SpingDataJpa
SpringDataJpa
- SpringDataJpa
简介
- 传统数据库访问数据库
- 使用Spring JDBC Template对数据库进行操作
- SpringData
- Repository接口
- CrudRepository接口
- PagingAndSortingRepository接口
- JpaRepository接口
- JpaSpecificationExecutor接口
简介
Spring Data 是为数据访问提供一种熟悉且一致的基于Spring的编程模型,同时仍然保留底层数据存储的特殊特性。它可以轻松使用数据访问技术,可以访问关系和非关系数据库。
Spring Data 又包含多个子项目:
- Spring Data JPA
- Spirng Data Mongo DB
- Spring Data Redis
- Spring Data Solr
传统数据库访问数据库
使用原始JDBC方式进行数据库操作
创建数据表
jdbc工具类
package com.JDBC.util;import java.io.InputStream;import java.sql.*;import java.util.Properties;public class JDBCUtil {public static Connection getConnection() throws Exception {InputStream inputStream = JDBCUtil.class.getClassLoader().getResourceAsStream("db.properties");Properties properties = new Properties();properties.load(inputStream);String url = properties.getProperty("jdbc.url");String user = properties.getProperty("jdbc.user");String password = properties.getProperty("jdbc.password");String driverClass = properties.getProperty("jdbc.driverClass");Class.forName(driverClass);Connection connection = DriverManager.getConnection(url, user, password);return connection;}public static void release(ResultSet resultSet, Statement statement,Connection connection) {if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}}if (statement != null) {try {statement.close();} catch (SQLException e) {e.printStackTrace();}}if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}}
建立POJO
package com.xx;public class Student {private int id;private String name;private int age;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}}package com.xx.dao;import com.xx.domain.Student;import com.xx.util.JDBCUtil;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.util.ArrayList;import java.util.List;public class StudentDAOImpl implements StudentDAO{/** * 查询学生 */@Overridepublic List<Student> query() {List<Student> students = new ArrayList<>();Connection connection = null;PreparedStatement preparedStatement = null;ResultSet resultSet = null;String sql = "select * from student";try {connection = JDBCUtil.getConnection();preparedStatement = connection.prepareStatement(sql);resultSet = preparedStatement.executeQuery();Student student = null;while (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("name");int age = resultSet.getInt("age");student = new Student();student.setId(id);student.setAge(age);student.setName(name);students.add(student);}} catch (Exception e) {e.printStackTrace();}finally {JDBCUtil.release(resultSet,preparedStatement,connection);}return students;}/** * 添加学生 */@Overridepublic void save(Student student) {Connection connection = null;PreparedStatement preparedStatement = null;ResultSet resultSet = null;String sql = "insert into student(name,age) values (?,?)";try {connection = JDBCUtil.getConnection();preparedStatement = connection.prepareStatement(sql);preparedStatement.setString(1, student.getName());preparedStatement.setInt(2,student.getAge());preparedStatement.executeUpdate();} catch (Exception e) {e.printStackTrace();}finally {JDBCUtil.release(resultSet,preparedStatement,connection);}}}
使用Spring JDBC Template对数据库进行操作
创建spring配置文件:
<?xml version=”1.0” encoding=”UTF-8”?>
编写查询学生和保存学生的方法
package com.xx.dao;
