scala中的集合与集合操作
scala中的集合
Scala的集合类可以从三个维度进行切分:
- 可变与不可变集合(Immutable and mutable collections)
- 静态与延迟加载集合 (Eager and delayed evaluation )
- 串行与并行计算集合(Sequential and parallel evaluation )
可变与不可变集合[1]
可变集合可以在适当的地方被更新或扩展。这意味着你可以修改,添加,移除一个集合的元素。
而不可变集合类,相比之下,永远不会改变。不过,你仍然可以模拟添加,移除或更新操作。但是这些操作将在每一种情况下都返回一个新的集合,同时使原来的集合不发生改变。
所有的集合类都可以在包scala.collection 或scala.collection.mutable,scala.collection.immutable,scala.collection.generic中找到。
下面的图表显示了scala.collection包中所有的集合类。这些都是高级抽象类或特性,它们通常具备和不可变实现一样的可变实现。
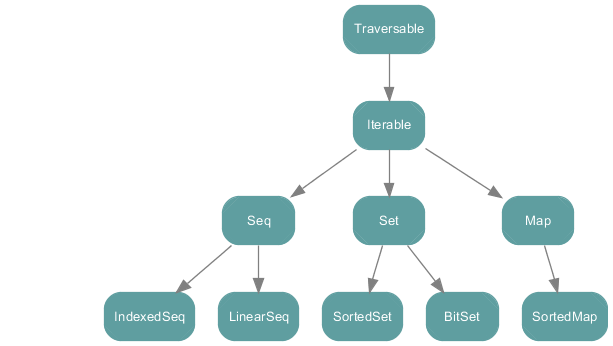
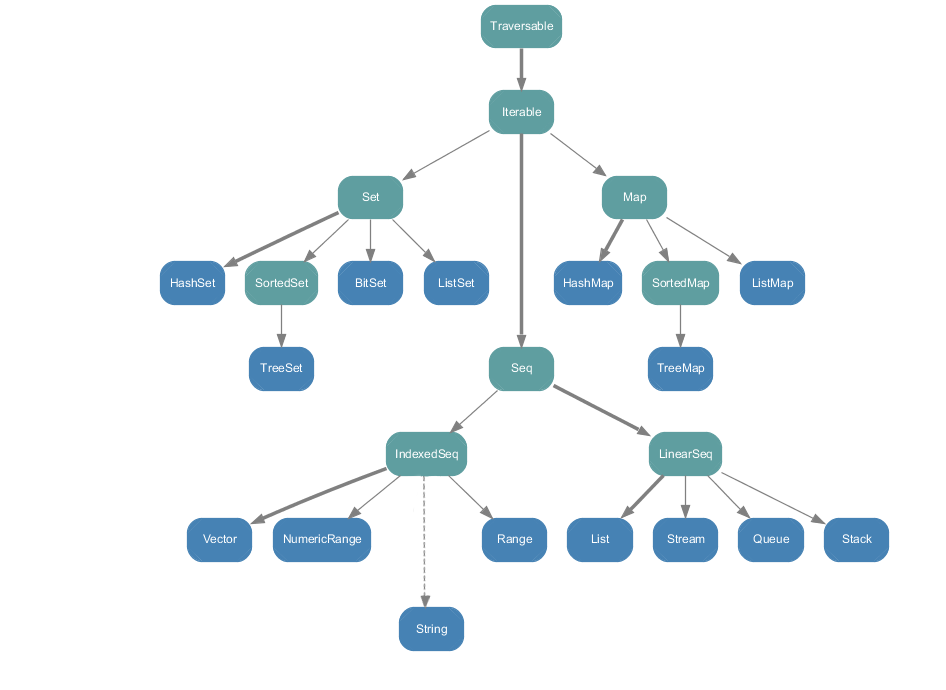
下面的图表显示scala.collection.immutable中的所有集合类。
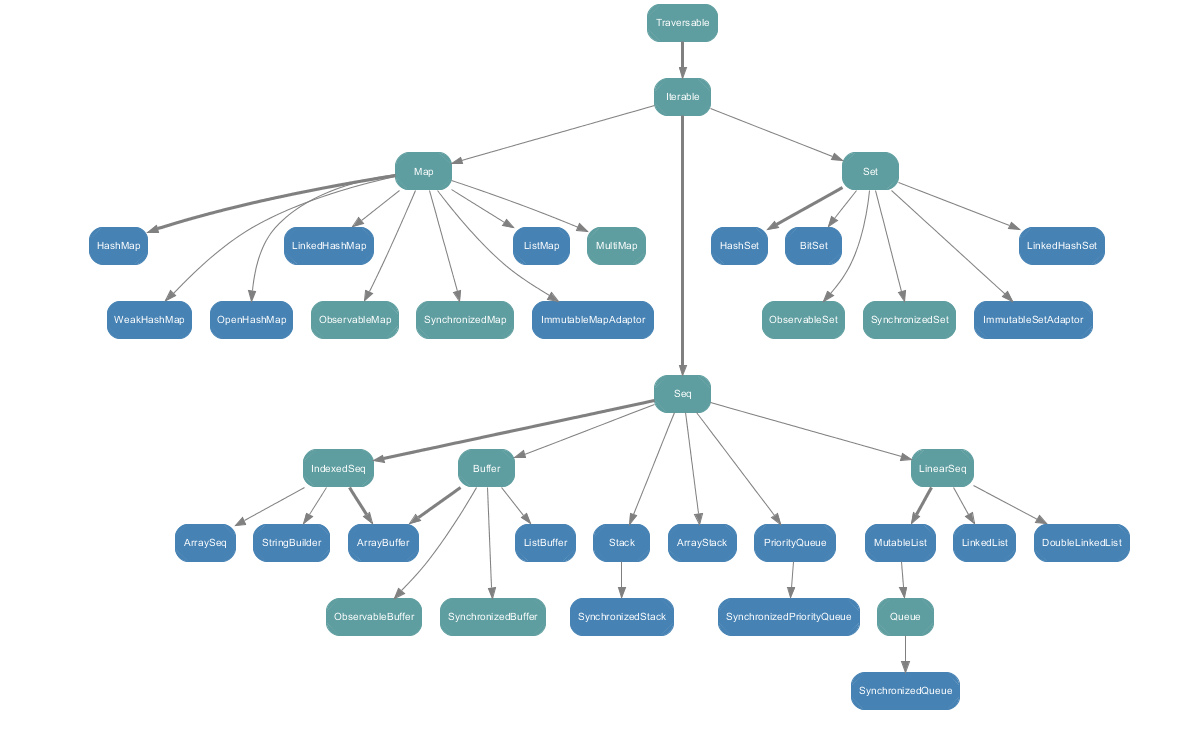
下面的图表显示scala.collection.mutable中的所有集合类。
代码需要的大部分集合类都独立地存在于3种变体中,它们位于scala.collection, scala.collection.immutable, scala.collection.mutable包。每一种变体在可变性方面都有不同的特征。
collection.generic包含了集合的构建块。集合类延迟了collection.generic类中的部分操作实现,另一方面集合框架的用户仅仅需要在异常环境中引用collection.generic的类。
scala.collection.immutable包是的集合类确保不被任何对象改变。例如一个集合创建之后将不会改变。因此,你可以确信的是在不同的位置和时间去访问同一个不可变集合的值,你将总是得到相同的元素。scala.collection.mutable包的集合类则有一些操作可以修改集合。所以处理可变集合意味着你需要去理解哪些操作会导致集合改变。scala.collection包中的集合,既可以是可变的,也可以是不可变的。scala.collection包中的根集合类中定义了和不可变集合相同的接口,同时,scala.collection.mutable包中的可变集合类代表性地往这个接口中添加了一些辅助作用的修改操作。- 例如:collection.IndexedSeq[T]] 就是 collection.immutable.IndexedSeq[T] 和collection.mutable.IndexedSeq[T]这两类的超类。
- 根集合类与不可变集合类之间的区别:不可变集合类可以确保没有人可以修改集合。然而,根集合类仅保证不修改集合本身。即使这个集合类没有提供修改集合的静态操作,它仍然可能在运行时作为可变集合被其它客户端所修改。
默认情况下,Scala 一直采用不可变集合类。例如,如果你仅写了Set 而没有任何加前缀也没有从其它地方导入Set,你会得到一个不可变的set,另外如果你写迭代,你也会得到一个不可变的迭代集合类,这是由于这些类在从scala中导入的时候都是默认绑定的。为了得到可变的默认版本,你需要显式的声明collection.mutable.Set或collection.mutable.Iterable。
一个有用的约定,如果你想要同时使用可变和不可变集合类,只导入collection.mutable包即可。
import scala.collection.mutablemutable.Set // 可变Set // 不可变
静态与延迟加载集合[2]
我们来解释一个概念:transformation。集合中有大量的操作都是把一个集合“转换”成另一个集合,比如map,filter等等。
