RabbitMQ集群
一、RabbitMQ集群概述
rabbitmq有三种模式:单机模式,普通集群模式,镜像集群模式
1、单机模式:
本地测试用、生产环境不会用
2、普通集群模式:
意思就是在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会放在一个rabbtimq实例上,但是每个实例都同步queue的元数据、消费的时候、会从queue所在实例上拉取数据过来、前者有数据拉取的开销,后者导致单实例性能瓶颈。
3、**镜像集群模式(适用)**
这种模式,才是所谓的rabbitmq的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。这样一台机器挂了、别的机器可以用。RabbitMQ管理控制台新增一个策略、这个策略是镜像集群模式的策略,指定的时候可以要求数据同步到所有节点的,也可以要求就同步到指定数量的节点,然后你再次创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
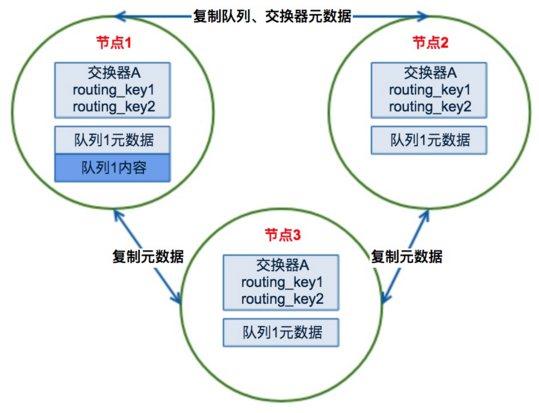
3.1、RabbitMQ集群元数据的同步
RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):a.队列元数据:队列名称和它的属性;b.交换器元数据:交换器名称、类型和属性;c.绑定元数据:一张简单的表格展示了如何将消息路由到队列;d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue/user/exchange/vhost等信息都是相同的。
3.2、为何RabbitMQ集群仅采用元数据同步的方式
第一,存储空间,如果每个集群节点都拥有所有Queue的完全数据拷贝,那么每个节点的存储空间会非常大,集群的消息积压能力会非常弱(无法通过集群节点的扩容提高消息积压能力);第二,性能,消息的发布者需要将消息复制到每一个集群节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加。
3.3、RabbitMQ保证不消费重复数据
消费者每次执行查询前,首先在DB上查询任务的执行状态,若处于「取消/失败/成功」则表示已经由其它消费者消费过,那么直接返回ACK状态码给MQ,将消息从MQ中移除;
3.4、保证消息的顺序性
rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理
图解:连接的节点2或者节点3,那这两个节点也会作为路由节点起到转发作用,将会从节点1的队列1中拉取消息进行消费
二、RabbitMQ集群的搭建
在搭建RabbitMQ集群之前有必要在每台虚拟机上安装如下的组件包,分别如下:
a.Jdk 1.8
b.Erlang运行时环境,
c.RabbitMq的Server组件,
。。。。。。。。。。。。。































还没有评论,来说两句吧...