import com.xx.domain.Student;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowCallbackHandler;import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class StudentDAOSpringJdbcImpl implements StudentDAO{private JdbcTemplate jdbcTemplate;public void setJdbcTemplate(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}@Overridepublic List<Student> query() {final List<Student> students = new ArrayList<>();String sql = "select * from student";jdbcTemplate.query(sql, new RowCallbackHandler() {@Overridepublic void processRow(ResultSet resultSet) throws SQLException {int id = resultSet.getInt("id");String name = resultSet.getString("name");int age = resultSet.getInt("age");Student student = new Student();student.setId(id);student.setAge(age);student.setName(name);students.add(student);}});return students;}@Overridepublic void save(Student student) {String sql = "insert into student(name,age) values (?,?)";jdbcTemplate.update(sql, new Object[]{student.getName(), student.getAge()});}}
弊端分析
- DAO中有太多的代码
- DAOImpl有大量重复代码
- 开发分页或者其他功能还要重新封装
SpringData
例:
添加pom依赖
org.springframework.data
spring-data-jpa
1.8.0.RELEASE
org.hibernate
hibernate-entitymanager
4.3.6.Final 创建一个新的spring配置文件
<?xml version=”1.0” encoding=”UTF-8”?>
org.hibernate.cfg.ImprovedNamingStrategy
org.hibernate.dialect.MySQL5InnoDBDialect
true
true
update
LocalContainerEntityMangaerFactoryBean:
适用于所有环境的FactoryBean,能全面控制EntityMangaerFactory配置,非常适合那种需要细粒度定制的环境。
jpaVendorAdapter:
用于设置JPA实现厂商的特定属性,如设置hibernate的是否自动生成DDL的属性generateDdl,这些属性是厂商特定的。目前spring提供HibernateJpaVendorAdapter,OpenJpaVendorAdapter,EclipseJpaVendorAdapter,TopLinkJpaVenderAdapter四个实现。
jpaProperties:
指定JPA属性;如Hibernate中指定是否显示SQL的“hibernate.show_sql”属性。
建立实体类Employee:
package com.xx;
public class Employee {private Integer id;private String name;private Integer age;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}}
自定义接口并继承Repository 接口
继承的Repository接口泛型里的第一个参数是要操作的对象,即Employee;第二个参数是主键id的类型,即Integer。
方法即为根据名字找员工,这个接口是不用写实现类的。为什么可以只继承接口定义了方法就行了呢,因为spring data底层会根据一些规则来进行相应的操作。
所以方法的名字是不能随便写的,不然就无法执行想要的操作。package com.xx.repository;
import com.zzh.domain.Employee;
import org.springframework.data.repository.Repository;public interface EmployeeRepository extends Repository
Employee findByName(String name);
}
创建测试类
findByName方法体中先不用写,直接执行空的测试方法,我们的Employee表就自动被创建了,此时表中没有数据,向里面添加一条数据用于测试: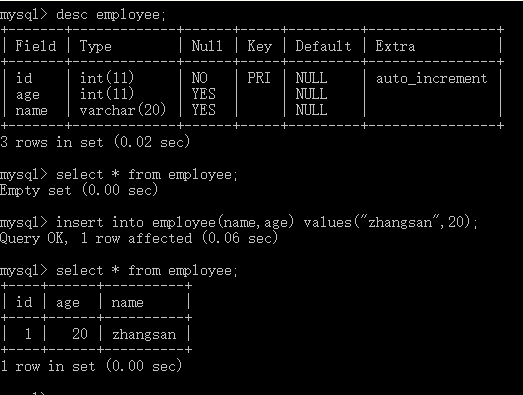
package com.xx.repository;
import com.xx.domain.Employee;import org.junit.After;import org.junit.Before;import org.junit.Test;import org.springframework.context.ApplicationContext;import org.springframework.context.support.ClassPathXmlApplicationContext;public class EmployeeRepositoryTest {private ApplicationContext ctx = null;private EmployeeRepository employeeRepository = null;@Beforepublic void setUp() throws Exception {ctx = new ClassPathXmlApplicationContext("beans-new.xml");employeeRepository = ctx.getBean(EmployeeRepository.class);}@Afterpublic void tearDown() throws Exception {ctx = null;}@Testpublic void findByName() throws Exception {Employee employee = employeeRepository.findByName("zhangsan");System.out.println("id:" + employee.getId() + " name:" + employee.getName() + " age:" + employee.getAge());}}
再执行测试方法中的内容:
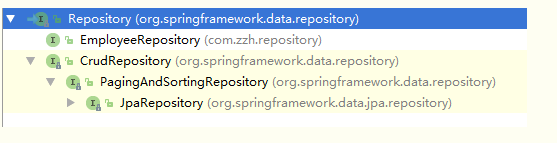
