论文笔记:Weakly Supervised Deep Detection Networks

主要方法:第一步提取region-level特征,通过在卷积层最顶端插入spatial pyramid pooling layer;然后网络被分成两个数据流从region-level特征后面开始。 第一个数据流跟每个独立区域的类别得分有关 ,进行识别的任务,,第二个数据流,通过计算各个区域概率贡献来进行对比,从而确定出包含有图片中最显著信息的region,这个叫做检测。
网络的结构上图所示。
- 预训练网络
在 ImageNet ILSVRC 2012 data 上预训练网络。然后最终的网络结构是在此基础上进行修改。首先在最后一层CNN后面的pooling(ReLU后)换成SSP层( spatial pyramid pooling ),ssp层的输入是image x,还有区域R(一系列的区域,不只是一个),区域R通过SSW(SelectiveSearchWindows)或者EB(EdgeBoxes)的方法可以获得到,然后ssp产生一个特征向量用于后面的计算。SSP层后面跟着两个fc层,这两个fc层后面都分别有ReLU作为激活函数,然后在fc7将数据流分成两部分,就是我们说的分类数据流和检测数据流。 - 分类数据流
接了一个C分类的fc,然后后面接softmax分类器,进行分类。可以预测出每个区域的类别,也就是R个。 即计算每个区域中各个类别的概率。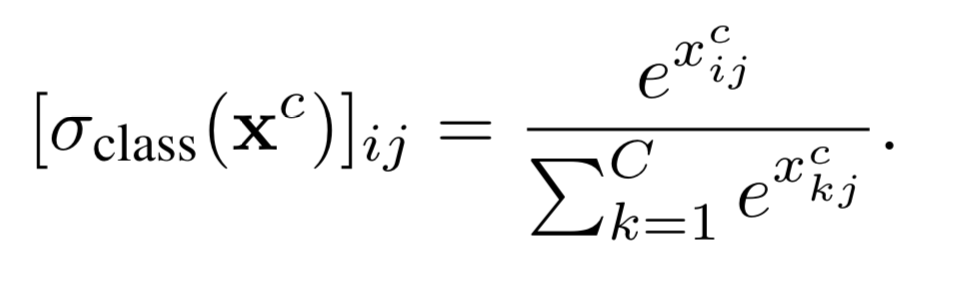
- 检测数据流
跟分类数据流的结构一模一样,都是采用了softmax分类器(求和区间不同),计算每个类别中各个区域的概率。
看完公式,不清楚什么上面代表分类,而下面代表检测。但是论文是这么说的,第一条分支,可以预测哪个类跟这个区域有关系,而第二条分支可以选择包含信息最多的区域。这个真不明白是怎么选出来的区域。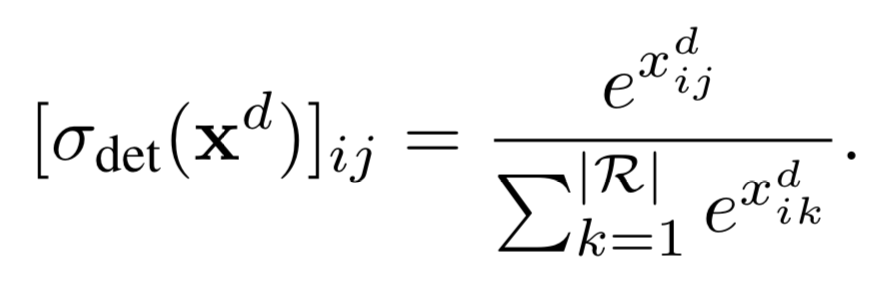