而Eager和Delayed集合的区别在于:Eager集合总是立即为元素分配内存,当遇到一个transform动作时,Eager的集合会直接计算并返回结果,而Delayed集合则会尽可能晚的推迟执行,直到必须返回结果时才去执行。这一点和Spark RDD操作中的transformation和action非常类似。
在现有的集合里,只有Stream是Lasy的,所有其他的集合都是静态(Eager)加载的。但是你可以很容易地把一个静态集合转换成lazy的,那就是创建一个view。
关于集合的种类以及其他特性,参见参考资料[2]。他那边整理了一个表格,大家可以去看看。
操作方法
scala中的集合操作分为两类:转换操作(transformation )和行动操作(actions)(有些人喜欢叫他为聚合操作)。第一种操作类型将集合转换为另一个集合,第二种操作类型返回某些类型的值。
常用操作符
scala中的操作符也是类中的方法:
++ 从列表的尾部添加另外一个列表
++: 在列表的头部添加一个列表
+: 在列表的头部添加一个元素
:+ 在列表的尾部添加一个元素
:: 在列表的头部添加一个元素
::: 在列表的头部添加另外一个列表
val left = List(1,2,3)val right = List(4,5,6)//以下操作等价left ++ right // List(1,2,3,4,5,6)left ++: right // List(1,2,3,4,5,6)right.++:(left) // List(1,2,3,4,5,6)right.:::(left) // List(1,2,3,4,5,6)//以下操作等价0 +: left //List(0,1,2,3)left.+:(0) //List(0,1,2,3)//以下操作等价left :+ 4 //List(1,2,3,4)left.:+(4) //List(1,2,3,4)//以下操作等价0 :: left //List(0,1,2,3)left.::(0) //List(0,1,2,3)
最大值和最小值
在序列中查找最大或最小值。
val numbers = Seq(11, 2, 5, 1, 6, 3, 9)numbers.max //11numbers.min //1
但实际操作的数据更加复杂。下面我们介绍一个更高级的例子,其中包含一个书的序列。
case class Book(title: String, pages: Int)val books = Seq(Book("Future of Scala developers", 85),Book("Parallel algorithms", 240),Book("Object Oriented Programming", 130),Book("Mobile Development", 495))books.maxBy(book => book.pages)//Book(Mobile Development,495)books.minBy(book => book.pages)//Book(Future of Scala developers,85)
如上所示,minBy & maxBy方法解决了复杂数据的问题。你只需选择决定数据最大或最小的属性。
sortBy, sortWith, sorted
sortBy: 按照应用函数f之后产生的元素进行排序
sorted:按照元素自身进行排序
sortWith:使用自定义的比较函数进行排序
val nums = List(1,3,2,4)val sorted = nums.sorted //List(1,2,3,4)val users = List(("HomeWay",25),("XSDYM",23))val sortedByAge = users.sortBy{case(user,age) => age}//List(("XSDYM",23),("HomeWay",25))val sortedWith = users.sortWith{case(user1,user2) => user1._2 < user2._2}//List(("XSDYM",23),("HomeWay",25))
flatten