Repository接口
- Repository接口是Spring Data的核心接口,不提供任何方法
- 使用 @ RepositoryDefinition注解跟继承Repository是同样的效果,例如 @ RepositoryDefinition(domainClass = Employee.class, idClass = Integer.class)
- Repository接口定义为:public interface Repository
Repository的子接口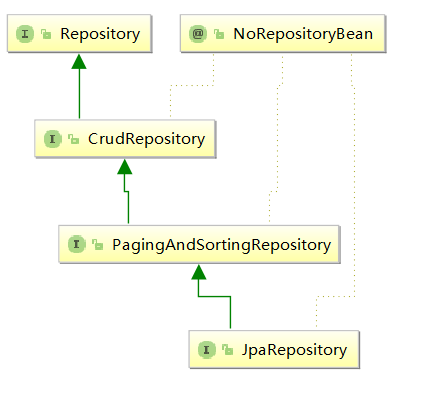
- CrudRepository :继承 Repository,实现了CRUD相关的方法。
- PagingAndSortingRepository : 继承 CrudRepository,实现了分页排序相关的方法。
- JpaRepository :继承 PagingAndSortingRepository ,实现了JPA规范相关的方法。
Repository中查询方法定义规则
上面一个例子中使用了findByName作为方法名进行指定查询,但是如果把名字改为其他没有规则的比如test就无法获得正确的查询结果。
有如下规则:
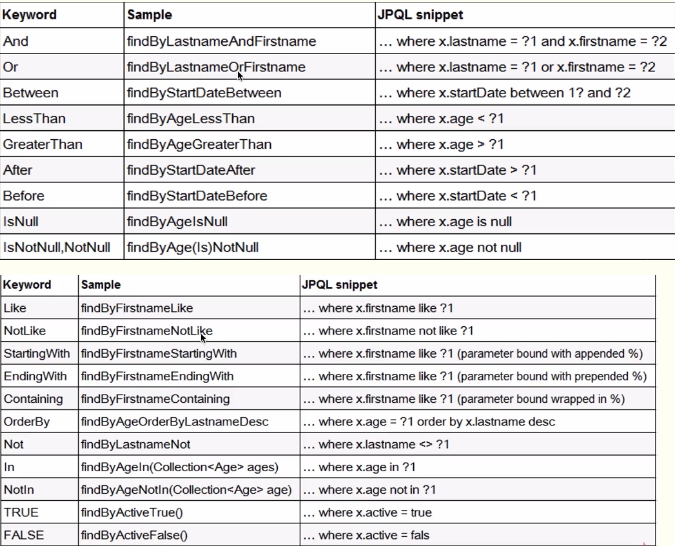
最右边是sql语法,中间的就是spring data操作规范,现在写一些小例子来示范一下:
先在employee表中初始化了一些数据:
在继承了Repository接口的EmployeeRepository接口中新增一个方法: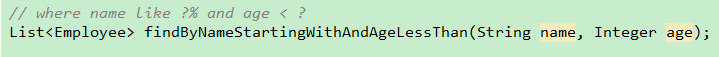
条件是名字以test开头,并且年龄小于22岁,在测试类中进行测试:
得到结果: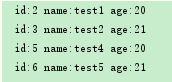
在换一个名字要在某个范围以内并且年龄要小于某个值:
测试类:
得到结果,只有test1和test2,因为在test1,test2和test3里面,年龄还要小于22,所以test3被排除了: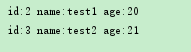
弊端分析
对于按照方法名命名规则来使用的弊端在于:
- 方法名会比较长
- 对于一些复杂的查询很难实现
Query注解
- 只需要将 @ Query标记在继承了Repository的自定义接口的方法上,就不再需要遵循查询方法命名规则。
- 支持命名参数及索引参数的使用
- 本地查询
案例
查询Id最大的员工信息
@Query(“select o from Employee o where id=(select max(id) from Employee t1)”) Employee getEmployeeById();
注意: Query语句中第一个Employee是类名
测试类:
@Testpublic void getEmployeeByMaxId() throws Exception {Employee employee = employeeRepository.getEmployeeByMaxId();System.out.println("id:" + employee.getId() + " name:" + employee.getName() + " age:" + employee.getAge());}
- 根据占位符进行查询
注意: 占位符从1开始
@Query("select o from Employee o where o.name=?1 and o.age=?2")List<Employee> queryParams1(String name, Integer age);
测试方法:
@Testpublic void queryParams1() throws Exception {List<Employee> employees = employeeRepository.queryParams1("zhangsan", 20);for (Employee employee : employees) {System.out.println("id:" + employee.getId() + " name:" + employee.getName() + " age:" + employee.getAge());}}
根据命名参数的方式
@Query(“select o from Employee o where o.name=:name and o.age=:age”) List
queryParams2(@Param(“name”) String name, @Param(“age”) Integer age); like查询语句
@Query(“select o from Employee o where o.name like %?1%”)
List<Employee> queryLike1(String name);
@Test
public void queryLike1() throws Exception {List<Employee> employees = employeeRepository.queryLike1("test");for (Employee employee : employees) {System.out.println("id:" + employee.getId() + " name:" + employee.getName() + " age:" + employee.getAge());}}
like语句使用命名参数
@Query(“select o from Employee o where o.name like %:name%”) List
queryLike2(@Param(“name”) String name);
本地查询
所谓本地查询,就是使用原生的sql语句进行查询数据库的操作。但是在Query中原生态查询默认是关闭的,需要手动设置为true:
@Query(nativeQuery = true, value = "select count(1) from employee")long getCount();
更新操作整合事物使用
在DAO中定义方法根据Id来更新年龄(Modifying注解代表允许修改)
@Modifying @Query(“update Employee o set o.age = :age where o.id = :id”) void update(@Param(“id”) Integer id, @Param(“age”) Integer age);
要注意,执行更新或者删除操作是需要事物支持,所以通过service层来增加事物功能,在update方法上添加Transactional注解。
package com.xx.service;import com.xx.repository.EmployeeRepository;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;@Servicepublic class EmployeeService {@Autowiredprivate EmployeeRepository employeeRepository;@Transactionalpublic void update(Integer id, Integer age) {employeeRepository.update(id,age);}}
