python网页解析器--BeautifulSoup
1.python中的网页解析器是做什么的
所谓的网页解析器就是剖析网页元素的工具,简单来说,就是可以从html网页,解析出自己所需要查找的数据的工具(这里的数据可以是一个网页链接的地址,也可以是单纯的数据信息)。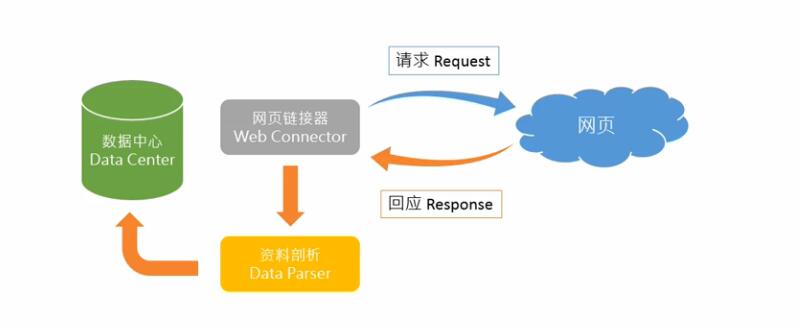
这里的资料剖析,就是当网页反馈信息后,我们所进行剖析的数据,然后将所需要的数据存入数据中心。(需要会使用浏览器的开发者工具)
2.BeautifulSoup网页解析器
BeautifulSoup是python的第三方库,也是网页解析器的一种。
常见的网页解析器有:正则匹配,html.parser模块,BeautifulSoup,lxml。
BeautifulSoup是结构化解析,将剖析出来的数据进行从非结构化数据转化为结构化数据,是通过DOM树结构为标准,将网页数据进行转化提取。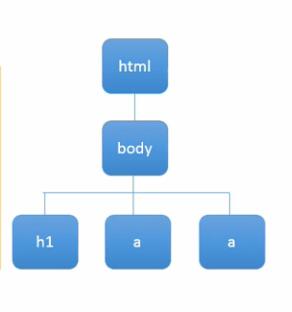
上图就是DOM结构,将正常的网页源码,通过各个标签,解决该层次,然后通过一层一层的遍历,获取我们所需要的信息。
3.BeautifulSoup的基本操作
这里的库需要安装的是BeautifulSoup4,它与BeautifulSoup的库不一样。
(1)创建BeautifulSoup对象:
#首先导入BeautifulSoup的方法from bs4 import BeautifulSoup#将需要获取该段数据的网页源码存放入divdiv='\<div class="nav_com"> \<ul> \<h1 id="active"><a href="/">推荐</a></h1> \<li class=""><a href="/nav/news">资讯</a></li> \<li class=""><a href="/nav/ai">人工智能</a></li> \<li class=""><a href="/nav/cloud">云计算/大数据</a></li> \<li class=""><a href="/nav/blockchain">区块链</a></li>\<li class=""><a href="/nav/db">数据库</a></li>\<li class=""><a href="/nav/career">程序人生</a></li>\<li class=""><a href="/nav/game">游戏开发</a></li>\<li class=""><a href="/nav/engineering">研发管理</a></li>\<li class=""><a href="/nav/web">前端</a></li>\<li class=""><a href="/nav/mobile">移动开发</a></li>\<li class=""><a href="/nav/iot">物联网</a></li>\<li class="nav_more"><a href="/nav/ops">运维</a></li>\</ul>\</div>'#创建BeautifulSoup对象soup=BeautifulSoup(div,'html.parser')#div是上面赋源码的对象#html.parser是一个html解析器#然后通过BeautifulSoup方法赋给soup对象#输出soup中的内容print(soup.text)#如果是只输出soup对象,soup对象是一段源码#print(soup)
结果如下图:

(2)获取标签的内容
#使用select获取(li)标签数组的值content = soup.select('li')#由于content是列表形式,所以可以按照数组的结构,获取该内容的第一个,或者某个值content1=content[0]print(content1.text)
结果如下图:

(3)可将该列表中的值循环输出
#循环输出content中的内容for line in content:print(line.text)
结果如下图:

(4)也可以获取网页中id或者class元素
#使用select找出网页中id为active的元素(id前面需要加#)line=soup.select('#active')print(line)#使用select找出网页中class为nav_more的元素(前面需要加#class.)line1=soup.select('.nav_more')print(line1)
结果如下图:

(5)获取a标签中的href地址
#使用select找出所有a tag的href的连接网页href =soup.select('a')for linx in href:print(linx)print(linx['href'])
结果如下图:



























littleVGL LVGL 控件学习 Arc 弧形控件")

——遗传算法的基本实现技术")




还没有评论,来说两句吧...