【四】多线程 —— 内存模型
一、Java内存模型
JMM即Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、CPU 指令优化等。
JMM 体现在以下几个方面(也叫并发编程的三要素)
- 原子性 - 保证指令不会受
线程上下文切换的影响 - 可见性 - 保证指令不会受
cpu 缓存的影响 - 有序性 - 保证指令不会受
cpu 指令并行优化的影响
主要是从Java的层面进行了抽象和封装,使得开发人员不用直接面对底层操作。
1.1 可见性
保证指令不会受cpu 缓存的影响。
【退不出的循环】
先来看一个现象,main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
public class NoStop {static boolean run = true;public static void main(String[] args) throws InterruptedException {Thread t = new Thread(()->{while(run){ConsoleUtil.print("6666666");}});t.start();TimeUnit.SECONDS.sleep(1);run = false; // 线程t不会如预想的停下来}}
为什么呢?分析一下:
(1)初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存
(2)因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率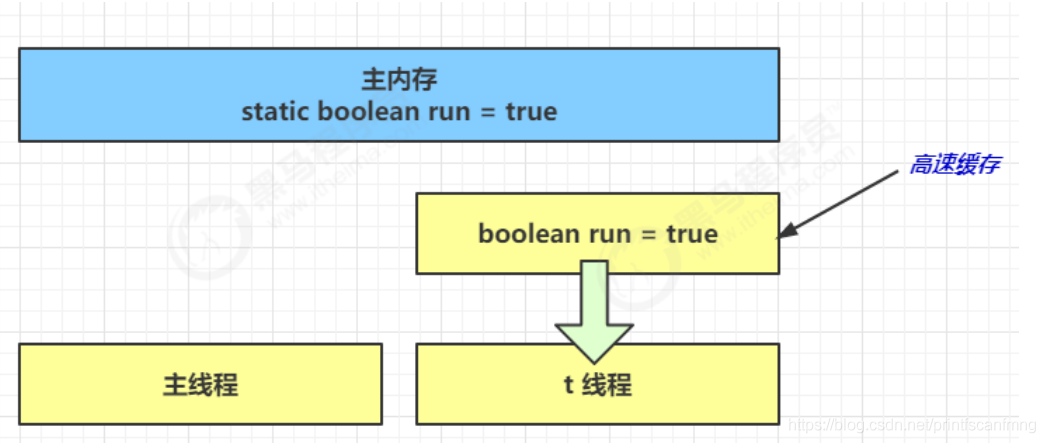
(3)1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值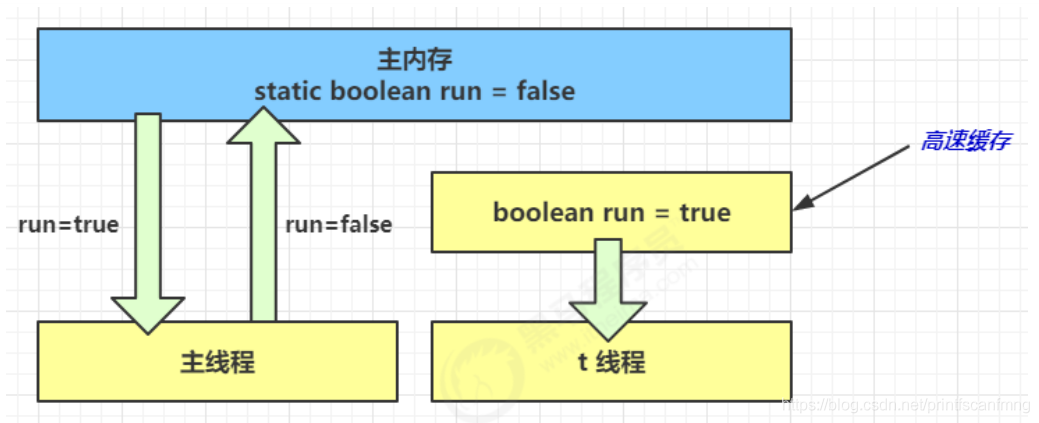
解决方法:
(1)volatile
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作volatile 变量都是直接操作主存。
(2)synchronized
加了synchronized也可以保证变量的可见性,但是synchronized需要关联Monitor对象,是重量级的,不仅保证可见性还保证原子性;volatile更轻量级,只保证可见性,不保证原子性 ,只能用在一个线程写,多个线程读的情况。
