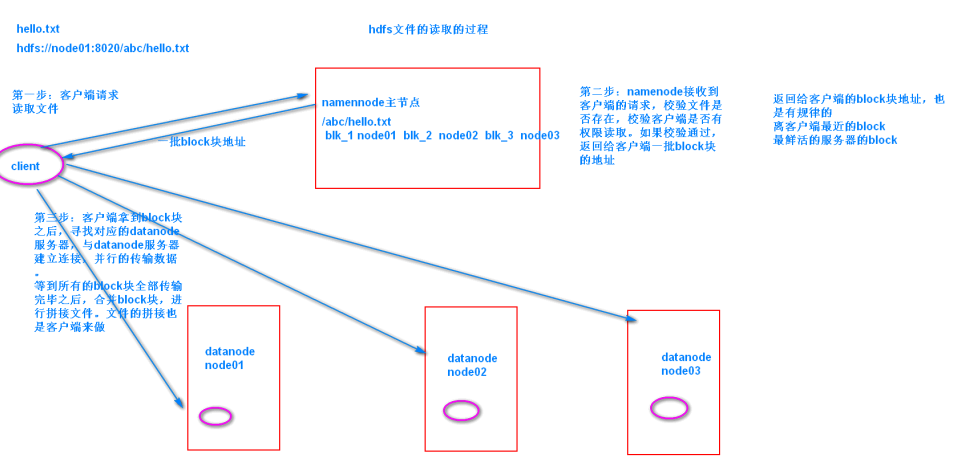
- 第一步:客户端请求读取文件
- 第二步:namenode校验客户端的权限,文件是否存在,如果校验通过,返回一批block块的地址给客户端
- 第三步:客户端拿到block块的地址,与datanode建立通信连接,读取数据
- 第四步:所有的block块传输完成,客户端拼接文件
8. hdfs的API操作
8.1 创建maven工程并导入jar包
由于cdh版本的所有的软件涉及版权的问题,所以并没有将所有的jar包托管到maven仓库当中去,而是托管在了CDH自己的服务器上面,所以我们默认去maven的仓库下载不到,需要自己手动的添加repository去CDH仓库进行下载,以下两个地址是官方文档说明,请仔细查阅
<repositories><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository></repositories><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0-mr1-cdh5.14.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.0-cdh5.14.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.6.0-cdh5.14.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.6.0-cdh5.14.0</version></dependency><!-- https://mvnrepository.com/artifact/junit/junit --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.testng</groupId><artifactId>testng</artifactId><version>RELEASE</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding><!-- <verbal>true</verbal>--></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.4.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><minimizeJar>true</minimizeJar></configuration></execution></executions></plugin><!-- <plugin> <artifactId>maven-assembly-plugin </artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>cn.itcast.hadoop.db.DBToHdfs2</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin>--></plugins></build>
8.1 如果覆盖了还是找不到jar包,
第一步:刷新项目
第二步:本地仓库update
第三步:找到本地仓库的路径,搜索.lastupdated 全部删掉
第四步:本地仓库update
以上步骤都不好使:换maven的版本
8.2 如何解决winutils.exe的问题:
- 需要在windows上面安装hadoop的运行环境,也就是一个客户端环境
- 需要下载hadoop的源码,在windows上面重新编译即可
第一步:复制windows环境的hadoop到一个没有中文没有空格的路径下
第二步:配置windows的hadoop_home环境变量
第三步:bin/hadoop.dll复制到 C:\Windows\System32
第四步:关闭windows 重启
8.3 获取FileSystem的几种方式
-第一种
@Testpublic void getFileSystem() throws URISyntaxException, IOException {Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), configuration);System.out.println(fileSystem.toString());}
第二种
@Test
public void getFileSystem2() throws URISyntaxException, IOException {Configuration configuration = new Configuration();configuration.set("fs.defaultFS","hdfs://192.168.52.100:8020");FileSystem fileSystem = FileSystem.get(new URI("/"), configuration);System.out.println(fileSystem.toString());
}
第三种
@Test
public void getFileSystem3() throws URISyntaxException, IOException {Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.52.100:8020"), configuration);System.out.println(fileSystem.toString());
}
第四种
@Test
public void getFileSystem4() throws Exception{Configuration configuration = new Configuration();configuration.set("fs.defaultFS","hdfs://192.168.52.100:8020");FileSystem fileSystem = FileSystem.newInstance(configuration);System.out.println(fileSystem.toString());
}
8.4 递归遍历文件系统当中的所有文件
第一种
@Test
public void listFile() throws Exception{FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));for (FileStatus fileStatus : fileStatuses) {if(fileStatus.isDirectory()){Path path = fileStatus.getPath();listAllFiles(fileSystem,path);}else{System.out.println("文件路径为"+fileStatus.getPath().toString());}}
}