我想大多数朋友都没听说过这个功能。其实它很好理解,我们来举例说明:
val abcd = Seq('a', 'b', 'c', 'd')val efgj = Seq('e', 'f', 'g', 'h')val ijkl = Seq('i', 'j', 'k', 'l')val mnop = Seq('m', 'n', 'o', 'p')val qrst = Seq('q', 'r', 's', 't')val uvwx = Seq('u', 'v', 'w', 'x')val yz = Seq('y', 'z')val alphabet = Seq(abcd, efgj, ijkl, mnop, qrst, uvwx, yz)alphabet.flatten// List(a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z)
当有一个集合的集合,然后你想对这些集合的所有元素进行操作时,就会用到flatten,即对列表中的列表进行扁平化操作。
map, flatMap
map 是 Scala 集合最常用的一个函数。它的功能十分强大:
val numbers = Seq(1,2,3,4,5,6)//List(2, 4, 6, 8, 10, 12)numbers.map(n => n * 2)val chars = Seq('a', 'b', 'c', 'd')//List(A, B, C, D)chars.map(ch => ch.toUpper)
用Java、Python、C++中的lambda表达式的人应该容易理解,map就仿佛一个循环遍历,遍历集合中的元素并对每个元素调用某个函数。
flatMap: map之后对结果进行flatten。
val text = List("A,B,C","D,E,F")val textMapped = text.map(_.split(",").toList) // List(List("A","B","C"),List("D","E","F"))val textFlattened = textMapped.flatten // List("A","B","C","D","E","F")val textFlatMapped = text.flatMap(_.split(",").toList) // List("A","B","C","D","E","F")
Filter
过滤器,起到在集合中筛选的作用
val numbers = Seq(1,2,3,4,5,6,7,8,9,10)numbers.filter(n => n % 2 == 0) // 找出所有偶数val books = Seq(Book("Future of Scala developers", 85),Book("Parallel algorithms", 240),Book("Object Oriented Programming", 130),Book("Mobile Development", 495))books.filter(book => book.pages >= 120) // 找出页数大于等于120的书
实际上,过滤是一个转换类型的方法,但是比运用 min和 max方法简单。
还有一个与 filter类似的方法是 filterNot,作用顾名思义。
reduce
reduce(op: (A1, A1) => A1): A1:定义一个变换f, f把两个列表的元素合成一个,遍历列表,最终把列表合并成单一元素
val nums = List(1,2,3)val sum1 = nums.reduce((a,b) => a+b) //6val sum2 = nums.reduce(_+_) //6val sum3 = nums.sum //6
reduceLeft, reduceRight
reduceLeft: reduceLeft[B >: A](f: (B, A) => B): B
reduceRight: reduceRight[B >: A](op: (A, B) => B): B
reduceLeft从列表的左边往右边应用reduce函数,reduceRight从列表的右边往左边应用reduce函数。
