海量数据挖掘MMDS week5: 聚类clustering
http://[blog.csdn.net/pipisorry/article/details/49427989][blog.csdn.net_pipisorry_article_details_49427989]
海量数据挖掘Mining Massive Datasets(MMDs) -Jure Leskovec courses学习笔记 推荐系统Recommendation System之隐语义模型latent semantic analysis
{博客内容:Clustering. The problem is to take large numbers of points and group them into a small number of groups so that points are much closer to other points in their group than to points in other groups. This subject, although it has a long history, is sometimes referred to by the retronym “unsupervised learning,” because you “learn” something about the data without needed a training set.}
聚类综述Overview
问题形式化描述

聚类难点

聚类实例



距离度量方法的选择

聚类方法

Note: A topic is just a set of words that appear together frequently.
皮皮blog
层次聚类Hierarchical Clustering
这里只讲凝聚即自底向上的层次聚类方法。
主要思想及问题

欧式空间Euclidean的点和距离表示

层次聚类示例1
合并距离最近的两点
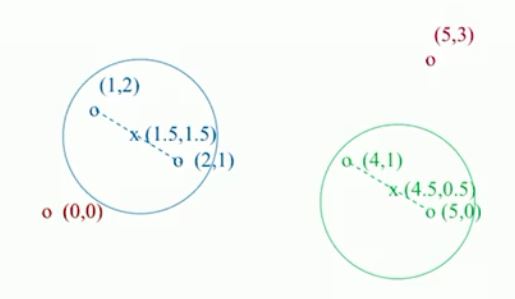
合并距离最近的新点
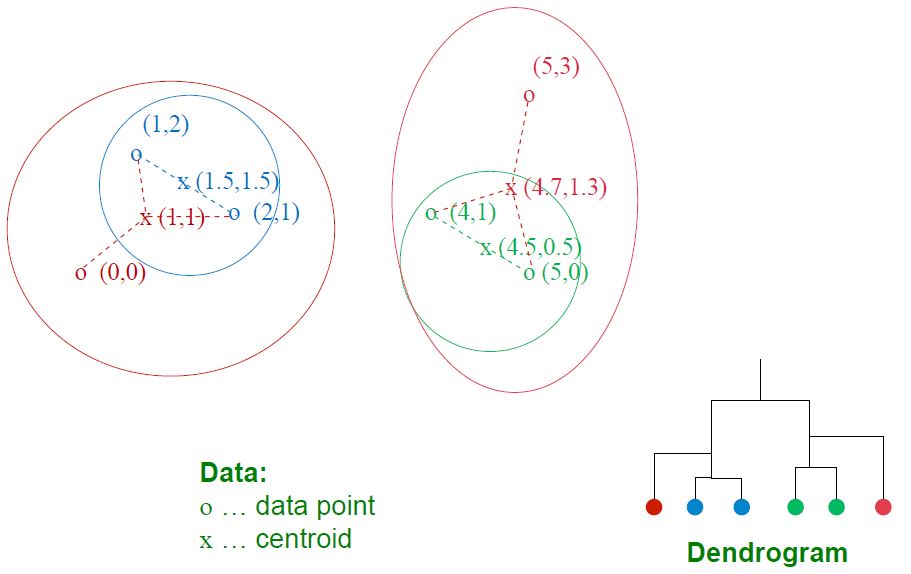
非欧式空间Non-Euclidean的点和距离表示
皮皮blog
from //blog.csdn.net/pipisorry/article/details/49427989
//blog.csdn.net/pipisorry/article/details/49427989
ref: [聚类算法]

























 ---- PyTorch目标检测")


还没有评论,来说两句吧...