快速幂和矩阵快速幂
前言
新年第一篇技术类的文章,应该算是算法方面的文章的。看标题:快速幂和矩阵快速幂,好像挺高大上。其实并不是很难,快速幂就是快速求一个数的幂(一个数的 n 次方)。
快速幂
首先,来看一下幂,我们知道,假设有一个整数 x, 如果我们要求出 x^n (即为 x 的 n 次方)的值,最容易想到的办法就是循环相乘(这里不考虑整数溢出的情况下),于是我们很容易就可以写出下面的代码:
int res = 1;for (int i = 0; i < n; i++) {res *= x;}
咋一看,嗯,很正常的代码。确实是挺正常的代码,其时间复杂度为 O(n)。其实这个问题的时间复杂度可以降到 O(logn) 。那么问题来了,怎么做到的? 其实,就是通过快速幂的方法。
先来举个例子:假设我们现在要求出 5^9 的值,不用我们刚刚直接循环的方法,换种思维,我们可以这样看:
5^9 = 5*5^8 = 5*((5^4)^2) = 5*(5^4)*(5^4)5^4 = ((5^2)^2) = (5^2)*(5^2)5^2 = 5*5
如果当前的指数是偶数,我们把指数拆成两半,得到两个相同的数,然后把这两个相同的数相乘,可以得到原来的数;
如果当前的指数是奇数,我们把指数拆成两半,得到两个相同的数,此时还剩余一个底数,把这两个相同的数和剩余的底数这三个数相乘,可以得到原来的数。
那么如果说我们按照这种思路去计算 5^9 的值的话,我们会发现只需要执行 3 次计算。相比原来的直接用循环的 9 次计算,正好是 log9 的整数部分值。Ok,那么怎么用代码写出来呢?这里先给出代码,再做解释:
/*** 计算 x^n 的值,并将结果保存在 res 中*/long long res = 1;// 进行快速幂运算,n 为当前的指数值,n 为 0 的时候运算结束while (n) {// 用位运算的方式判断 n 是否为奇数,速度更快,等价于 n%2if (n & 1) {// 如果 n 是奇数,那么需要将 x 存入运算结果中res *= x;}// 更新当前的 x 的值x *= x;// 用位运算的方式进行 n/2,速度更快,等价于 n/=2n >>= 1;}
首先,我们注意到,不管当前的指数值(n 的值)是奇数还是偶数,一次运算之后 n 都要拆成两半(n /= 2),所以,我们在每次运算的时候都要让当前的 x *= x ,也就是执行 x = x^2,这点相信不难理解。
第二,当 n 为奇数的时候,如果执行 n /= 2,结果会使得 n 损失一个 1。举个例子:假设此时 n = 9,9 / 2 = 4 ,即使我们之后会执行 x *= x,也只是把 n 的一半 (4) 补回来了,还少了个 1 (4+4+1 = 9)。因此此时要把少了的那一个 x 存入结果中,即为执行 res *= x;
第三,只要 n 的初始值是大于 0 的(其余的数需要特殊处理),那么在运算过程中一直执行 n >>= 1,也就是将 n 除以 2 ,n 是一定会等于 1 的,此时执行 res *= x,将最后的结果保存在 res 中,之后退出循环。
最后,整个循环每一次执行 n 都变成原来的一半,当 n 等于 0 的时候结束,时间复杂度为 O(logn)
这里给出一个快速幂的完整代码:
/*** Describe:实现快速幂* Author:指点* Date:2018/1/24*/#include <iostream>#include <cstdlib>using namespace std;// 使用快速幂求出 x^n 的值并返回,不考虑高精度,请控制参数范围double myPow(double x, int n) {// 任何不是 0 的数的 0 次幂为 1if (x && n == 0) {return 1;} else if (x == 0 && n == 0) {exit(1);}// 如果 n 是负数,那么返回结果要进行处理bool nIsNegative = false;if (n < 0) {nIsNegative = true;n = -n;}double res = 1;while (n) {// 用位运算的方式判断 n 是否为奇数,速度更快,等价于 n%2if (n & 1) {res *= x;}x *= x;// 用位运算的方式进行 n/2,速度更快,等价于 n/=2n >>= 1;}// n 是负数?1.0/res 否则 resreturn nIsNegative ? 1.0/res : res;}int main() {double x;int n;while (cin >> x >> n) {cout << myPow(x, n) << endl << endl;}return 0;}
