数据结构——哈希表
一、从一道Leetcode题目认识哈希表
387. 字符串中的第一个唯一字符

因为该字符串只包含小写字母,即只存在a-z 26个小写字母,我们将其a-z对应到数组0-25索引的位置,出现一次,index+1
代码编写:
class Solution {public int firstUniqChar(String s) {int[] freq = new int[26];for(int i = 0 ; i < s.length() ; i++)//统计字符串s 中,a-z的个数freq[s.charAt(i) - 'a']++;for(int i = 0 ; i < s.length() ; i++)if(freq[s.charAt(i) - 'a'] == 1 )return i;return -1;}}
这个问题内部隐藏着哈希表的结构思想,我们开辟的 int[] freq 实际上就是一个哈希表,每一个字符都和数组中的一个索引对应

此时我们简单地坐到了将字符与索引进行了一一对应,这种将”键”转化为”索引”的方式,称为哈希函数。
有如一个班总共有30名学生,我们可以使用数组0-29分别表示这30名学生。
但是在某些情况下,如我们需要保存居民身份证、字符串、浮点数、日期等信息,就很难保证每一个”键”通过哈希函数的转换对应不同的”索引”。
不同的”键”通过哈希函数对应了同一个”索引”,称为哈希冲突。
哈希表充分体现了算法设计领域的经典思想:使用空间换取时间

所以我们需要①设计一个合理的哈希函数实现”键”与”索引”的对应关系,”键”通过哈希函数得到的”索引”分布越均匀越好
②解决哈希冲突。
二、哈希函数的设计
“键”通过哈希函数得到的”索引”分布越均匀越好,哈希函数的设计很复杂,我们并不关注某一个特殊的领域,本文只对一般的哈希函数进行设计。

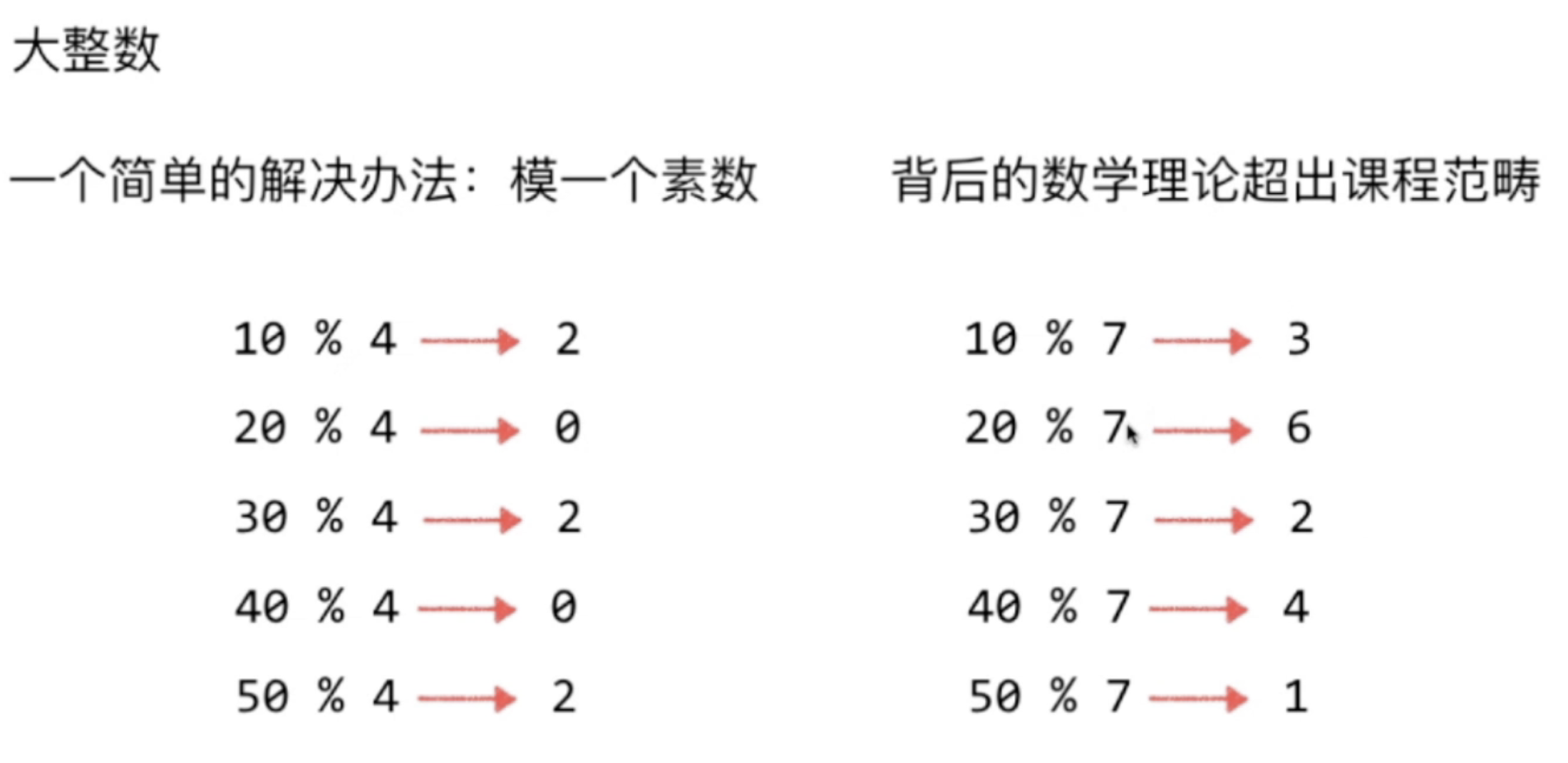
后6位的前两位”16”取值范围为01 ~ 31 表示日期,造成了分布不均的问题,可见对取模的值的选择十分重要,一般模一个素数