val nums = List(2.0,2.0,3.0)val resultLeftReduce = nums.reduceLeft(math.pow) // = pow( pow(2.0,2.0) , 3.0) = 64.0val resultRightReduce = nums.reduceRight(math.pow) // = pow(2.0, pow(2.0,3.0)) = 256.0
fold, foldLeft, foldRight
fold: fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 带有初始值的reduce,从一个初始值开始,从左向右将两个元素合并成一个,最终把列表合并成单一元素。
foldLeft: foldLeft[B](z: B)(f: (B, A) => B): B 带有初始值的reduceLeft
foldRight: foldRight[B](z: B)(op: (A, B) => B): B 带有初始值的reduceRight
可以这么写 /: 或者 :\ ,scala做了简化:
def /:[B](z: B)(op: (B, A) => B): B = foldLeft(z)(op)def :\[B](z: B)(op: (A, B) => B): B = foldRight(z)(op)(0/:(1 to 100))(_+_) //5050(1 to 100).foldLeft(0)(_+_) //5050
欧拉图函数(diff, union, intersect)
diff : diff(that: collection.Seq[A]): List[A]保存列表中那些不在另外一个列表中的元素,即从集合中减去与另外一个集合的交集
union : union(that: collection.Seq[A]): List[A] 与另外一个列表进行连结
intersect: intersect(that: collection.Seq[A]): List[A] 与另外一个集合的交集
val nums1 = List(1,2,3)val nums2 = List(2,3,4)val diff1 = nums1 diff nums2 // List(1)val diff2 = nums2.diff(num1) // List(4)val union1 = nums1 union nums2 // List(1,2,3,2,3,4)val union2 = nums2 ++ nums1 // List(2,3,4,1,2,3)val intersection = nums1 intersect nums2 //List(2,3)
distinct
distinct: List[A] 保留列表中非重复的元素,相同的元素只会被保留一次
//List(1, 2, 3, 4, 5, 6, 7, 8, 9)num1.union(num2).distinct
count
count(p: (A) ⇒ Boolean): Int
计算列表中所有满足条件p的元素的个数,等价于 filter(p).length
val nums = List(-1,-2,0,1,2)val plusCnt1 = nums.count( > 0)val plusCnt2 = nums.filter( > 0).length
groupBy, grouped
groupBy : groupBy[K](f: (A) => K): Map[K, List[A]]将列表进行分组,分组的依据是应用f在元素上后产生的新元素
grouped: grouped(size: Int): Iterator[List[A]] 按列表按照固定的大小进行分组
