[K8S] Pod调度
- pod创建的过程
- 资源限制(cpu,memory)
- nodeSelector
- nodeAffinity
- 污点和污点容忍
- 指定调度节点
@pod创建的过程
1、kubectl run(创建一个pod,请求发送给)-> apiserver(将数据存储到) -> etcd
2、scheduler(将创建的pod根据调度算法选择一个合适的节点并标记,返回给) -> apiserver -> etcd
3、kubelet(发现有新的pod分配,调用docker api创建容器,将容器状态返回给) -> apiserver -> etcd
Kubernetes基于list-watch机制的控制器架构
其它组件监控自己负责的资源,当这些资源发生变化时,kube apiserver会通知这些组件
Etcd存储集群的数据信息,apiserver作为统一入口,任何对数据的操作都必须经过apiserver。
客户端(kubelet/scheduler/controller-manager)通过list-watch监听apiserver中资源(pod/rs/rc等等)的create,update和delete事件,并针对事件类型调用相应的事件处理函数。
list-watch传送门 -> 理解 K8S 的设计精髓之 List-Watch机制和Informer模块 https://zhuanlan.zhihu.com/p/59660536
@资源限制(cpu,memory)
limitpod.yaml内容如下,
apiVersion: v1kind: Podmetadata:name: testpodspec:containers:- image: nginxname: testpodresources:requests:memory: 100Micpu: 400mlimits:memory: 128Micpu: 500m
说明:
containers.resources.limits 容器使用的最大资源上限
containers.resources.requests 容器资源预留值、不是实际占用 -> 用于资源分配参考、判断节点可否容纳
当请求的值没有节点能够满足时,pod处于pendding
cpu的1核=1000m
kubectl describe pod
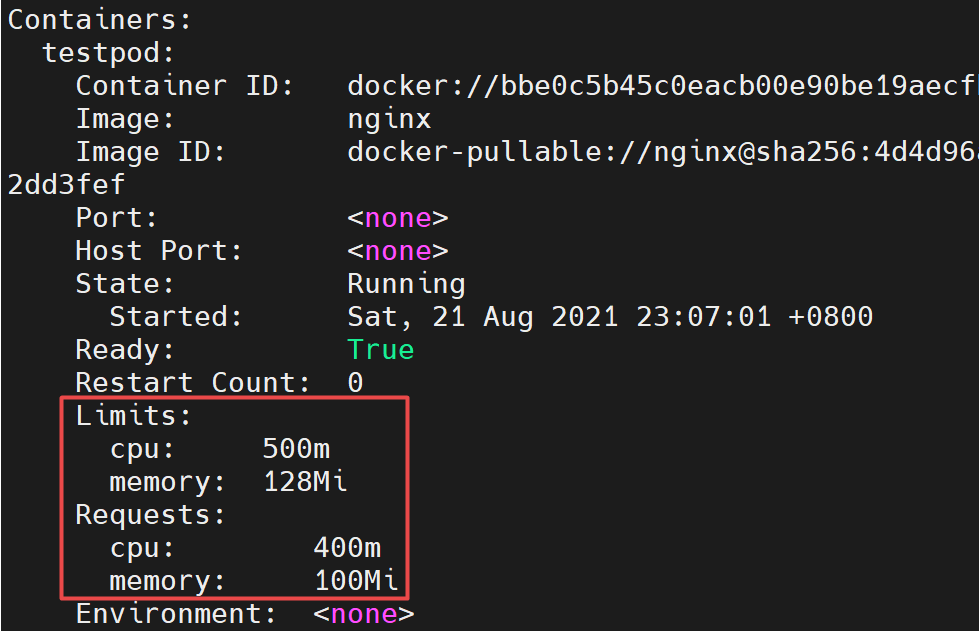
看看pod在哪个节点,当前pod在k8s-node1
[root@k8s-master ~]# kubectl get pod testpod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATEStestpod 1/1 Running 0 19m 10.244.36.66 k8s-node1 <none> <none>[root@k8s-master ~]#
然后用kubectl describe node