模以合数和素数的区别:
浮点数—->转化为整形处理
字符串—->转化为整形处理


对应的代码:

符合类型—->转化为整形处理

关于哈希函数设计的总结:

三、Java中的hashCode()
Object类中的hashCode()方法,在整形中的hashCode为数字本身,Double、Float、String等都重写了Object类中的hashCode()。
略
四、解决哈希冲突方法(链地址法Seperate Chaining)

五、编码实现哈希表
version1:
public class HashTable<K, V> {private TreeMap<K,V>[] hashtable;private int M;private int size;public HashTable(int M){this.M = M;size = 0 ;hashtable = new TreeMap[M];for(int i = 0 ; i< M ;i++){hashtable[i] = new TreeMap<>();}}public HashTable(){this(97);}private int hash(K key){return ( key.hashCode() & 0x7fffffff ) % M;}public int getSize(){return size;}public void add(K key , V value){TreeMap<K,V> map = hashtable[hash(key)];if (map.containsKey(key))map.put(key,value);else{map.put(key,value);size ++;}}public V remove(K key){TreeMap<K,V> map = hashtable[hash(key)];V ret = null;if(map.containsKey(key)){ret = map.remove(key);size --;}return ret;}public void set(K key, V value){TreeMap<K, V> map = hashtable[hash(key)];if(!map.containsKey(key))throw new IllegalArgumentException(key + " doesn't exist!");map.put(key, value);}public boolean contains(K key){return hashtable[hash(key)].containsKey(key);}public V get(K key){return hashtable[hash(key)].get(key);}}
分析此时间复杂度:

要想尽可能达到O(1),固定地址空间是不合理的,需要resize()。

//HashTable类新建成员变量private static final int upperTol = 10;private static final int lowerTol = 2;private static final int initCapacity = 7;public void add(K key, V value) {TreeMap<K, V> map = hashtable[hash(key)];if (map.containsKey(key))map.put(key, value);else {map.put(key, value);size++;if (size >= upperTol * M)resize(2 * M);}}public V remove(K key) {TreeMap<K, V> map = hashtable[hash(key)];V ret = null;if (map.containsKey(key)) {ret = map.remove(key);size--;if (size <= lowerTol * M && M > initCapacity)resize(M / 2);}return ret;}private void resize(int newM){TreeMap<K, V>[] newHashTable = new TreeMap[newM];for(int i = 0 ; i < newM ; i ++)newHashTable[i] = new TreeMap<>();for(int i = 0 ; i < M ; i ++)for(K key: hashtable[i].keySet())newHashTable[hash(key)].put(key, hashtable[i].get(key));this.M = newM;this.hashtable = newHashTable;}
再次分析此时间复杂度:

