The In’s and Out’s of Cryptographic Hash Functions
Hash functions are one of the foundational pillars of the blockchain technology. In fact, hashing singlehandedly imparts one of the most important properties to the blockchain: immutability.
The In’s and Out’s of Cryptographic Hash Functions
In this article, we will acquaint ourselves with some of the most commonly used cryptographic hash functions in cryptocurrencies. But before that, let’s understand what hashing means.

So what is hashing?
In simple terms hashing means taking an input string of any length and giving out an output of a fixed length. In the context of cryptocurrencies like bitcoin, the transactions are taken as an input and run through a hashing algorithm (bitcoin uses SHA-256) which gives an output of a fixed length.
Let’s see how the hashing process works. We are going to put in certain inputs. For this exercise, we are going to use the SHA-256 (Secure Hashing Algorithm 256).
As you can see, in the case of SHA-256, no matter how big or small your input is, the output will always have a fixed 256-bits length. This becomes critical when you are dealing with a huge amount of data and transactions. So basically, instead of remembering the input data which could be huge, you can just remember the hash and keep track. Before we go any further we need to first see the various properties of hashing functions and how they get implemented in the blockchain.
Cryptographic Hash Functions
A cryptographic hash function is a special class of hash functions which has various properties making it ideal for cryptography. There are certain properties that a cryptographic hash function needs to have in order to be considered secure. Let’s run through them one by one.
Property 1: Deterministic
This means that no matter how many times you parse a particular input through a hash function you will always get the same result. This is critical because if you get different hashes every single time it will be impossible to keep track of the input.
Property 2: Quick Computation
The hash function should be capable of returning the hash of an input quickly. If the process isn’t fast enough then the system simply won’t be efficient.
Property 3: Pre-Image Resistance
What pre-image resistance states is that given H(A) it is infeasible to determine A, where A is the input and H(A) is the output hash. Notice the use of the word “infeasible” instead of “impossible”. We already know that it is not impossible to determine the original input from its hash value. Let’s take an example.
Suppose you are rolling a dice and the output is the hash of the number that comes up from the dice. How will you be able to determine what the original number was? It’s simple all that you have to do is to find out the hashes of all numbers from 1-6 and compare. Since hash functions are deterministic, the hash of a particular input will always be the same, so you can simply compare the hashes and find out the original input.
But this only works when the given amount of data is very less. What happens when you have a huge amount of data? Suppose you are dealing with a 128-bit hash. The only method that you have to find the original input is by using the “brute-force method”. Brute-force method basically means that you have to pick up a random input, hash it and then compare the output with the target hash and repeat until you find a match.
So, what will happen if you use this method?
Best case scenario: You get your answer on the first try itself. You will seriously have to be the luckiest person in the world for this to happen. The odds of this happening are astronomical.
Worst case scenario: You get your answer after 2^128 – 1 times. Basically, it means that you will find your answer at the end of all the data.
Average scenario: You will find it somewhere in the middle so basically after 2^128/2 = 2^127 times. To put that into perspective, 2^127 = 1.7 X 10^38. In other words, it is a huge number.
So, while it is possible to break pre-image resistance via brute force method, it takes so long that it doesn’t matter.
Property 4: The Avalanche Effect.
Even if you make a small change in your input, the changes that will be reflected in the hash will be huge. Let’s test it out using SHA-256:
You see that? Even though you just changed the case of the first alphabet of the input, look at how much that has affected the output hash.
This property is also known as the avalanche effect.
Property 5: Collision Resistant
Given two different inputs A and B where H(A) and H(B) are their respective hashes, it is infeasible for H(A) to be equal to H(B). What that means is that for the most part, each input will have its own unique hash. Why did we say “for the most part”? In order to understand that, we need to know what “The Birthday Paradox” is.
What is the Birthday Paradox?
If you meet any random stranger out on the streets the chances are very low for both of you to have the same birthday. In fact, assuming that all days of the year have the same likelihood of having a birthday, the chances of another person sharing your birthday is 1/365 which is a 0.27%. In other words, it is really low.