来看看结果:
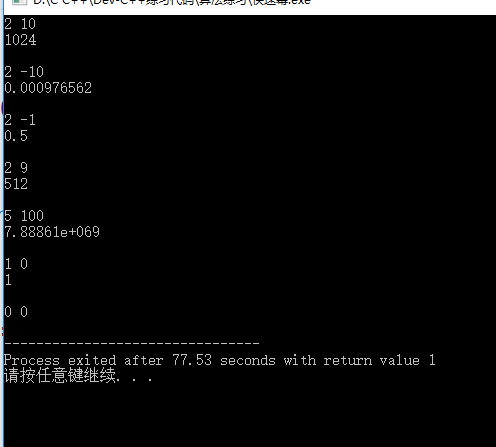
理解了上面的几点,相信快速幂就难不到你了。下面来看看矩阵快速幂:
矩阵快速幂
其实矩阵快速幂的思想是和快速幂一样的,矩阵快速幂是用于快速求出一个矩阵的 n 次方的方法。
首先,我们要知道,两个矩阵能不能相乘是有一定条件的:
假设有两个矩阵 A, B。如果矩阵 A 的列数等于矩阵 B 的行数,那么这两个矩阵才可以进行相乘,否则这两个矩阵是不能相乘的。
对于这里,我们要求的是一个矩阵的 n 次方,那么既然是同一个矩阵,那么只有当其为方阵(行数和列数相同的矩阵)的时候,才可以相乘。矩阵相乘结果也是一个矩阵,具体的规则为:如果矩阵 A 的列数等于矩阵 B 的行数,假设矩阵 C = A*B, 那么矩阵 C 的行数和矩阵 A 的行数相等,矩阵 C 的列数和矩阵 B 相等。矩阵 C 的第一行第一列元素等于矩阵 A 的第一行的元素和矩阵 B 的第一列的元素依次相乘再求和。矩阵 C 的第一行第二列元素等于矩阵 A 的第一行的元素和矩阵 B 的第二列的元素依次相乘再求和。。。。。。矩阵 C 的第 n 行第 m 列元素等于矩阵 A 的第 n 行的元素和矩阵 B 的第 m 列的元素依次相乘再求和。依次类推。
这里给出一个求出两矩阵相乘的结果的函数:
// 计算矩阵 a(m*s 规模) 和矩阵 b(s*n 规模) 相乘的结果,并将结果返回int **matrixMultiply(int **a, int **b, int m, int s, int n) {// 初始化储存结果的数组int **result = new int*[m];for (int i = 0; i < m; i++) {result[i] = new int[n];memset(result[i], 0, sizeof(int)*n);}// 进行矩阵相乘计算for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {for (int k = 0; k < s; k++) {result[i][j] += a[i][k]*b[k][j];}}}return result;}
这里用的是二级指针作为参数和返回值来表示对应的矩阵。来测试一下这个函数:
/*** Describe:实现矩阵相乘* Author:指点* Date:2018/1/24*/#include <iostream>#include <cstring>using namespace std;// 计算矩阵 a(m*s 规模) 和矩阵 b(s*n 规模) 相乘的结果,并将结果返回int **matrixMultiply(int **a, int **b, int m, int s, int n) {// 初始化储存结果的数组int **result = new int*[m];for (int i = 0; i < m; i++) {result[i] = new int[n];memset(result[i], 0, sizeof(int)*n);}// 进行矩阵相乘计算for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {for (int k = 0; k < s; k++) {result[i][j] += a[i][k]*b[k][j];}}}return result;}int main() {int m = 2, s = 3, n = 2;// 初始化 a 、b 两个矩阵int **a = new int*[m];for (int i = 0; i < m; i++) {a[i] = new int[s];}int **b = new int*[s];for (int i = 0; i < s; i++) {b[i] = new int[n];}cout << "a 矩阵:" << endl;for (int i = 0; i < m; i++) {for (int j = 0; j < s; j++) {a[i][j] = i + j;cout << a[i][j] << " ";}cout << endl;}cout << "b 