李航《统计学习方法》——第八章 提升方法
提升方法就是组合一系列弱分类器构成一个强分类器,AdaBoost是其代表性算法
AdaBoost算法
适用问题:二类分类,要处理多类分类需进行改进
代码(用sklearn实现):
# encoding=utf-8import pandas as pdimport timefrom sklearn.cross_validation import train_test_splitfrom sklearn.metrics import accuracy_scorefrom sklearn.ensemble import AdaBoostClassifierif __name__ == '__main__':print("Start read data...")time_1 = time.time()raw_data = pd.read_csv('../data/train_binary.csv', header=0)data = raw_data.valuesfeatures = data[::, 1::]labels = data[::, 0]# 随机选取33%数据作为测试集,剩余为训练集train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)time_2 = time.time()print('read data cost %f seconds' % (time_2 - time_1))print('Start training...')# n_estimators表示要组合的弱分类器个数;# algorithm可选{‘SAMME’, ‘SAMME.R’},默认为‘SAMME.R’,表示使用的是real boosting算法,‘SAMME’表示使用的是discrete boosting算法clf = AdaBoostClassifier(n_estimators=100,algorithm='SAMME.R')clf.fit(train_features,train_labels)time_3 = time.time()print('training cost %f seconds' % (time_3 - time_2))print('Start predicting...')test_predict = clf.predict(test_features)time_4 = time.time()print('predicting cost %f seconds' % (time_4 - time_3))score = accuracy_score(test_labels, test_predict)print("The accruacy score is %f" % score)
代码可从这里AdaBoost/AdaBoost_sklearn.py获取
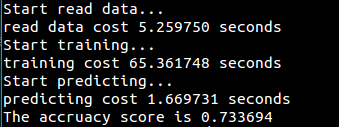
实验数据为train.csv的运行结果:
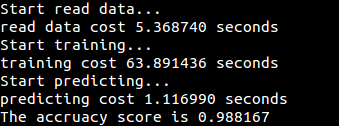
实验数据为train_binary.csv的运行结果:

























![洛谷——P2559 [AHOI2002]哈利·波特与魔法石](https://image.dandelioncloud.cn/images/20210726/aa4b7f26f01340b19306a3c4d1988829.png "洛谷——P2559 [AHOI2002]哈利·波特与魔法石")





还没有评论,来说两句吧...