删除操作
删除操作同样需要Query注解,Modifying注解和Transactional注解
@Modifying
@Query("delete from Employee o where o.id = :id")void delete(@Param("id") Integer id);
@Transactionalpublic void delete(Integer id) {employeeRepository.delete(id);}
CrudRepository接口

创建接口继承CrudRepository
package com.xx.repository;
import com.xx.domain.Employee;import org.springframework.data.repository.CrudRepository;public interface EmployeeCrudRepository extends CrudRepository<Employee,Integer>{}
在service层中调用
@Autowired
private EmployeeCrudRepository employeeCrudRepository;
存入多个对象
@Transactional
public void save(List<Employee> employees) {employeeCrudRepository.save(employees);}
创建测试类,将要插入的100条记录放在List中:
package com.xx.repository;
import com.xx.domain.Employee;
import com.xx.service.EmployeeService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import java.util.ArrayList;
import java.util.List;
@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration({"classpath:beans-new.xml"})public class EmployeeCrudRepositoryTest {@Autowiredprivate EmployeeService employeeService;@Testpublic void testSave() {List<Employee> employees = new ArrayList<>();Employee employee = null;for (int i = 0; i < 100; i++) {employee = new Employee();employee.setName("test" + i);employee.setAge(100 - i);employees.add(employee);}employeeService.save(employees);}}
执行后: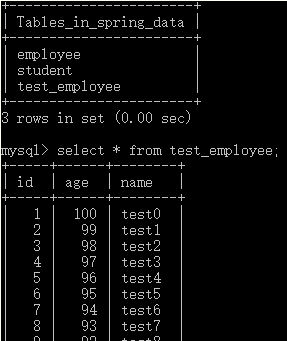
CrudRepository总结
可以发现在自定义的EmployeeCrudRepository中,只需要声明接口并继承CrudRepository就可以直接使用了。
PagingAndSortingRepository接口
- 该接口包含分页和排序的功能
- 带排序的查询:findAll(Sort sort)
带排序的分页查询:findAll(Pageable pageable)
自定义接口
package com.xx.repository;
import com.xx.domain.Employee;import org.springframework.data.repository.PagingAndSortingRepository;public interface EmployeePagingAndSortingRepository extends PagingAndSortingRepository<Employee, Integer> {}
测试类:
分页
package com.xx.repository;import com.xx.domain.Employee;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.domain.Page;import org.springframework.data.domain.PageRequest;import org.springframework.data.domain.Pageable;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration({"classpath:beans-new.xml"})public class EmployeePagingAndSortingRepositoryTest {@Autowiredprivate EmployeePagingAndSortingRepository employeePagingAndSortingRepository;@Testpublic void testPage() {//第0页,每页5条记录Pageable pageable = new PageRequest(0, 5);Page<Employee> page = employeePagingAndSortingRepository.findAll(pageable);System.out.println("查询的总页数:"+ page.getTotalPages());System.out.println("总记录数:"+ page.getTotalElements());System.out.println("当前第几页:"+ page.getNumber()+1);System.out.println("当前页面对象的集合:"+ page.getContent());System.out.println("当前页面的记录数:"+ page.getNumberOfElements());}}
排序:
在PageRequest的构造函数里还可以传入一个参数Sort,而Sort的构造函数可以传入一个Order,Order可以理解为关系型数据库中的Order;Order的构造函数Direction和property参数代表按照哪个字段进行升序还是降序。
现在按照id进行降序排序:
@Testpublic void testPageAndSort() {Sort.Order order = new Sort.Order(Sort.Direction.DESC, "id");Sort sort = new Sort(order);Pageable pageable = new PageRequest(0, 5, sort);Page<Employee> page = employeePagingAndSortingRepository.findAll(pageable);System.out.println("查询的总页数:"+ page.getTotalPages());System.out.println("总记录数:"+ page.getTotalElements());System.out.println("当前第几页:" + page.getNumber() + 1);System.out.println("当前页面对象的集合:"+ page.getContent());System.out.println("当前页面的记录数:"+ page.getNumberOfElements());}