矩阵:" << endl;for (int i = 0; i < s; i++) {for (int j = 0; j < n; j++) {b[i][j] = i + j;cout << b[i][j] << " ";}cout << endl;}int **res = matrixMultiply(a, b, 2, 3, 2);// 结果是一个 2 行 2 列的数组cout << "相乘的结果矩阵:" << endl;for (int i = 0; i < 2; i++) {for (int j = 0; j < 2; j++) {cout << res[i][j] << " ";}cout << endl;}// 释放申请的内存空间if (a != NULL) {for (int i = 0; i < m; i++) {delete[] a[i];}delete[] a;a = NULL;}if (b != NULL) {for (int i = 0; i < s; i++) {delete[] b[i];}delete[] b;b = NULL;}if (res != NULL) {for (int i = 0; i < m; i++) {delete[] res[i];}delete[] res;res = NULL;}return 0;}
来看一下结果:
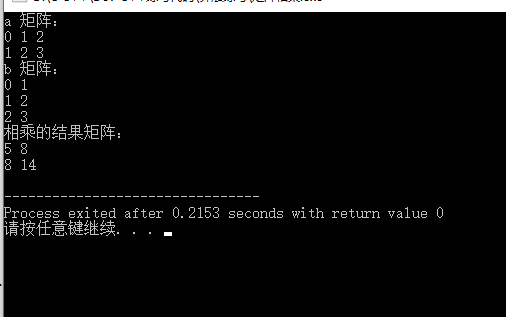
Ok,给定数据测试正确,有了这个函数,我们写矩阵快速幂的代码就简单了,我们把矩阵看成一个数,矩阵乘法的函数我们已经写好了,那么我们仿照快速幂的写法,实现矩阵快速幂:
/*** Describe:实现矩阵快速幂* Author:指点* Date:2018/1/24*/#include <iostream>#include <cstring>using namespace std;// 删除数组空间的函数,数组行数:mvoid deleteArray(int **a, int m) {if (a != NULL) {for (int i = 0; i < m; i++) {delete[] a[i];}delete[] a;a = NULL;}}// 计算矩阵 a(m*s 规模) 和矩阵 b(s*n 规模) 相乘的结果,并将结果返回int **matrixMultiply(int **a, int **b, int m, int s, int n) {// 初始化储存结果的数组int **result = new int*[m];for (int i = 0; i < m; i++) {result[i] = new int[n];memset(result[i], 0, sizeof(int)*n);}// 进行矩阵相乘计算for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {for (int k = 0; k < s; k++) {result[i][j] += a[i][k]*b[k][j];}}}return result;}// 用快速幂求出矩阵 a(m*m 规模,只有方阵才可以自我相乘) 的 n 次方,并将结果返回int **myMatrixPow(int **a, int m, int n) {// 初始化保存结果的矩阵int **res = new int*[m];for (int i = 0; i < m; i++) {res[i] = new int[m];memset(res[i], 0, sizeof(int)*m);// 保存结果的矩阵初始应该是一个单位矩阵(正向斜对角线值为 1,其余为 0)res[i][i] = 1;}// 保存要删除的数组空间的指针int **oldPoint = NULL;while (n) {if (n & 1) {// 保存 res 指针当前的内存地址oldPoint = res;// res 指向储存矩阵相乘结果的数组的地址res = matrixMultiply(res, a, m, m, m);// 删除 res 指针原有的内存空间deleteArray(oldPoint, m);}// 保存 a 指针当前的内存地址oldPoint = a;// a 指向储存矩阵相乘结果的数组的地址a = matrixMultiply(a, a, m, m, m);// 删除 a 指针原有的内存空间deleteArray(oldPoint, m);n >>= 1;}return res;}int main() {int m = 2;// 初始化 a 方阵int **a = new int*[m];for (int i = 0; i < m; i++) {a[i] = new int[m];}cout << "a 矩阵:" << endl;for (int i = 0; i < m; i++) {for (int j = 0; j < m; j++) {a[i][j] = i + j;cout << a[i][j] << " ";}cout << endl;}cout << endl;for (int i = 0; i < 10; i++) {// 计算结果int **res = myMatrixPow(a, m, i);cout << "a 矩阵的 " << i << " 次方计算结果:" << endl;for (int i = 0; i < 2; i++) {for (int j = 0; j < 2; j++) {cout << res[i][j] << " ";}cout << endl;}// 释放 res 指针的内存空间deleteArray(res, m);}// 最后释放 a 指针的内存空间deleteArray(a, m);return 0;}
关键函数就是 myMatrixPow ,我想有了快速幂的基础,这个函数也不难理解了。代码里面有较多的指针操作,所以专门写了一个函数 deleteArray 来释放程序运行过程中所申请的堆内存空间,其实不主动释放,等程序结束后让操作系统回收也是可以的,不过个人有点强迫症…..哈哈。看代码不难理解利用矩阵快速幂求方阵的幂的时间复杂度为O(m^3*logn),m为方阵的行数和列数(方阵相乘的复杂度为 O(m^3),快速幂的复杂度为 O(logn) )。
好了, 来看一下结果:
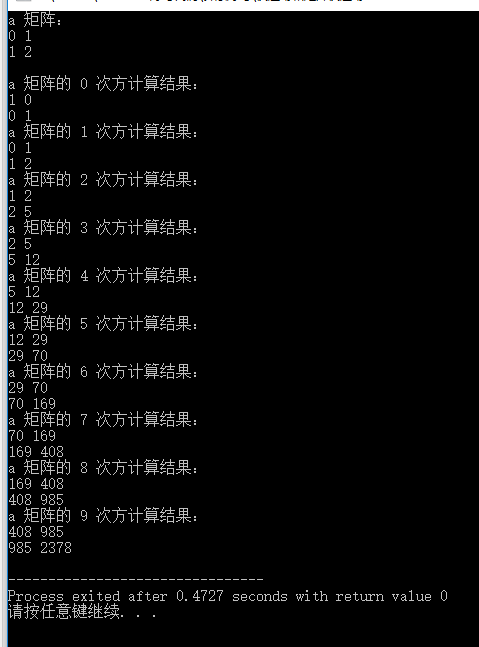
如果有兴趣的话,你可以自己验算一下结果的正确性。
应用
那么看了这么多,快速幂有啥子用呢?
首先对于求一个数的 n 次方,可以用 O(logn) 的时间复杂度来求出结果,这肯定是一个用途,那么矩阵快速幂呢?
不知道你还记不记得斐波那契数列的递推公式,斐波那契数列的递推公式可以写成:
如果 n > 2,那么 f(n) = f(n-1) + f(n-2);如果 n = 2 或者 n = 1,那么 f(n) = 1
那么如果现在要求 f(n) 的值呢,根据递推公式我们可以很快的写出下面的代码(不考虑整数溢出的情况):
typedef long long ll;ll getFibo(int n) {if (n == 1 || n == 2) {return 1;}return getFibo(n-1) + getFibo(n-2);}
这个代码的时间复杂度大约是 O(2^n),其执行过程就是一颗二叉树,里面进行了很多的重复运算。
当然也有循环版本的(不考虑整数溢出的情况):
typedef long long ll;ll getFibo(int n) {ll first = 1, second = 1, res = 0;for (int i = 3; i <= n; i++) {res = first + second;first = second;second = res;}return res;}
这个代码的时间复杂度为 O(n),比递归的方法好。
这两种方法都可以求解,但是可以有更高效的方法,就是利用矩阵快速幂。
不过咋一看这怎么和矩阵快速幂联系到一起呢?要用矩阵快速幂,我们得先有矩阵:
假设我们现在有一个一行两列的矩阵:A【f(n-2), f(n-1)】,我们设定一个 2*2 的矩阵 T,使得矩阵 A*T 相乘的结果等于另外一个一行两列的矩阵 C:【f(n-1), f(n)】。
我们根据给定条件和斐波那契的递推公式可以很容易构造出矩阵 T:
0 1
1 1
构造过程就是矩阵 A*T 的计算过程:
【f(n-2)*0 + f(n-1)*1 = f(n-1), f(n-2)*1 + f(n-1)*1 = f(n)】
Ok,那么我们知道 【f(n-2), f(n-1)】* T = 【f(n-1), f(n)】,
那么可以推出:【f(n-3), f(n-2)】* T*T = 【f(n-1), f(n)】,【f(n-4), f(n-3)】* T*T*T = 【f(n-1), f(n)】…….