多创建几个pod,占满节点资源,当resources.requests值没有节点能够满足时,pod处于Pending

kubectl describe pod 查看原因是资源不足 
@nodeSelector
nodeSelector:用于将Pod调度到匹配标签的节点上,如果没有匹配的标签会调度失败。
应用场景举例,
专用节点:根据业务线将节点分组管理
配备特殊硬件:部分节点配有固态硬盘(比机械硬盘读写性能好)
节点添加、查看、删除标签命令,
给节点添加标签 kubectl label node
查看节点标签 kubectl get node —show-labels
去除节点标签 kubectl label node
节点上默认会打一些标签
[root@k8s-master ~]# kubectl get nodes --show-labelsNAME STATUS ROLES AGE VERSION LABELSk8s-master Ready control-plane,master 23d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=k8s-node1 Ready <none> 23d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linuxk8s-node2 Ready <none> 23d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node2,kubernetes.io/os=linux[root@k8s-master ~]#
为k8s-node1添加一个标签ssd
[root@k8s-master ~]# kubectl label node k8s-node1 disktype=ssdnode/k8s-node1 labeled[root@k8s-master ~]#[root@k8s-master ~]# kubectl get nodes --show-labelsNAME STATUS ROLES AGE VERSION LABELSk8s-master Ready control-plane,master 23d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=k8s-node1 Ready <none> 23d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linuxk8s-node2 Ready <none> 23d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node2,kubernetes.io/os=linux[root@k8s-master ~]#
生成一个pod的yaml文件,kubectl run testpod —image=nginx —dry-run=client -o yaml > testpod.yaml,编辑testpod.yaml的内容如下
apiVersion: v1kind: Podmetadata:name: testpodspec:nodeSelector:disktype: ssdcontainers:- image: nginxname: testpod
创建deployment,kubectl apply -f testpod.yaml,查看pod所在位置有无匹配到有ssd的k8s-node1
[root@k8s-master ~]# kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATEStestpod 1/1 Running 0 24s 10.244.36.112 k8s-node1 <none> <none>[root@k8s-master ~]#
去除标签 kubectl label node k8s-node1 disktype-
[root@k8s-master ~]# kubectl get node --show-labels | grep ssdk8s-node1 Ready <none> 23d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux[root@k8s-master ~]#[root@k8s-master ~]# kubectl label node k8s-node1 disktype-node/k8s-node1 labeled[root@k8s-master ~]# kubectl get node --show-labels | grep ssd[root@k8s-master ~]#
@nodeAffinity
节点亲和(nodeAffinity) 可以根据节点上的标签来约束Pod可以调度到哪些节点
相比nodeSelector,
1) 支持的操作符有:In,NotIn,Exists,DoesNotExist,Gt,Lt
可以使用 NotIn 和 DoesNotExist 来实现节点反亲和性行为,或者使用节点污点将 Pod 从特定节点中驱逐。
2) 调度分为软策略和硬策略,而不是硬性要求
- 硬策略(required)必须满足
- 软策略(preferred)尝试满足
【例】创建一个Pod,节点亲和性有一个硬策略和一个软策略
当前节点没有新加额外的标签,所以预期Pod创建不成功,node-affinity.yaml内容如下
apiVersion: v1kind: Podmetadata:name: node-affinityspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: projectoperator: Invalues:- makePeopleHappypreferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: groupoperator: Invalues:- test1containers:- name: webimage: nginx
说明:
硬策略 spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution
软策略 spec.affinity.nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution, weight 字段的取值范围是 1-100
注意:
- 同时指定nodeSelector和nodeAffinity,两者必须都满足,才能将Pod调度到候选节点上。
- 指定多个与 nodeAffinity 类型关联的 nodeSelectorTerms,其中一个nodeSelectorTerms满足,pod就可以调度到节点上。
- 指定多个与 nodeSelectorTerms 关联的 matchExpressions,当所有matchExpressions满足,pod才可以调度到节点上。
- 修改或删除 pod所调度到的节点的标签,pod不会被删除。即亲和性选择只在Pod调度期间有效。
硬策略说明:
创建Pod后一直处于Pending状态
[root@k8s-master ~]# kubectl apply -f node-affinity.yamlpod/node-affinity created[root@k8s-master ~]# kubectl get podNAME READY STATUS RESTARTS AGEnode-affinity 0/1 Pending 0 6s[root@k8s-master ~]#
使用 kubectl describe pod
[root@k8s-master ~]# kubectl describe pod node-affinity...Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling 80s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 node(s) didn't match Pod's node affinity.Warning FailedScheduling 80s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 node(s) didn't match Pod's node affinity.[root@k8s-master ~]#
现在给k8s-node2添加一个符合刚才创建Pod应策略的标签(预期预期Pod会被分配到k8s-node2)
然后看看刚才Pod的状态由Pending变为了ContainerCreating
[root@k8s-master ~]# kubectl label node k8s-node2 project=makePeopleHappynode/k8s-node2 labeled[root@k8s-master ~]# kubectl get podNAME READY STATUS RESTARTS AGEnode-affinity 0/1 ContainerCreating 0 5m3s[root@k8s-master ~]#[root@k8s-master ~]# kubectl get podNAME READY STATUS RESTARTS AGEnode-affinity 1/1 Running 0 6m[root@k8s-master ~]#
软策略的标签没有符合的节点,但不是必须满足的,而是尽量满足
软策略说明:
现在把刚才的pod删除,k8s-node1和k8s-node2都打上应策略匹配的标签,k8s-node1打上软策略需要的标签