1.2 可见性 vs 原子性
在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可见, 不能保证原子性,仅用在一个写线程,多个读线程的情况。
1.3 有序性
保证指令不会受cpu 指令并行优化的影响。
JVM 会在不影响正确性的前提下,可以调整语句的执行顺序,思考下面一段代码:
static int i;static int j;// 在某个线程内执行如下赋值操作i = ...;j = ...;
可以看到,至于是先执行 i 还是 先执行 j ,对最终的结果不会产生影响。所以,上面代码真正执行时,既可以是:
i = ...;j = ...;
也可以是:
j = ...;i = ...;
这种特性称之为『指令重排』,多线程下『指令重排』会影响正确性。
为什么要有重排指令这项优化呢?从 CPU执行指令的原理来理解一下吧。
指令重排序优化 与 指令级并行原理
事实上,现代处理器会设计为一个时钟周期完成一条执行时间最长的 CPU 指令。为什么这么做呢?可以想到指令还可以再划分成一个个更小的阶段,例如,每条指令都可以分为: 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 这 5 个阶段。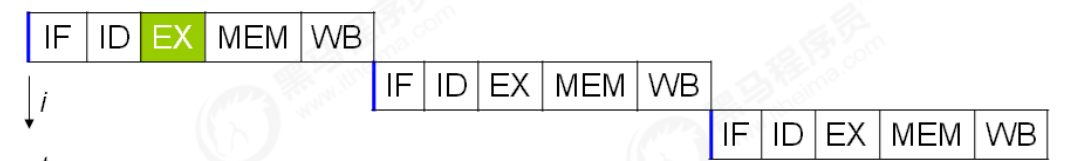
在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行。
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 的处理器,就可以称之为五级指令流水线。
这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一条执行时间最长的复杂指令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了指令地吞吐率。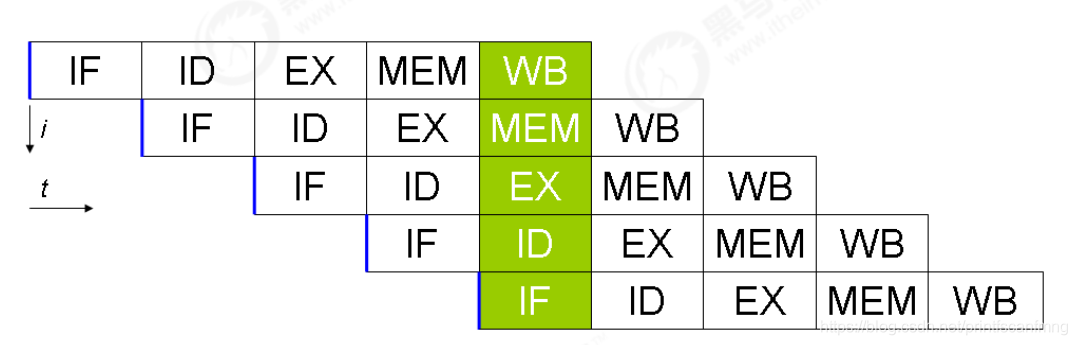
禁用指令重排序直接加volatile修饰就可。
指令进重排序不能随意重排序,需要满足以下两个条件:
①在单线程环境下不能改变程序运行的结果;
②存在数据依赖关系的不允许重排序
需要注意的是:重排序不会影响单线程环境的执行结果,但是会破坏多线程的执
行语义。
1.4 volatile原理
上面说了volatile可以保证可见性,又可以防止指令重排。底层原理是啥?
