一致性哈希
首先我们可以看看为什么需要一致性哈希算法。
假设我们有3台Redis缓存服务器,编号为0,1,2.现在我们想将3万张图片均匀的缓存存到这3台服务器上。因为不想在缓存中找某张图片时去遍历3台服务器,所以我们原始的做法是对缓存项的键进行哈希,将哈希后的结果对服务器的数量进行取模操作。
hash(图片名称) % 3
这样当我们访问任意一张图图片时,就能快速的找出该图片被缓存在哪个服务器上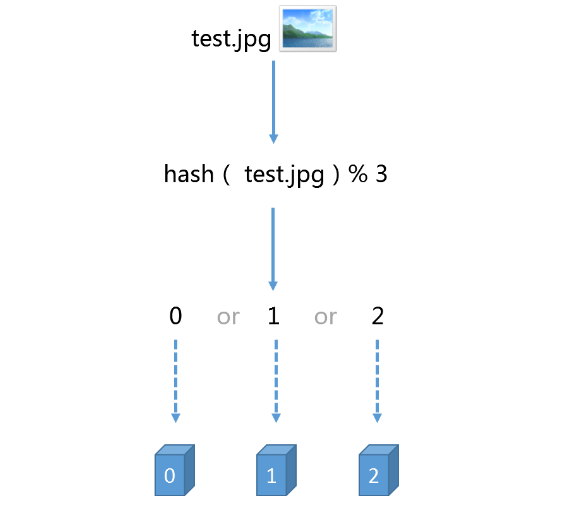
但是当我们需要增加服务器,或者一个缓存服务器突然出现故障时,服务器的数量就改变了,这么取余的结果肯定会发生变化。这样带来的后果就是所有缓存的位置都会发生变化,造成缓存的崩溃,引起整体体统压力过大崩溃。
这时候就引入了一致性哈希算法。
一致性哈希
一致性哈希也是使用取模的方法,只不过是对2^32取模。
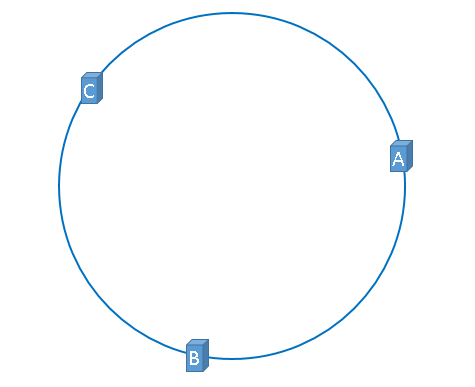
我们把2的32次方想象成一个圆,和钟表一样,如图
正上方的点代表成0,一直到2^32-1. 这个环就是hash环。
然后我们三台服务器的IP地址进行哈希计算,再对2^32取模,映射到环上。
hash(服务器A的IP地址) % 2^32hash(服务器B的IP地址) % 2^32hash(服务器C的IP地址) % 2^32
我们再将4张图片也通过同样的方法映射到哈希环上
hash(图片1的名字) % 2^32hash(图片2的名字) % 2^32hash(图片3的名字) % 2^32hash(图片4的名字) % 2^32
然后通过顺时针方向,遇到的第一个服务器就将图片缓存到服务器上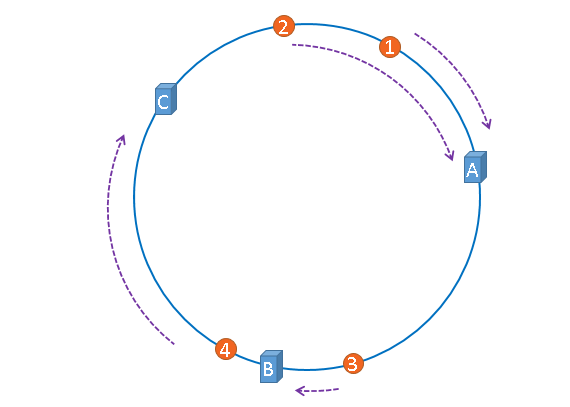
图片1、2缓存到A ,图片3缓存到B,图片4缓存到C。
一致性哈希的优点
假设服务器B出现了问题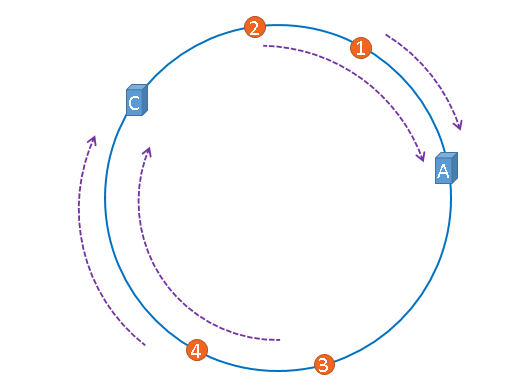
那么只有图片3改变然后就会被缓存到C中,之前如果一台服务器故障,所有的缓存都会失效,而使用一致性哈希算法,只有部分的图片(图片3)缓存会失效。
一点小问题
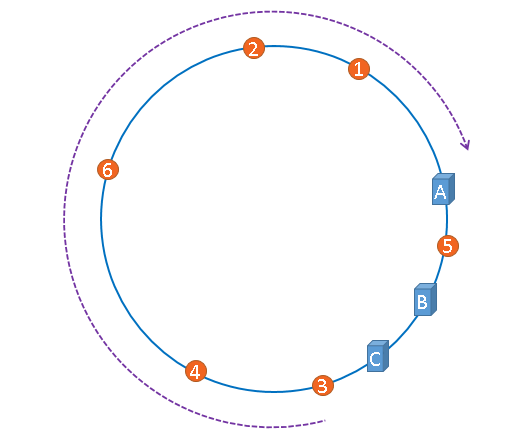
但是现实中可能会出现这样的问题,1、2、3、4、6号图片全部被缓存到了同一个服务器上,这样资源分布是极度不均匀的。
虚拟节点
只要让服务器的数量更多,哈希环就会更均匀。但真正的服务器资源只有3台,该怎么办呢?
我们只能将现有的物理节点通过虚拟的方式复制出来。这些被复制出来的节点就是“虚拟节点”。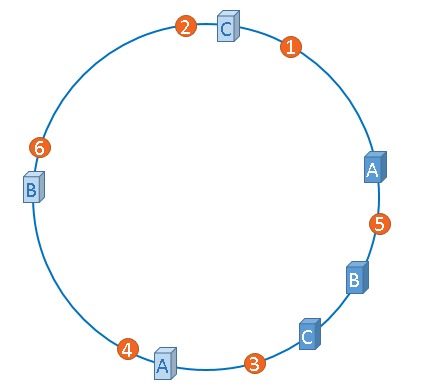
创造出虚拟节点之后,缓存的分布就均匀多了。Hash环上的节点越多,均匀分布的概率越大。



























")


")


还没有评论,来说两句吧...