配置&使用Spark History Server
Spark history Server产生背景
以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息;但该WEBUI随着Application的完成(成功/失败)而关闭,也就是说,Spark Application运行完(成功/失败)后,将无法查看Application的历史记录;
Spark history Server就是为了应对这种情况而产生的,通过配置可以在Application执行的过程中记录下了日志事件信息,那么在Application执行结束后,WEBUI就能重新渲染生成UI界面展现出该Application在执行过程中的运行时信息;
Spark运行在yarn或者mesos之上,通过spark的history server仍然可以重构出一个已经完成的Application的运行时参数信息(假如Application运行的事件日志信息已经记录下来);
配置&使用Spark History Server
1、修改spark home下面的conf中的spark-defaults.conf
[hadoop@master conf]$ cp spark-defaults.conf.template spark-defaults.conf
[hadoop@master conf]$ vim spark-defaults.conf
内容如下
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/user/hadoop/spark/sparklogs #目录需要手动建好
spark.yarn.historyServer.address master:18080
2、其他两台slave同样配置
3、启动history server
[hadoop@master spark-1.2.1-bin-hadoop2.4]$ ./sbin/start-history-server.sh hdfs://master:9000/user/hadoop/spark/sparklogs
4、运行应用程序如
./spark-submit —master spark://192.168.189.136:7077 —class main.scala.com.spark.firstapp.WordCount —executor-memory 1g /opt/testspark/FirstSparkApp2.jar hdfs://master:9000/user/hadoop/input/README.txt hdfs://master:9000/user/hadoop/output
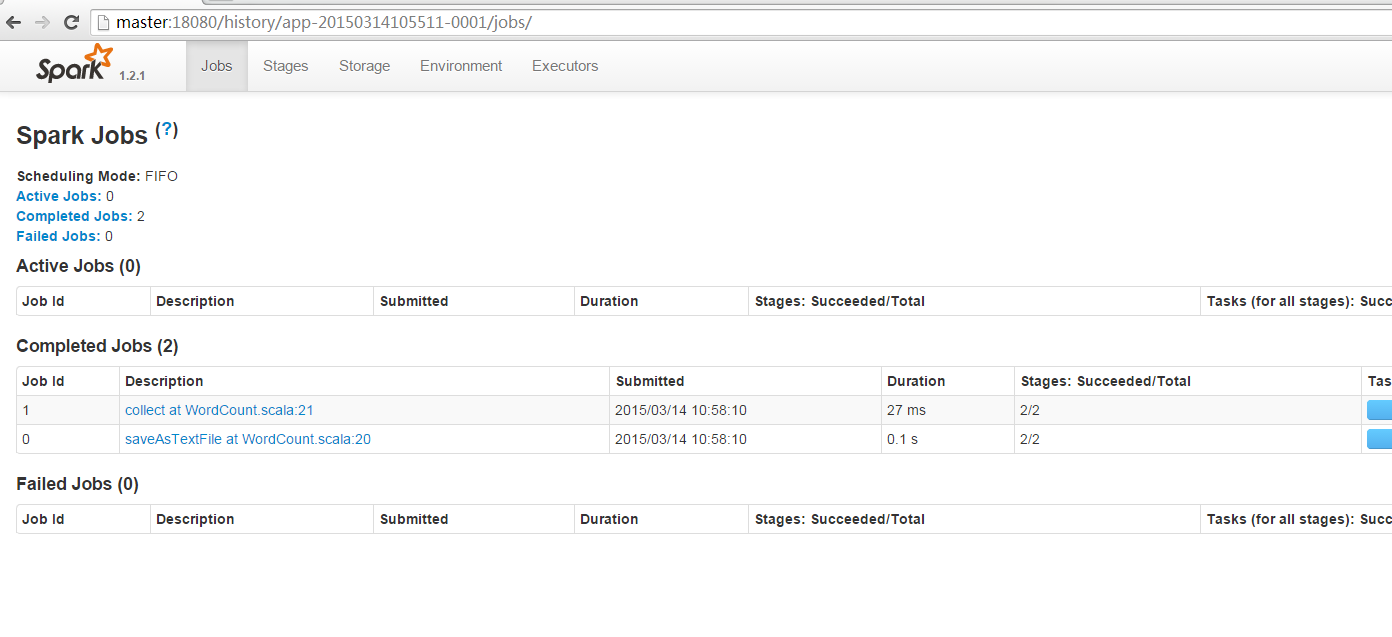
5、查看状态
http://master:18080/

























")


还没有评论,来说两句吧...