val data = List(("HomeWay","Male"),("XSDYM","Femail"),("Mr.Wang","Male"))val group1 = data.groupBy(_._2)// = Map("Male" -> List(("HomeWay","Male"),("Mr.Wang","Male")),"Female" -> List(("XSDYM","Femail")))val group2 = data.groupBy{case (name,sex) => sex}// = Map("Male" -> List(("HomeWay","Male"),("Mr.Wang","Male")),"Female" -> List(("XSDYM","Femail")))val fixSizeGroup = data.grouped(2).toList// = Map("Male" -> List(("HomeWay","Male"),("XSDYM","Femail")),"Female" -> List(("Mr.Wang","Male")))
span, splitAt, partition
span : span(p: (A) => Boolean): (List[A], List[A])从左向右应用条件p进行判断,直到条件p不成立,此时将列表分为两个列表
splitAt: splitAt(n: Int): (List[A], List[A]) 将列表分为前n个,与,剩下的部分
partition: partition(p: (A) => Boolean): (List[A], List[A])将列表分为两部分,第一部分为满足条件p的元素,第二部分为不满足条件p的元素
val numbers = Seq(3, 7, 2, 9, 6, 5, 1, 4, 2)numbers.partition(n => n % 2 == 0)//(List(2, 6, 4, 2), List(3, 7, 9, 5, 1))numbers.span( _ == 2)//(List(2, 2), List(3, 7, 9, 6, 5, 1, 4))numbers.splitAt(3)//(List(3, 7, 2), List(9, 6,5, 1, 4, 2))
sliding
sliding(size: Int, step: Int): Iterator[List[A]] 将列表按照固定大小size进行分组,步进为step,step默认为1,返回结果为迭代器
val nums = List(1,1,2,2,3,3,4,4)val groupStep2 = nums.sliding(2,2).toList//List(List(1,1),List(2,2),List(3,3),List(4,4))val groupStep1 = nums.sliding(2).toList//List(List(1,1),List(1,2),List(2,2),List(2,3),List(3,3),List(3,4),List(4,4))
scan, scanLeft, scanRight
scan: scan[B >: A, That](z: B)(op: (B, B) => B)(implicit cbf: CanBuildFrom[List[A], B, That]): That
scanLeft: scanLeft[B, That](z: B)(op: (B, A) => B)(implicit bf: CanBuildFrom[List[A], B, That]): That
scanRight: scanRight[B, That](z: B)(op: (A, B) => B)(implicit bf: CanBuildFrom[List[A], B, That]): That
scan由一个初始值开始,从左向右,进行积累的op操作。
scanLeft: 从左向右进行scan函数的操作,scanRight:从右向左进行scan函数的操作
val nums = List(1,2,3)val result = nums.scan(10)(_+_)// List(10,10+1,10+1+2,10+1+2+3) = List(10,11,12,13)val nums = List(1.0,2.0,3.0)val result = nums.scanLeft(2.0)(math.pow)// List(2.0,pow(2.0,1.0), pow(pow(2.0,1.0),2.0),pow(pow(pow(2.0,1.0),2.0),3.0)) = List(2.0,2.0,4.0,64.0)val result = nums.scanRight(2.0)(math.pow)// List(2.0,pow(3.0,2.0), pow(2.0,pow(3.0,2.0)), pow(1.0,pow(2.0,pow(3.0,2.0)))) = List(1.0,512.0,9.0,2.0)