However, having said that, if you gather up 20-30 people in one room, the odds of two people sharing the exact same birthday rises up astronomically. In fact, there is a 50-50 chance for 2 people of sharing the same birthday in this scenario!

Why does that happen? It is because of a simple rule in probability which goes as follows:
Suppose you have N different possibilities of an event happening, then you need square root of N random items for them to have a 50% chance of a collision.
So applying this theory for birthdays, you have 365 different possibilities of birthdays, so you just need Sqrt(365), which is ~23~, randomly chosen people for 50% chance of two people sharing birthdays.
What is the application of this in hashing?
Suppose you have a 128-bit hash which has 2^128 different possibilities. By using the birthday paradox, you have a 50% chance to break the collision resistance at the sqrt(2^128) = 2^64th instance.
As you can see, it is much easier to break collision resistance than it is to break pre-image resistance. No hash function is collision free, but it usually takes so long to find a collision. So, if you are using a function like SHA-256, it is safe to assume that if H(A) = H(B) then A = B.
So, how do you create a collision resistant hash function? For that we use a paradigm called the Merkle-Damgard paradigm.
What is the Merkle-Damgard Paradigm?
The paradigm is very simple and works on the following philosophy: Given a collision resistant hash function for short messages we can construct collision resistant hash function for long messages.
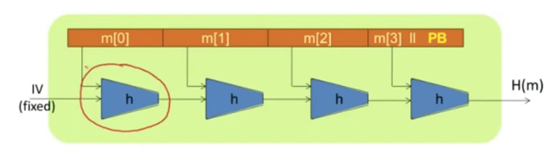
Image credit: Youtube
Keeping in mind the diagram above, take note of the following:
- A larger message M is broken down into smaller blocks of m[i].
- The hash function H consists of lots of smaller hash functions “h”.
- “h” is a smaller hash function, aka compression function, which takes in a small block of message and returns a hash.
- The first hash function “h” (which is circled in the diagram above) takes in the first block of message (m[0]) and adds to it a fixed value IV and returns the hash.
- The hash now gets added to the second block of message and goes through another hash
- function h and this goes on till the the last message block where a padding block PB is also added to the message.
- The output of each compression function h is called a chaining variable.
- The padding block is a series of a 1s and 0s. In the SHA-256 algo, the PB is 64 bits long.
- The output of the hash compression function h is the output of the large message M.
So, how does this follow collision resistance?
For this, we follow the simple theory: If “h” is collision resistant than “H” should be collision resistant as well.
In order to prove this theorem, we will go in the opposite direction. That is, if we can prove that collision exists on H then h should have a collision as well.
Suppose there are two messages M and M’ and we are getting collision on both their hashes meaning:
H(M) = H(M’)
Then we can use this information to deduce the collision in h. For now, let’s deduce the chaining variables for both H(M) and H(M’).
For H(M)IV= H(0), H(1), …., H(t), H(t+1) = H(M)For H(M’)IV= H’(0), H’(1), …., H’(r), H’(r+1) = H(M’)
Both the hash functions may not have the same number of chaining variables (t may not be equal to r). However, in both the scenarios:
H(t+1) = H(M).ANDH’(r+1) = H(M’)
And since we know that H(M) = H(M’) since collision exists so H’(r+1) = H(t+1).
Hmm… we are at an interesting conjecture here. Let’s refer back to our diagram above:
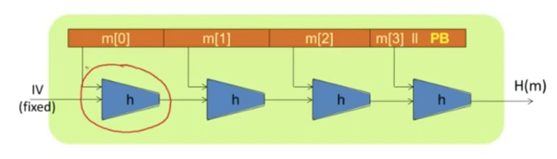
Now, if H(t+1) and H’(r+1) are the last hashes of their respective hash functions then what would be the message that would have gone into the last compression function of each function?
For H(t+1) that would be h(H(t), M(t)||PB)
Similarly, H’(r+1) = h(H’(r), M’(r)||PB’)
Now, if H(t+1) and H’(r+1) are the last hashes of their respective hash functions then what would be the message that would have gone into the last compression function of each function?