1.4.1 如何保证可见性
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
- 对
volatile变量的写指令后会加入写屏障 - 对
volatile变量的读指令前会加入读屏障
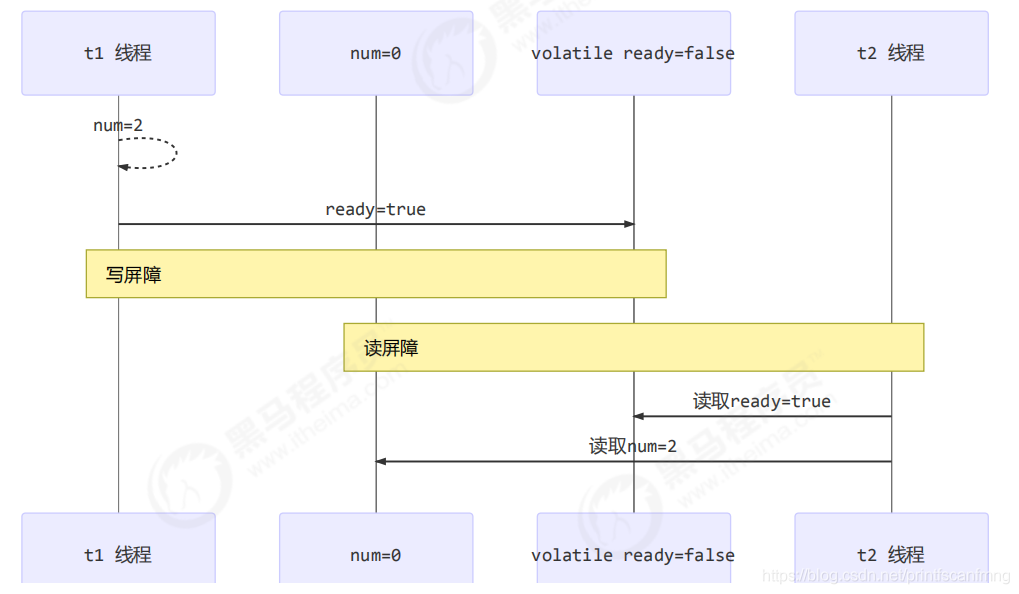
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中。
public void actor2(I_Result r) {num = 2;ready = true; // ready 是 volatile 赋值带写屏障// 写屏障}
读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
public void actor1(I_Result r) {// 读屏障// ready 是 volatile 读取值带读屏障if(ready) {r.r1 = num + num;} else {r.r1 = 1;}}
以双检锁实现的单例模式为例:
public class Singleton4 {// 自己持有自己并直接创建对象(使用volatile关键字防止重排序,new Instance()是一个非原子操作,可能创建一个不完整的实例)private static volatile Singleton4 instance;// 构造器私有化,不让外部通过构造器产生对象,从而保证对象全局唯一private Singleton4() { }// 对外提供获取唯一实例的静态方法public static Singleton4 getInstance() {// 判断是否存在单例if(instance == null){// 加锁,保持只有一个线程执行(只需在第一次创建实例时才同步)synchronized (Singleton4.class){// 再次判断单例是否被创建(防止其他线程已经创建而导致再次创建)if (instance == null){instance = new Singleton4();}}}return instance;}}
这里的关键就是:有了写屏障就保障构造方法一定是在引用赋值前已完全结束,防止指令重排。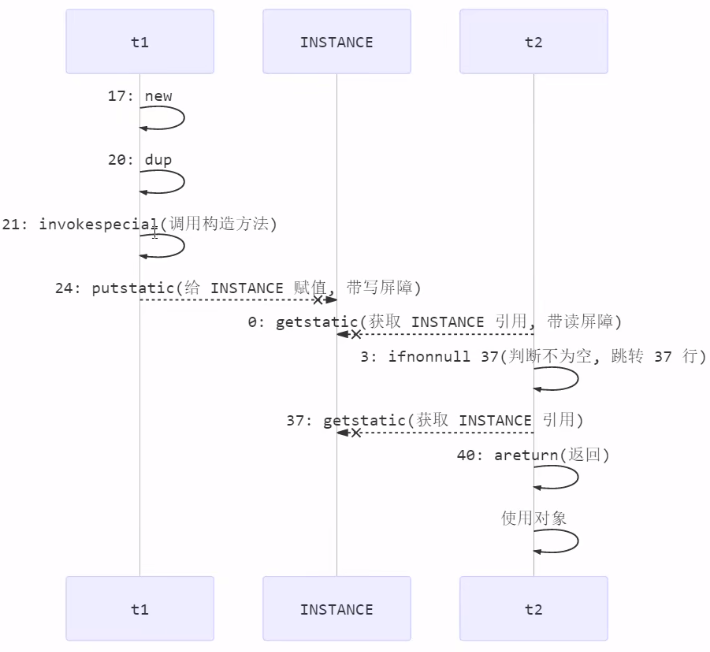
1.4.2 如何保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后。
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前。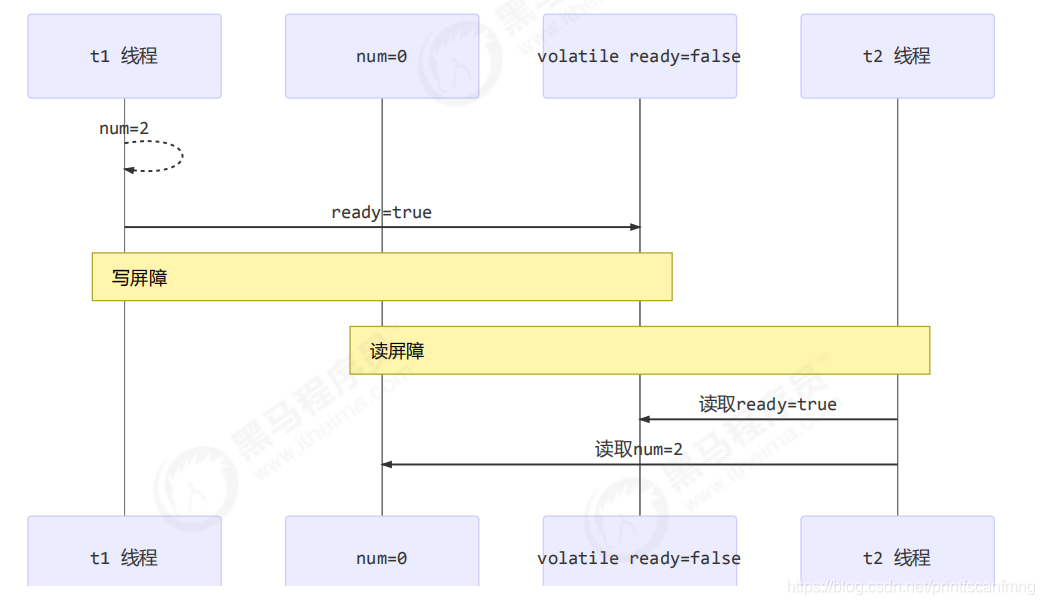
volatile的实现原理:
通过对OpenJDK中的unsafe.cpp源码的分析,会发现被volatile关键字修饰的变量会存在一个“lock:”的前缀。
Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。类似于Lock指令。