take,takeRight,takeWhile
take : takeRight(n: Int): List[A] 提取列表的前n个元素
takeRight: takeRight(n: Int): List[A] 提取列表的最后n个元素
takeWhile: takeWhile(p: (A) => Boolean): List[A]从左向右提取列表的元素,直到条件p不成立
val nums = List(1,1,1,1,4,4,4,4)val left = nums.take(4) // List(1,1,1,1)val right = nums.takeRight(4) // List(4,4,4,4)val headNums = nums.takeWhile( _ == nums.head) // List(1,1,1,1)
drop, dropRight, dropWhile
drop: drop(n: Int): List[A] 丢弃前n个元素,返回剩下的元素
dropRight: dropRight(n: Int): List[A] 丢弃最后n个元素,返回剩下的元素
dropWhile: dropWhile(p: (A) ⇒ Boolean): List[A] 从左向右丢弃元素,直到条件p不成立
val nums = List(1,1,1,1,4,4,4,4)val left = nums.drop(4) // List(4,4,4,4)val right = nums.dropRight(4) // List(1,1,1,1)val tailNums = nums.dropWhile( _ == nums.head) // List(4,4,4,4)
slice
slice(from: Int, until: Int): List[A] 提取列表中从位置from到位置until(不含该位置)的元素列表
val nums = List(1,2,3,4,5)val sliced = nums.slice(2,4) //List(3,4)
forall
确保集合中所有元素都要符合某些要求,如果有哪怕一个元素不符合条件,就需要进行一些处理:
val numbers = Seq(3, 7, 2, 9, 6, 5, 1, 4, 2)numbers.forall(n => n < 10)//turenumbers.forall(n => n > 5)//false
而 forall 函数就是为处理这类需求而创建的。
combinations, permutations
combinations: combinations(n: Int): Iterator[List[A]] 取列表中的n个元素进行组合,返回不重复的组合列表,结果一个迭代器
permutations: permutations: Iterator[List[A]] 对列表中的元素进行排列,返回不重得的排列列表,结果是一个迭代器
val nums = List(1,1,3)val combinations = nums.combinations(2).toList//List(List(1,1),List(1,3))val permutations = nums.permutations.toList// List(List(1,1,3),List(1,3,1),List(3,1,1))
updated
updated(index: Int, elem: A): List[A] 对列表中的某个元素进行更新操作
val nums = List(1,2,3,3)val fixed = nums.updated(3,4) // List(1,2,3,4)
参考资料
MUTABLE AND IMMUTABLE COLLECTIONS
:不建议大家看中文版,那个中文版的翻译是机译,根本没法读。
- Scala之集合Collection
- Scala强大的集合数据操作代码示例


































还没有评论,来说两句吧...