Nginx+Tomcat集群故障迁移实现
前几天在面试阿里的时候面试官问这么一个问题:
在Nginx+Tomcat的负载均衡场景中,如果某台服务器意外宕机的时候,Nginx对于将要分发到这台服务器的处理策略是怎么样的?
笔者当时这个问题没有回答后,面试介绍后马上做了实验并查询了相关的Nginx的负载均衡的配置项。
先搭建出Nginx+Tomcat的环境
这个比较简单,负载均衡算法指定为轮循法,Tomcat为了启动方便使用Spring Boot内嵌的Tomcat。
Tomcat一号机,端口server.port=8080
@SpringBootApplication@RestControllerpublic class App {@RequestMapping("/set")public String home(HttpServletRequest request) {return "One!"+new Date();}public static void main(String[] args) {SpringApplication.run(App.class, args);}}
Tomcat二号机,端口server.port=9090
tomcat二号机需要模拟一个内存溢出的场景
启动时指定JAVA_OPTS=”-Xms32M -Xmx64M”如果在intellij中则在editConfiguration中修改。
@SpringBootApplication@RestControllerpublic class App{static HashMap<String,String> map = new HashMap<String,String>();@RequestMapping("/set")public String home(HttpServletRequest request) {new Thread(){@Overridepublic void run(){StringBuilder s = new StringBuilder();while (s.length()<50){s.append(new Random().nextInt());}for (int i=0;i<500000;i++){map.put(String.valueOf(1000000+i),s.toString());}}}.start();return "Two! Yes";}public static void main(String[] args) {SpringApplication.run(App.class, args);}}
Nginx的配置:
修改/etc/nginx/sites-enabled
upstream webservers{server 192.168.0.101:8080 weight=1;server 192.168.0.101:9090 weight=1;}location / {proxy_pass http://webservers;}
上述的Nginx配置完成了一个最简单的配置,没有任何附加参数。
通过Nginx输出日志配置
修改nginx.conf如下,对access.log修改输出格式:
log_format main '$remote_addr - $remote_user [$time_local] ''fwf[$http_x_forwarded_for] tip[$http_true_client_ip] ''$upstream_addr $upstream_response_time $request_time ''$geoip_country_code ''$http_host $request ''"$status" $body_bytes_sent "$http_referer" ''"$http_accept_language" "$http_user_agent" ';access_log /var/log/nginx/access.log main;error_log /var/log/nginx/error.log;
关于Nginx日志的配置简单描述一下:
语法: log_format name string …;
默认值: log_format combined “…”;
配置段: http
name表示格式名称,string表示等义的格式。log_format有一个默认的无需设置的combined日志格式,相当于apache的combined日志格式,如下所示:
log_format combined '$remote_addr - $remote_user [$time_local] '' "$request" $status $body_bytes_sent'' "$http_referer" "$http_user_agent" ';