然后创建pod(预期预期Pod会被分配到k8s-node1)
[root@k8s-master ~]# kubectl apply -f node-affinity.yamlpod/node-affinity created[root@k8s-master ~]# kubectl get pod node-affinity -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESnode-affinity 0/1 ContainerCreating 0 16s <none> k8s-node1 <none> <none>[root@k8s-master ~]#
去除标签恢复环境:
[root@k8s-master ~]# kubectl label node k8s-node1 project-node/k8s-node1 labeled[root@k8s-master ~]# kubectl label node k8s-node2 project-node/k8s-node2 labeled[root@k8s-master ~]# kubectl label node k8s-node1 group-node/k8s-node1 labeled[root@k8s-master ~]#[root@k8s-master ~]# kubectl get nodes --show-labels | egrep 'project|group'[root@k8s-master ~]#
@污点和污点容忍
污点 taints:避免Pod调度到特定Node上
污点容忍 tolerations:允许Pod调度到持有Taints的Node上
应用场景
- 专用节点
如果想将某些节点专门分配给特定的一组用户使用,可以给这些节点添加一个taint,然后给这组用户的Pod添加一个相对应的toleration
- 配备了特殊硬件的节点
在部分节点配备了特殊硬件(比如 GPU)的集群中,我们希望不需要这类硬件的Pod不要被分配到这些特殊节点,以便为后继需要这类硬件的Pod保留资源
- 基于污点的驱逐
这是在每个 Pod 中配置的在节点出现问题时的驱逐行为
1.污点
给节点添加污点 kubectl taint node
例如:kubectl taint node k8s-node1 gpu=yes:NoSchedule
查看节点的污点 kubectl describe node
effect取值,
NoSchedule :不会将 Pod 调度到该节点
PreferNoSchedule:尽量避免将Pod调度到该节点上,但不是强制的
NoExecute:不会调度,并且驱逐Node上已有的Pod
给节点去除污点 kubectl taint node
[root@k8s-master ~]# kubectl taint node k8s-node1 gpu=yes:NoSchedulenode/k8s-node1 tainted[root@k8s-master ~]# kubectl describe node k8s-node1 | grep TaintTaints: gpu=yes:NoSchedule[root@k8s-master ~]#
然后通过deployment创建pod试试, test-taint-deploy.yaml内容如下
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: webname: webnamespace: defaultspec:replicas: 4selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- image: nginxname: nginx
可以看到4个副本都避开了打了污点的k8s-node1
[root@k8s-master ~]# kubectl apply -f test-taint-deploy.yamldeployment.apps/web created[root@k8s-master ~]# kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESweb-96d5df5c8-gmspn 0/1 ContainerCreating 0 10s <none> k8s-node2 <none> <none>web-96d5df5c8-hh86q 0/1 ContainerCreating 0 10s <none> k8s-node2 <none> <none>web-96d5df5c8-n4587 0/1 ContainerCreating 0 10s <none> k8s-node2 <none> <none>web-96d5df5c8-wrmxv 0/1 ContainerCreating 0 10s <none> k8s-node2 <none> <none>[root@k8s-master ~]#
2.污点容忍
如果希望Pod可以被分配到带有污点的节点上,要在Pod配置中添加污点容忍(tolrations)字段
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且
如果 operator是 Exists, 此时容忍度不能指定 value
如果 operator是 Equal, 则它们的value应该相等
如果 key为空, 且operator为 Exists, 表示这个容忍度能容忍任意 taint
如果 effect为空,则可以与所有指定键名的效果相匹配
为test-taint-deploy.yaml添加tolerations,更新后内容如下,
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: webname: webnamespace: defaultspec:replicas: 4selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- image: nginxname: nginxtolerations:- key: gpuoperator: Equalvalue: "yes"effect: NoSchedule
说明: tolerations.value的值为yes,得加上引号,不然会报这么个错。之前的yaml没太注意,最好参考官方文档,该加引号的值都加上引号。