JpaRepository接口

创建接口继承JpaRepository
package com.xx.repository;
import com.xx.domain.Employee;import org.springframework.data.jpa.repository.JpaRepository;public interface EmployeeJpaRepository extends JpaRepository<Employee,Integer>{}
测试类:
package com.xx.repository;
import com.xx.domain.Employee;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration({"classpath:beans-new.xml"})public class EmployeeJpaRepositoryTest {@Autowiredprivate EmployeeJpaRepository employeeJpaRepository;@Testpublic void testFind() {Employee employee = employeeJpaRepository.findOne(99);System.out.println(employee);}}
查看员工是否存在
@Testpublic void testExists() {Boolean result1 = employeeJpaRepository.exists(25);Boolean result2 = employeeJpaRepository.exists(130);System.out.println("Employee-25: " + result1);System.out.println("Employee-130: " + result2);}
JpaSpecificationExecutor接口
- Specification封装了JPA Criteria查询条件
没有继承其他接口。
自定义接口
这里要尤为注意,为什么我除了继承JpaSpecificationExecutor还要继承JpaRepository,就像前面说的,JpaSpecificationExecutor没有继承任何接口,如果我不继承JpaRepository,那也就意味着不能继承Repository接口,spring就不能进行管理,后面的自定义接口注入就无法完成。
package com.xx.repository;
import com.xx.domain.Employee;import org.springframework.data.jpa.repository.JpaRepository;import org.springframework.data.jpa.repository.JpaSpecificationExecutor;public interface EmployeeJpaSpecificationExecutor extends JpaSpecificationExecutor<Employee>,JpaRepository<Employee,Integer> {}
测试类
测试结果包含分页,降序排序,查询条件为年龄大于50
package com.xx.repository;import com.xx.domain.Employee;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.domain.Page;import org.springframework.data.domain.PageRequest;import org.springframework.data.domain.Pageable;import org.springframework.data.domain.Sort;import org.springframework.data.jpa.domain.Specification;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import javax.persistence.criteria.*;@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration({"classpath:beans-new.xml"})public class EmployeeJpaSpecificationExecutorTest {@Autowiredprivate EmployeeJpaSpecificationExecutor employeeJpaSpecificationExecutor;/** * 分页 * 排序 * 查询条件: age > 50 */@Testpublic void testQuery() {Sort.Order order = new Sort.Order(Sort.Direction.DESC, "id");Sort sort = new Sort(order);Pageable pageable = new PageRequest(0, 5, sort);/** * root:查询的类型(Employee) * query:添加查询条件 * cb:构建Predicate */Specification<Employee> specification = new Specification<Employee>() {@Overridepublic Predicate toPredicate(Root<Employee> root, CriteriaQuery<?> query, CriteriaBuilder cb) {Path path = root.get("age");return cb.gt(path, 50);}};Page<Employee> page = employeeJpaSpecificationExecutor.findAll(specification, pageable);System.out.println("查询的总页数:"+ page.getTotalPages());System.out.println("总记录数:"+ page.getTotalElements());System.out.println("当前第几页:" + page.getNumber() + 1);System.out.println("当前页面对象的集合:"+ page.getContent());System.out.println("当前页面的记录数:"+ page.getNumberOfElements());}}

























![洛谷——P2559 [AHOI2002]哈利·波特与魔法石](https://image.dandelioncloud.cn/images/20210726/aa4b7f26f01340b19306a3c4d1988829.png "洛谷——P2559 [AHOI2002]哈利·波特与魔法石")





还没有评论,来说两句吧...