在具体的执行上,它先对总线和缓存加锁,然后执行后面的指令,在Lock锁住总线的时候,其他CPU的读写请求都会被阻塞,直到锁释放。最后释放锁后会把高速缓存中的脏数据全部刷新回主内存,且这个写回内存的操作会使在其他CPU里缓存了该地址的数据无效。
所以,Lock不是内存屏障却能完成类似内存屏障的功能,阻止了屏障两边的指令重排序。
1.4.3 不能保证原子性
volatile不能保证线程间的指令交错,每个线程是由cpu进行调度的,指令执行先后会有交错,即原子性不能保证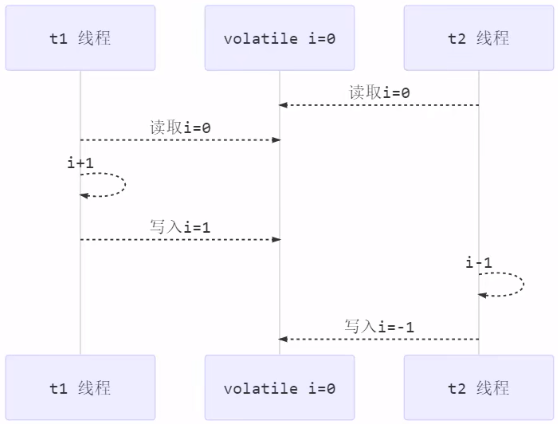
二、happens-before
happens-before规定了对共享变量的写操作对其它线程的读操作可见,是可见性与有序性的一套规则总结。
happens-before定义了八条规则,这八条规则都是用来保证如果A happens-before B,那么A的执行结果对B可见且A的执行顺序排在B之前。
- 1.程序次序规则:在一个单独的线程中,按照程序代码的执行流顺序,(时间上)先执行的操作happen—before(时间上)后执行的操作。
- 2.管理锁定规则:一个unlock操作happen—before后面(时间上的先后顺序,下同)对同一个锁的lock操作。
- 3.volatile变量规则:对一个volatile变量的写操作happen—before后面对该变量的读操作。
- 4.线程启动规则:Thread对象的start()方法happen—before此线程的每一个动作。
- 5.线程终止规则:线程的所有操作都happen—before对此线程的终止检测,可以通过Thread.join()方法结束、Thread.isAlive()的返回值等手段检测到线程已经终止执行。
- 6.线程中断规则:对线程interrupt()方法的调用happen—before发生于被中断线程的代码检测到中断时事件的发生。
- 7.对象终结规则:一个对象的初始化完成(构造函数执行结束)happen—before它的finalize()方法的开始。
- 8.传递性:如果操作A happen—before操作B,操作B happen—before操作C,那么可以得出A happen—before操作C。
happens-before定义了这么多规则,其实总结起来可以归纳为一句话:happens-before规则保证了单线程和正确同步的多线程的执行结果不会被改变。
那为什么有程序次序规则的保证,上面多线程执行过程中还是出现了重排序呢?这是因为happens-before规则仅仅是java内存模型向程序员做出的保证。在单线程下,他并不关心程序的执行顺序,只保证单线程下程序的执行结果一定是正确的,java内存模型允许编译器和处理器在happens-before规则下对程序的执行做重排序。
===============================================================================
线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见
static int x;
static Object m = new Object();new Thread(()->{