For H(t+1) that would be h(H(t), M(t)||PB)
Similarly, H’(r+1) = h(H’(r), M’(r)||PB’)
So, under what conditions should the compression function “h” be non collision resistant? IFF it gives the same output to inputs which are not similar meaning:
- H(t) != H’(r).
- M(t) != M’(r).
- PB != PB’.
However, if those outputs are similar then we have to go a little deeper. If PB = PB’ then we know that both have the same number of message blocks meaning t=r which would automatically mean that:
M(t) = M’(r)
AND H(t) = H’(r)
In this case we consider H(t) and H’(r) which we can rewrite as H’(t) since the value of t and r are the same.
So what would be the value of H(t) and H’(t)?
H(t) = h(H(t-1), M(t-1)) and H’(t) = h(H’(t-1), M’(t-1))
Since H(t) = H’(t) then h(H(t-1), M(t-1)) = h(H’(t-1), M’(t-1)).
For collision to hold through the following conditions must be observed:
H(t-1) != H’(t-1)
M(t-1) != M’(t-1),
If these conditions hold true then we know that we have found a collision on h and we can stop.
Now what happens if those conditions are true?
Meaning H(t-1) = H’(t-1) and since we already know that M(t) = M’(t) then M(t-1) = M’(t-1).
We can continue the above calculations for H(t-1) and H’(t-1) all the way till we reach the beginning of the message. In that case one of the two following conditions must hold:
- Find collision for h.
- All message blocks of M and M’ are the same.
Since we already know that the prime condition of a collision to occur is that the input message M and M’ can’t be the same, the only other condition where collision of H occurs is if compression function h also has a collision.
Hence we can see that for ever hash function H that has a collision we get a compression function h which also has collision and hence Merkle-Damgard holds true.
Property 6: Puzzle Friendly
Now, this is a very fascinating property, and the application and impact that this one property has had on cryptocurrency is huge. First let’s define the property, after that we will go over each term in detail.
For every output “Y”, if k is chosen from a distribution with high min-entropy it is infeasible to find an input x such that H(k|x) = Y.
That probably went all over your head! But it’s ok, let’s now understand what that definition means.
What is the meaning of “high min-entropy”?
It means that the distribution from which the value is chosen is hugely distributed so much so that us choosing a random value has negligible probability. Basically, if you were told to chose a number between 1 and 5, that’s a low min-entropy distribution. However, if you were to choose a number between 1 and a gazillion, that is a high min-entropy distribution.
What does “k|x” mean?
The “|” denotes concatenation. Concatenation means adding two strings together. Eg. If I were to concatenate “BLUE” and “SKY” together, then the result will be “BLUESKY”.
So now let’s revisit the definition:
Suppose you have an output value “Y”. If you choose a random value “k” from a wide distribution, it is infeasible to find a value X such that the hash of the concatenation of k and x will give the output Y.
Once again, notice the word “infeasible”, it is not impossible because people do this all the time. In fact, the whole process of mining works upon this (more on that later).
Examples of cryptographic hash functions
- MD 5: It produces a 128-bit hash. Collision resistance was broken after ~2^21 hashes.
- SHA 1: Produces a 160-bit hash. Collision resistance broke after ~2^61 hashes.
- SHA 256: Produces a 256-bit hash. This is currently being used by bitcoin.
- Keccak-256: Produces a 256-bit hash and is currently used by Ethereum.
- RIPEMD-160: Produces a 160-but output and is used by Bitcoin script (along with SHA-256).
- CryptoNight: The hash function used by Monero.
Now that we have gone through what hashing means and what the properties of cryptographic hash functions are, let’s acquaint ourselves with some of the most commonly used cryptographic hash functions in Cryptocurrency.
Secure Hashing Algorithms (SHA)
Secure Hash Algorithms, according to its Wikipedia page, are a family of cryptographic hash functions published by the National Institute of Standards and Technology (NIST) as a U.S. Federal Information Processing Standard (FIPS). The SHA consists of the following algorithms:
- SHA-0: Refers to the original 160-bit hash function published in 1993 under the name “SHA”. It was withdrawn shortly after publication due to an undisclosed “significant flaw” and replaced by the slightly revised version SHA-1.
