Lucene 深入学习(2)Lucene简介
前言: Lucene和信息检索有什么关系,它又有着哪些独特之处?本节着重介绍Lucene的基本知识。
Lucene是什么
Lucene是Apache软件基金会Jakarta项目的一个子项目,它是开源、免费、纯Java语言的全文检索工具包。它的原作者Doug Cutting是以为资深的全文检索专家,曾主导了某搜索引擎的研发工作。
Lucene的优势
Lucene能够如此流行跟它的一些优点是分不开的:
- 索引文件格式跨平台:Lucene定义了一套以8位字节为基础的索引文件格式,使得不同平台的应用能够兼容。
- 以倒排索引为基础的分块索引:分块索引可以对新的文件建立小文件索引,提升索引速度,然后通过与原有索引的合并,达到优化的目的。
- 面向对象的系统架构:Lucene基于Java语言,而该语言的使用者众多,上手难度相对较低。
- 独立语言的分析接口:无论是什么语言,只要实现自己的文本分析器,就可以使用。便于用户扩展新的语言。
- 默认实现了查询引擎:Lucene默认实现了布尔查询,模糊查询,分组查询等,用户可以方便地使用查询功能。
Lucene的相关产品
Compass
Campass 是对Lucene搜索引擎在企业应用中的增强。它结合了像Hibernate和Spring等流行的框架,使得在Java程序中使用搜索引擎变得更为容易。
Nutch
Nutch是一个建立在Lucene核心之上的Web搜索的实现,它在lucene的基础上加了网络爬虫和相关的界面部分,使得整个搜索引擎能正常工作。
Solr
Solr是一个高性能,基于Lucene实现的全文搜索服务器。可以通过Http请求来完成查询工作,其上手难度小,检索性能优,是企业中使用广泛。
ElasticSearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了分布式的能力使得其更加稳定,可靠,是当前流行的企业级搜索引擎。
Lucene系统结构
Lucene系统由基础封装类,核心搜索类,对外接口三大部分组成。
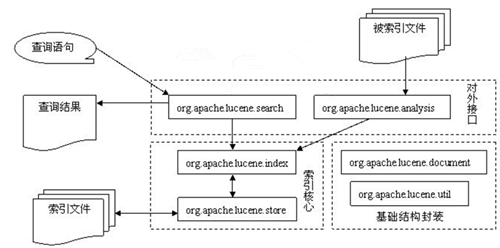
目前最新的Lucene已经更新到7.x,但是大部分公司还在使用较低的版本。以我们在用的Lucene 6.0.0版本为例,lucene主要有如下几个包:
| 包名 | 描述 |
|---|---|
| org.apache.lucene.analysis | 语言分析器,主要用做分词 |
| org.apache.lucene.codecs | 提供了一个抽象的编码个解码的倒排索引结构 |
| org.apache.lucene.document | 管理索引存储时的文档结构 |
| org.apache.lucene.index | 负责索引的创建与删除等 |
| org.apache.lucene.search | 用于处理用户的查询请求 |
| org.apache.lucene.store | 提供对索引存储的支持 |
| org.apache.lucene.util | 包含了一些有用的数据结构和工具类 |
Lucene 主要逻辑图
Lucene提供了强大的全文检索功能,从功能上做拆分,有可以分为如下两块:
- 文本索引:使用分词器对文本资源进行切分,然后存入索引库。
- 条件查询:根据用户的查询请求,去索引库找出符合条件的信息。
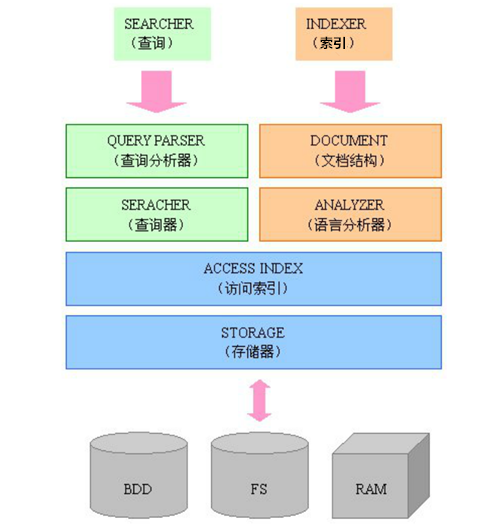
Lucene 的查询逻辑
AND
当两个查询条件都满足时,才认为匹配。例如Tom AND Jerry表示文档中都有Tom和Jerry时才返回。
OR
两个查询条件只要有一个满足,就认为匹配。例如Tom OR Jerry表示文档中含有Tom或者Jerry或者同时存在时才返回。
NOT
表示排除某个查询条件。例如Tom NOT Jerry表示文档中含有Tom并且没有Jerry时才返回。
通配符 ? *
Lucene支持简单的通配符查询,例如?匹配单个字符,*匹配零个或多个字符。
例如To? 可以查询出’Too’、’Tom’等,To* 可以查询出’To’、’Tomas’等。
Lucene的查询逻辑看起来很简单,也比较容易理解。这里给出的是其中一部分,在实际运用中,往往会结合使用多种查询逻辑。默认情况下,Lucene只支持英文,因此演示的内容以英文为主,之后会使用到中文分词器,让Lucene支持中文。

























--语言")



")
派系过滤算法")


还没有评论,来说两句吧...