synchronized(m) {x = 10;}
},”t1”).start();
new Thread(()->{
synchronized(m) {System.out.println(x);}
},”t2”).start();
线程对 volatile 变量的写,对接下来其它线程对该变量的读可见
volatile static int x;
new Thread(()->{
x = 10;
},”t1”).start();
new Thread(()->{
System.out.println(x);
},”t2”).start();
线程 start 前对变量的写,对线程开始后对该变量的读可见
static int x;
x = 10;new Thread(()->{
System.out.println(x);
},”t2”).start();
线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive()或 t1.join()等待它结束)
static int x;
Thread t1 = new Thread(()->{
x = 10;
},”t1”);
t1.start();
t1.join();
System.out.println(x);线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过t2.interrupted 或 t2.isInterrupted)
static int x;
public static void main(String[] args) {Thread t2 = new Thread(()->{while(true) {if(Thread.currentThread().isInterrupted()) {System.out.println(x);break;}}},"t2");t2.start();new Thread(()->{sleep(1);x = 10;t2.interrupt();},"t1").start();while(!t2.isInterrupted()) {Thread.yield();}System.out.println(x);
}
对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
具有传递性,如果 x hb-> y 并且 y hb-> z 那么有 x hb-> z ,配合 volatile 的防指令重排,有下面的例子
volatile static int x;
static int y;new Thread(()->{
y = 10;x = 20; // 这里是写屏障
},”t1”).start();
new Thread(()->{
// x=20 对 t2 可见, 同时 y=10 也对 t2 可见System.out.println(x);
},”t2”).start();
y=10也可见是因为在写屏障之前的变量写操作都同步到主内存,即使不是volatile修饰的变量。


































还没有评论,来说两句吧...