public void listAllFiles(FileSystem fileSystem,Path path) throws Exception{FileStatus[] fileStatuses = fileSystem.listStatus(path);for (FileStatus fileStatus : fileStatuses) {if(fileStatus.isDirectory()){listAllFiles(fileSystem,fileStatus.getPath());}else{Path path1 = fileStatus.getPath();System.out.println("文件路径为"+path1);}}
}
官方提供的API直接遍历
/* 递归遍历官方提供的API版本 @throws Exception /
@Test
public void listMyFiles()throws Exception{//获取fileSystem类FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());//获取RemoteIterator 得到所有的文件或者文件夹,第一个参数指定遍历的路径,第二个参数表示是否要递归遍历RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/"), true);while (locatedFileStatusRemoteIterator.hasNext()){LocatedFileStatus next = locatedFileStatusRemoteIterator.next();System.out.println(next.getPath().toString());}fileSystem.close();
}
8.5 下载文件到本地
/** * 拷贝文件的到本地 * @throws Exception */@Testpublic void getFileToLocal()throws Exception{FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());FSDataInputStream open = fileSystem.open(new Path("/test/input/install.log"));FileOutputStream fileOutputStream = new FileOutputStream(new File("c:\\install.log"));IOUtils.copy(open,fileOutputStream );IOUtils.closeQuietly(open);IOUtils.closeQuietly(fileOutputStream);fileSystem.close();}
8.6 hdfs上创建文件夹
@Testpublic void mkdirs() throws Exception{FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());boolean mkdirs = fileSystem.mkdirs(new Path("/hello/mydir/test"));fileSystem.close();}
8.7 hdfs文件上传
@Testpublic void putData() throws Exception{FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());fileSystem.copyFromLocalFile(new Path("file:///c:\\install.log"),new Path("/hello/mydir/test"));fileSystem.close();}
8.8 HDFS权限问题以及伪造用户
首先停止hdfs集群,在node01机器上执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/stop-dfs.sh修改node01机器上的hdfs-site.xml当中的配置文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
dfs.permissions
true 修改完成之后配置文件发送到其他机器上面去
scp hdfs-site.xml node02:$PWD
scp hdfs-site.xml node03:$PWD重启hdfs集群
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/start-dfs.sh随意上传一些文件到我们hadoop集群当中准备测试使用
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
hdfs dfs -mkdir /config
hdfs dfs -put *.xml /config
hdfs dfs -chmod 600 /config/core-site.xml使用代码准备下载文件
@Test
public void getConfig()throws Exception{FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration(),"root[创建FileSystem对象,加上第三个参数root,表示我们使用哪个用户去获取文件系统上面的文件]");fileSystem.copyToLocalFile(new Path("/config/core-site.xml"),new Path("file:///c:/core-site.xml"));fileSystem.close();
}
10. hdfs小文件合并

/** * 将多个本地系统文件,上传到hdfs,并合并成一个大的文件 * @throws Exception */@Testpublic void mergeFile() throws Exception{//获取分布式文件系统FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration(),"root");FSDataOutputStream outputStream = fileSystem.create(new Path("/bigfile.xml"));//获取本地文件系统LocalFileSystem local = FileSystem.getLocal(new Configuration());//通过本地文件系统获取文件列表,为一个集合FileStatus[] fileStatuses = local.listStatus(new Path("file:///F:\\传智播客大数据离线阶段课程资料\\3、大数据离线第三天\\上传小文件合并"));for (FileStatus fileStatus : fileStatuses) {FSDataInputStream inputStream = local.open(fileStatus.getPath());IOUtils.copy(inputStream,outputStream);IOUtils.closeQuietly(inputStream);}IOUtils.closeQuietly(outputStream);local.close();fileSystem.close();}


































还没有评论,来说两句吧...