也就是:【f(1), f(2)】 * T^(n-2) = 【f(n-1), f(n)】,
f(1)=1, f(2)=1, 也就是:【1, 1】*T^(n-2) = 【f(n-1), f(n)】
现在在看一下我们是不是有了 T^(n-2) 这个矩阵求幂的条件,那么我们就可以用矩阵快速幂来求解这道题了:
/*** Describe:利用矩阵快速幂求斐波那契数列的第 n 项值* Author:指点* Date:2018/1/24*/#include <iostream>#include <cstring>using namespace std;typedef long long ll;// f(1) 和 f(2) 的值const ll START[] = {1, 1};// 矩阵 Tll **T = NULL;// 删除数组空间的函数,数组行数:mvoid deleteArray(ll **a, int m) {if (a != NULL) {for (int i = 0; i < m; i++) {delete[] a[i];}delete[] a;a = NULL;}}// 计算矩阵 a(m*s 规模) 和矩阵 b(s*n 规模) 相乘的结果,并将结果返回ll **matrixMultiply(ll **a, ll **b, int m, int s, int n) {// 初始化储存结果的数组ll **result = new ll*[m];for (int i = 0; i < m; i++) {result[i] = new ll[n];memset(result[i], 0, sizeof(ll)*n);}// 进行矩阵相乘计算for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {for (int k = 0; k < s; k++) {result[i][j] += a[i][k]*b[k][j];}}}return result;}// 求出矩阵 a(m*m 规模,只有方阵才可以自我相乘) 的 n 次方,并将结果返回ll **myMatrixPow(ll **a, int m, int n) {// 初始化保存结果的矩阵ll **res = new ll*[m];for (int i = 0; i < m; i++) {res[i] = new ll[m];memset(res[i], 0, sizeof(ll)*m);// 保存结果的矩阵初始应该是一个单位矩阵(正向斜对角线值为 1,其余为 0)res[i][i] = 1;}// 保存要删除的数组空间的指针ll **oldPoint = NULL;while (n) {if (n & 1) {// 保存 res 指针当前的内存地址oldPoint = res;// res 指向储存矩阵相乘结果的数组的地址res = matrixMultiply(res, a, m, m, m);// 删除 res 