- $
remote_addr,$http_x_forwarded_for记录客户端IP地址- $
remote_user记录客户端用户名称- $
request记录请求的URL和HTTP协议- $
status记录请求状态- $
body_bytes_sent发送给客户端的字节数,不包括响应头的大小; 该变量与Apache模块mod_log_config里的“%B”参数兼容。- $
bytes_sent发送给客户端的总字节数。- $
connection连接的序列号。- $
connection_requests当前通过一个连接获得的请求数量。- $
msec日志写入时间。单位为秒,精度是毫秒。- $
pipe如果请求是通过HTTP流水线(pipelined)发送,pipe值为“p”,否则为“.”。- $
http_referer记录从哪个页面链接访问过来的- $
http_user_agent记录客户端浏览器相关信息- $
request_length请求的长度(包括请求行,请求头和请求正文)。- $
request_time请求处理时间,单位为秒,精度毫秒; 从读入客户端的第一个字节开始,直到把最后一个字符发送给客户端后进行日志写入为止。- $
time_iso8601ISO8601标准格式下的本地时间。- $
time_local通用日志格式下的本地时间。
如果未获取到,则日志输出为-
发送请求,导致Tomcat二号机内存溢出
浏览器上请求127.0.0.1/set。当返回为Two!Yes的时候,表示会造成内存溢出的线程已经开始运行。(如果返回的不是,则继续请求,直到返回Two!Yes)
此时继续请求127.0.0.1/set,你会发现最后请求都会返回One!Yes+时间,但你会发现有的请求发送之后要整整1分钟左右才响应One!Yes+时间。
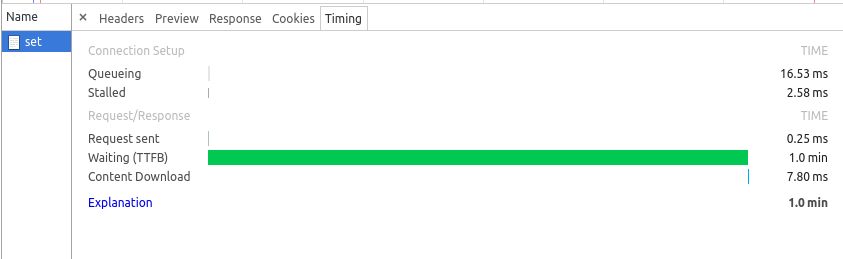
这个1分钟时间便是请求被nginx的负载均衡算法分配到此时内存溢出的二号机上,而该机无法处理,nginx等待了1分钟后便把请求转发给了其他机器
从Nginx的日志中也能看到这一点:
127.0.0.1 - - [08/Jul/2017:15:06:51 +0800] fwf[-] tip[-] 192.168.0.101:9090, 192.168.0.101:8080 60.003, 0.006 60.009 - 127.0.0.1 GET /set HTTP/1.1 "200" 67 "-" "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36"
查阅nginx负载均衡修相关的参数
在nginx中,upstream中的server语法如下:
server address [weight=number] [max_fails=number] [fail_timeout=time] [slow_start=time] [backup] [down];
其中max_fails和fail_timeout的默认值分别为1和10s,这两个参数配置起来使用.含义是:在fail_timeout的时间内,nignx与upstream中某个server的连接尝试失败了max_fails次,则nginx会认为该server已经失效。在接下来的 fail_timeout时间内,nginx不再将请求分发给失效的server。
因此在默认的情况下,nginx在前一次尝试连接9090端口失败后,在10秒之后才会再次去尝试。
其次在location中还有两个重要的参数,proxy_connect_timeout和proxy_read_timeout设置.这两个参数的含义如下:
proxy_connect_timeout
后端服务器连接的超时时间_发起握手等候响应超时时间(默认为60s)
proxy_read_timeout
连接成功后等候后端服务器响应时间其实已经进入后端的排队之中等候处理(也可以说是后端服务器处理请求的时间)(默认为60s)
而9090端口的tomcat在内存溢出的情况下,仍然能够与nginx完成握手,但是却不能处理结果,所以等待的一分钟时间是耗费在proxy_read_timeout了.如果能设置一个合适的值,就可以在可接受的时间范围内,完成集群的故障迁移。
修改proxy_read_timeout为10s
location / {proxy_pass http://webservers;proxy_read_timeout 10s;}
继续重复上述的测试过程,发现次数延迟只有10s
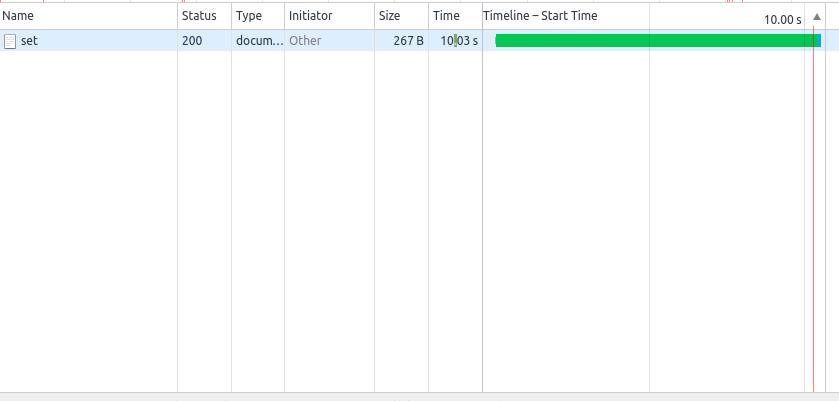





























(2)")




还没有评论,来说两句吧...