论文阅读|DeepWalk: Online Learning of Social Representations
论文阅读|DeepWalk: Online Learning of Social Representations
文章目录
- 论文阅读|DeepWalk: Online Learning of Social Representations
- Abstract
- Introduction
- Problem Definition
- Learning Social Representations
- Method
- 实验设置
- Related Work
- 我的看法
- 参考资料
Abstract
DeepWalk概括了语言模型和无监督特征学习(或深度学习)从单词序列到图形的最新进展。 DeepWalk 使用从截断的随机游走中获得的局部信息,通过将游走视为句子的等价物来学习潜在表示。
Introduction
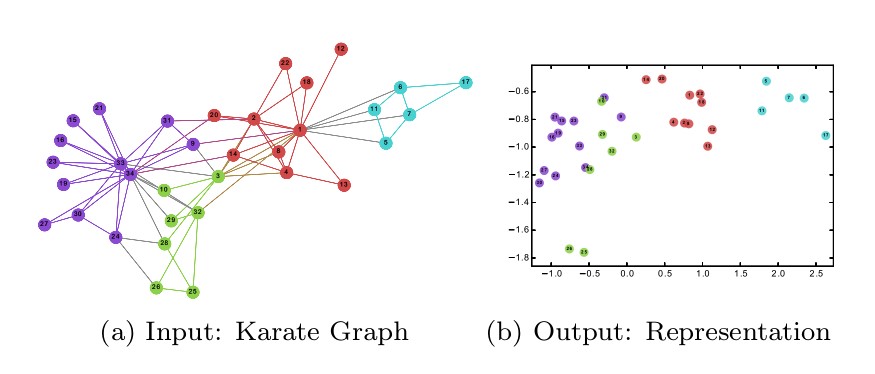
上图是将karate_klub社交网络编码嵌入后社区结构之间的对应关系。
论文贡献如下:
- 引入深度学习作为分析图的工具,以构建适用于统计建模的稳健表示。deepwalk使用很短的随机游走来学习图的结构规律。
- 在标签稀疏性的网络上,显著提高了分类性能,Micro-F1指数提高了5%-10%。某些情况下,减少60%训练数据也有很好的表现。
- 并实现行构建网络表示证明算法的可扩展性。
Problem Definition
- 图 G = ( V , E ) G = (V,E) G=(V,E)
- G L = ( V , E , X , Y ) G_L=(V,E,X,Y) GL=(V,E,X,Y)是部分标记的社交网络, X ∈ R ∣ V ∣ × S X∈R^{|V|×S} X∈R∣V∣×S,S是每个属性向量的特征空间的大小, Y ∈ R ∣ V ∣ × ∣ y ∣ Y∈R^{|V|×|y|} Y∈R∣V∣×∣y∣,y是标签集
论文中提出了一种不同的方法来捕获网络拓扑信息。 它没有将标签空间混合作为特征空间的一部分,而是提出了一种无监督的方法,该方法学习捕获独立于标签分布的图结构的特征。
结构表示和标记任务之间的分离避免了在迭代方法中可能发生的级联错误。
- 目标是学习 X E ∈ R ∣ V ∣ × d X_E∈R^{|V|×d} XE∈R∣V∣×d,其中d是少量的潜在维度
Learning Social Representations
从以下几个方面来考虑社区学习:
- 适应性:社会关系不因网络的发展而变化
- 社区意识:一定的维度距离下网络中成员之间的社会相似性
- 低维:当数据标记稀缺时,低维模型可以更好地泛化,并加速收敛和推理
- 连续:潜在表征模拟连续空间中的部分社区成员
随机游走(Random Walks):以节点 v i v_i vi为根的随机游走表示为 W v i ⋅ W_{vi·} Wvi⋅
幂率(Power laws):单词出现的频率遵循幂率,若图中节点遵循幂率,则随机游走时邻居节点的出现也遵循幂率
语言模型(Language Modeling):语言建模的目标是估计特定单词序列在语料库中出现的可能性。准确说就是给定一个单词序列 W 1 n = ( w 0 , w 1 , ⋅ ⋅ ⋅ , w n ) W_1^n=(w_0,w_1,···,w_n) W1n=(w0,w1,⋅⋅⋅,wn),其中 w i ∈ V , V w_i∈V,V wi∈V,V是词汇表,我们希望最大化 P r ( w n ∣ w 0 , w 1 , ⋅ ⋅ ⋅ , w n − 1 ) Pr(w_n|w_0,w_1,···,w_{n-1}) Pr(wn∣w0,w1,⋅⋅⋅,wn−1)。
将此模型应用到网络中(节点即为单词),显然有
P r ( v i ∣ ( v 1 , v 2 , ⋅ ⋅ ⋅ , v i − 1 ) ) Pr(v_i|(v_1,v_2,···,v_{i-1})) Pr(vi∣(v1,v2,⋅⋅⋅,vi−1))
我们的目标是学习潜在表示,而不仅仅是节点共现的概率分布,因此引入了映射函数 Φ : v ∈ V → R ∣ V ∣ × d \Phi:v∈V→R^{|V|×d} Φ:v∈V→R∣V∣×d。其中$\Phi $表示与图中每个顶点v相关联的潜在社会表示。此时,问题变成了概率
P r ( v i ∣ ( Φ ( v 1 ) , Φ ( v 2 ) , ⋅ ⋅ ⋅ , Φ ( v i − 1 ) ) ) Pr(v_i|(\Phi (v_1), \Phi(v_2),···,\Phi(v_{i-1}))) Pr(vi∣(Φ(v1),Φ(v2),⋅⋅⋅,Φ(vi−1)))
使用单词来预测内容的语言模型,在建模上产生了优化问题,即最小化
m i n i m i z e − l o g P r ( ( v i − w , ⋅ ⋅ ⋅ , v i + w ) v i ∣ Φ ( v i ) ) minimize \quad -logPr( ({ v_{i-w},···,v_ {i+w}}) \ v_i|Φ(v_i)) minimize−logPr((vi−w,⋅⋅⋅,vi+w)vi∣Φ(vi))
Method
DeepWalk