指针原有的内存空间deleteArray(oldPoint, m);}// 保存 a 指针当前的内存地址oldPoint = a;// a 指向储存矩阵相乘结果的数组的地址a = matrixMultiply(a, a, m, m, m);// 删除 a 指针原有的内存空间deleteArray(oldPoint, m);n >>= 1;}return res;}// 求出斐波那契数列的第 n 项的值,不考虑整数溢出,请控制数字范围ll getFibo(int n) {if (n == 1 || n == 2) {return 1;}ll res = 0;// 求出 T 矩阵的 n-2 次方(T^n-2)的值,并将结果保存在 T 指针中T = myMatrixPow(T, 2, n-2);// 求出最后的 f(n) 的值(res += START[i]*T[i][0] 为 f(n-1) 的值,res += START*T[i][1] 为 f(n) 的值)for (int i = 0; i < 2; i++) {res += START[i]*T[i][1];}return res;}int main() {// 初始化矩阵 T,元素值通过计算求得T = new ll*[2];T[0] = new ll[2];T[1] = new ll[2];for (int i = 1; i < 80; i++) {/*** 矩阵 T 元素值:* 0 1* 1 1*/T[0][0] = 0;T[0][1] = T[1][0] = T[1][1] = 1;cout << "第" << i << "项斐波那契数列的值:";cout << getFibo(i) << endl;}deleteArray(T, 2);return 0;}
和矩阵快速幂差不多的代码,如果你理解了矩阵快速幂的思想的话,我想这代码也很好理解,这里我们可以看到,用这种方法求斐波那契数列的时间复杂度约为 O(2^3*logn),也就是求矩阵的幂的时间复杂度。忽略常数,即为O(logn)。
有图有真相,最后来看一下结果:
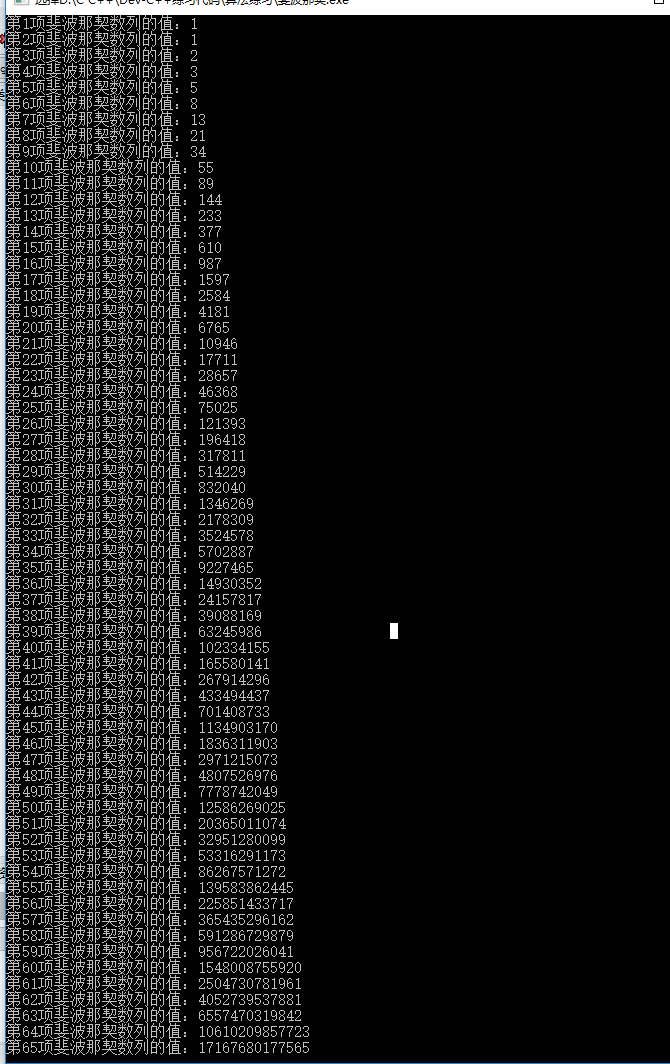
其实类似于斐波那契数列这种利用递推式来求值的问题都可以通过矩阵快速幂来解决,这其中主要的问题就是怎么构造那个矩阵。关于这点,可以参考下这篇文章:
http://www.cnblogs.com/frog112111/archive/2013/05/19/3087648.html
如果说练习题的话,可以试试下面的:
http://poj.org/problem?id=3070
http://lx.lanqiao.cn/problem.page?gpid=T396()
Ok,如果博客中有什么不正确的地方,请多多指点,如果觉得本文对您有帮助,请不要吝啬您的赞。
谢谢观看。。。



























(搜索一)")

——系统分区与格式化")
——设备文件名与挂载")



还没有评论,来说两句吧...