创建deployment, 这次不会避开打了污点的k8s-node1
[root@k8s-master ~]# kubectl delete -f test-taint-deploy.yamldeployment.apps "web" deleted[root@k8s-master ~]#[root@k8s-master ~]# kubectl apply -f test-taint-deploy.yamldeployment.apps/web created[root@k8s-master ~]# kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESweb-6854887cb-68sgr 1/1 Running 0 41s 10.244.36.74 k8s-node1 <none> <none>web-6854887cb-8627z 1/1 Running 0 41s 10.244.36.75 k8s-node1 <none> <none>web-6854887cb-c74f4 1/1 Running 0 41s 10.244.36.80 k8s-node1 <none> <none>web-6854887cb-hkbm2 1/1 Running 0 41s 10.244.169.145 k8s-node2 <none> <none>[root@k8s-master ~]#
@指定调度节点
不经过调度器,因此以上限制统统失效
test-fixednode-deploy.yaml内容如下, 指定调度到 nodeName: k8s-node1, 而k8s-node1有污点且该yaml文件没有污点容忍字段
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: webname: webnamespace: defaultspec:replicas: 4selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:nodeName: k8s-node1containers:- image: nginxname: nginx
可以看到所有pod副本都调度到了指定节点,即使该节点存在污点且pod未设置污点容忍
[root@k8s-master ~]# kubectl apply -f test-fixednode-deploy.yamldeployment.apps/web created[root@k8s-master ~]#[root@k8s-master ~]# kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESweb-57495dbb4b-fsn2j 1/1 Running 0 65s 10.244.36.86 k8s-node1 <none> <none>web-57495dbb4b-kjkx6 1/1 Running 0 65s 10.244.36.83 k8s-node1 <none> <none>web-57495dbb4b-lmntn 1/1 Running 0 65s 10.244.36.85 k8s-node1 <none> <none>web-57495dbb4b-tx96l 1/1 Running 0 65s 10.244.36.87 k8s-node1 <none> <none>[root@k8s-master ~]#
官方文档参考
将Pod分配给节点-> nodeSelector,pod亲和性 https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
污点和容忍度 https://kubernetes.io/zh/docs/concepts/scheduling-eviction/taint-and-toleration/


























完整思路,并用代码封装排序函数")



‘ 出错问题的解决方法")



还没有评论,来说两句吧...