我们在add后的resize(2 * M)方法中 扩容M —-> 2*M ,发现扩容后2 * M 此时并不是一个素数。
改进:采用素数,考虑HashMap的扩容,略
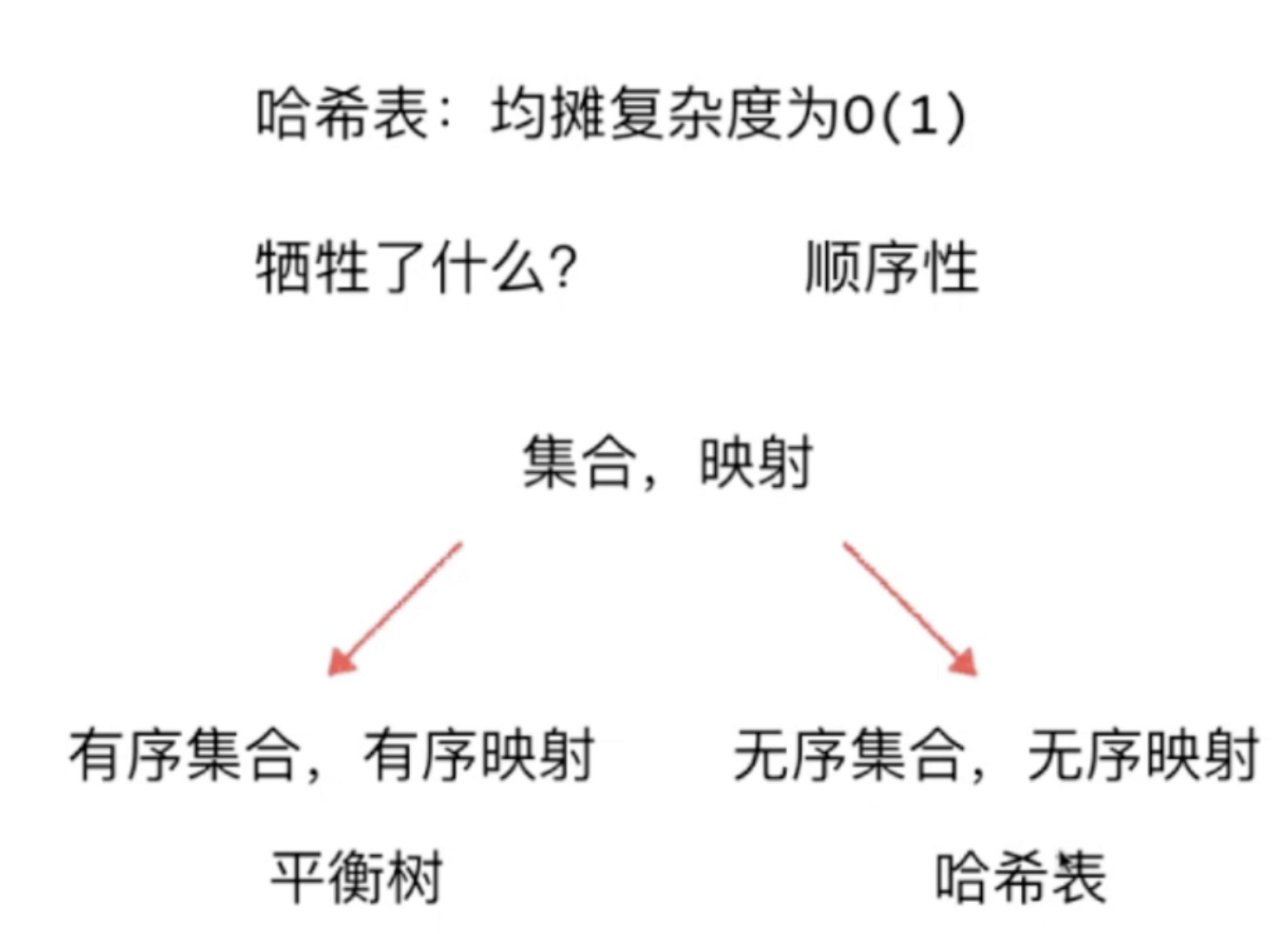
哈希表的得失





























")




还没有评论,来说两句吧...