其中
- γ \gamma γ表示每个节点的随机游走次数
- O = s h u f f l e ( V ) : O=shuffle(V): O=shuffle(V):每次打乱节点的目的是:加快随机梯度下降的收敛速度
SkipGram

- skipgram语言模型,可最大化窗口内单词的共现频率
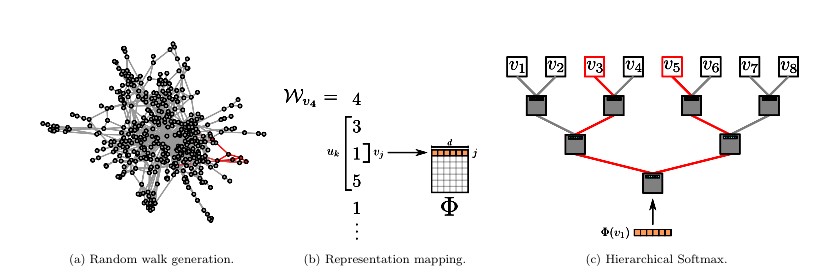
- 使用分层softmax来近似概率分布,如下图中
c所示。
代码第三行计算成本很高,所以使用Hierarchical softmax。顶点分配给二叉树的叶子,将预测问题转化为最大化层次结构中特定路径的概率。如果到顶点 u k u_k uk的路径由一系列树节点 b 0 , b 1 , ⋅ ⋅ ⋅ , b ∣ l o g ∣ V ∣ ∣ , ( b 0 = r o o t , b ∣ l o g ∣ V ∣ ∣ = u k ) b_0,b_1,···,b|log|V||,(b_0=root,b|log|V||=u_k) b0,b1,⋅⋅⋅,b∣log∣V∣∣,(b0=root,b∣log∣V∣∣=uk),则
P r ( u k ∣ Φ ( v j ) ) = ∏ l = 1 l o g ∣ V ∣ P r ( b l ∣ Φ ( v j ) ) Pr(u_k|\Phi (v_j))=\prod_{l=1}^{log|V|}Pr(b_l|\Phi (v_j)) Pr(uk∣Φ(vj))=l=1∏log∣V∣Pr(bl∣Φ(vj))
此时, P r ( b l ∣ Φ ( v j ) ) Pr(b_l|\Phi(v_j)) Pr(bl∣Φ(vj))可以通过分配给节点 b l b_l bl的父节点的二分类器建模,
P r ( b l ∣ Φ ( v j ) ) = 1 / ( 1 + e − Φ ( v j ) ⋅ Ψ ( b l ) ) Pr(b_l|\Phi(v_j))=1/(1+e^{-\Phi(v_j)·\Psi(b_l)}) Pr(bl∣Φ(vj))=1/(1+e−Φ(vj)⋅Ψ(bl))
其中 Ψ ( b l ) ∈ R d 是 分 配 给 \Psi(b_l)∈R^d是分配给 Ψ(bl)∈Rd是分配给 b l b_l bl的父节点的表示。
- 使用霍夫曼编码减少树中频繁元素的访问时间
实验设置
数据集:BlogCatalog,Flickr,YouTube。
评价指标:Micro-F1
Related Work
提出的方法意义:
- 学习潜在社区表示
- 不尝试扩展分类程序本身
- 提出了一种仅使用本地信息的可扩展在线方法
- 将无监督表示学习应用于图
我的看法
优点:
- 将词嵌入与图结合,提供了一种思路
缺点:
- 算法仅考虑到了节点与节点的连接关系,不适用于复杂网络,如有权重和属性的边。
- 准确率较低
参考资料
论文:DeepWalk: Online Learning of Social Representations
图的幂律度分布 power-law degree distributios
分层softmax
#机器学习 Micro-F1和Macro-F1详解





























二叉树的遍历及其七种实现方式")




还没有评论,来说两句吧...