- 两个数据流的合并:
采用内积的方式进行合并,进行标准非极大值抑制的方法(去除IOU>40%的区域)来获得最终的图像中的类特定检测的列表。与双线性结构的三点不同:其一利用不同的softmax分类器来打破两个流的对称性,其二,本文使用的是内积,而双线性结构使用的是外积,第三个不同之处在于,分数class(xcr)det(xdr)是针对特定图像区域r计算的,而不是针对网格上的一组固定的图像位置计算的。 - 图像水平分类得分。 到目前为止,WSDDN已经计算了区域级分数x r
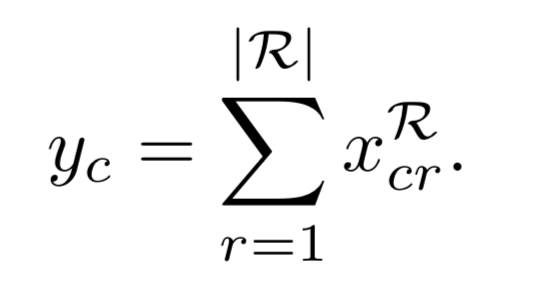
- 损失函数:
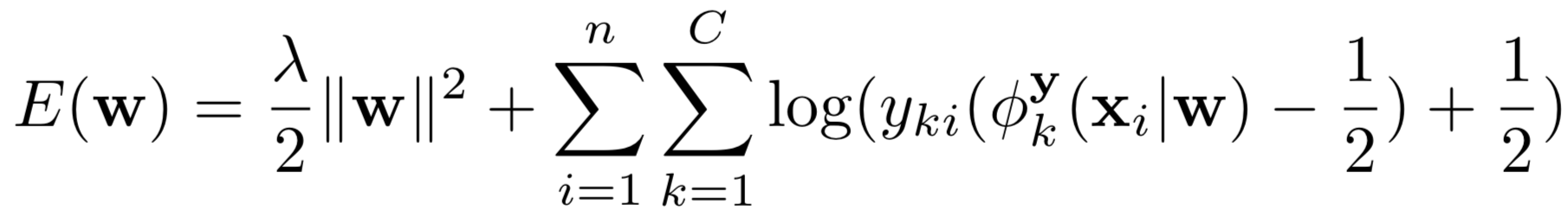
- 空间惩罚项:由于我们没有groundtruth ,不能像fast rcnn 一样根据IOU 50%来选取排除定位框。因此我们遵循软规则化策略,该策略在训练期间惩罚最高得分区域和具有至少60%IoU的区域之间的特征图差异
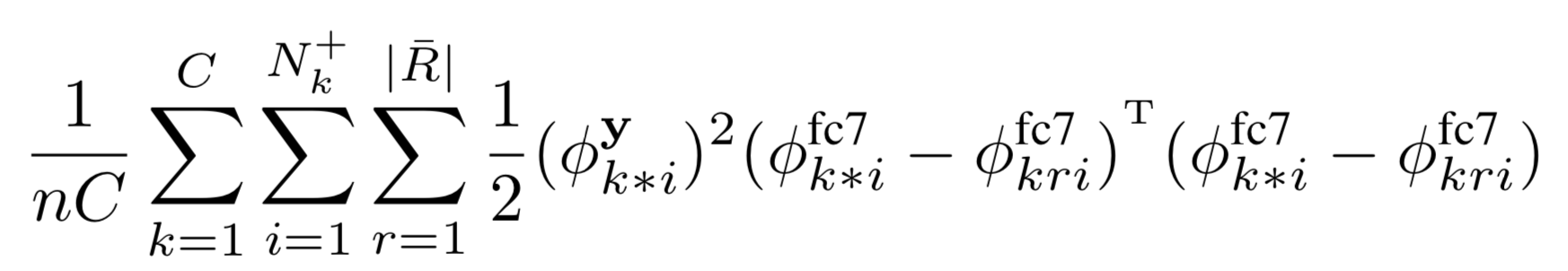
参考:
1 https://blog.csdn.net/u011534057/article/details/51219959
2 https://blog.csdn.net/baidu_17806763/article/details/58587807
3 https://blog.csdn.net/qq_35408241/article/details/83275656


























的学习记录")


![[hbase] hbase的架构及其各角色功能](https://image.dandelioncloud.cn/images/20230601/3b9ef42ad8a9409390d4df738d8087d6.png "[hbase] hbase的架构及其各角色功能")
")



还没有评论,来说两句吧...