- SHA-1: Was brought in when SHA-0 failed to deliver. This is a 160-bit hash function which resembles the earlier MD5 algorithm. This was designed by the National Security Agency (NSA) to be part of the Digital Signature Algorithm. However it was dumped shortly after people noticed crypto-graphical weaknesses.
- SHA-2: Ah now we come to one of the most popular categories of hash functions out there. It was designed by the NSA using the Merkle-Damgard paradigm. They are a family of two hash functions with different word sizes: SHA-256 and SHA-512. bitcoin uses SHA-256
- SHA-3: Formerly known as keccak, it was chosen in 2012 after a public competition among non-NSA designers. It supports the same hash lengths as SHA-2, and its internal structure differs significantly from the rest of the SHA family. Ethereum uses this hash function.
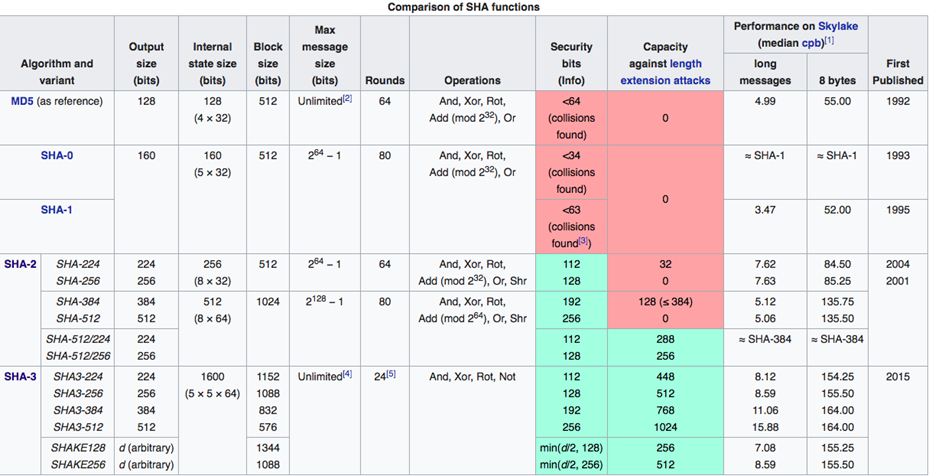
Image Credit: Wikipedia
Let’s take a closer look at SHA-256 and SHA-3.
SHA-256
SHA-256 is a SHA-2 function that uses 32-but words as opposed to SHA-512 which uses 64-bit words. bitcoin uses SHA-256 in 2 significant ways:
- Mining.
- Creation of addresses.
Mining:
Mining in bitcoin involves miners solve complex computational puzzles in order to find a block which then gets appended to the the Bitcoin blockchain. This is called proof-of-work and it involves the computation of a SHA-256 hash function.
Creation of addresses
The SHA-256 hash function is used to hash the bitcoin public key to generate the public address. Hashing the key adds an extra layer of protection to the person’s identity. Plus, a hashed address is simply shorter in length than a bitcoin public key which helps better in storage.
SHA-256 in action
Input: Hi
Output: 98EA6E4F216F2FB4B69FFF9B3A44842C38686CA685F3F55DC48C5D3FB1107BE4
SHA-3
As mentioned above, this was formerly known as keccak and is used by Ethereum. It was created after a public competition by non-NSA designers. The SHA-3 uses the sponge function.
What is the Sponge Function?
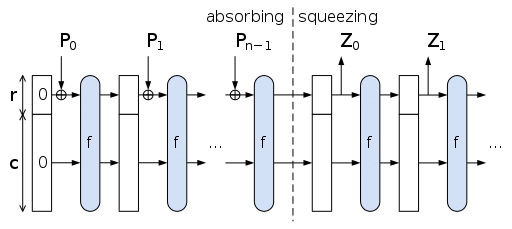
Image Credit: Wikipedia
A sponge function is a class of algorithms with finite internal state that takes an input bit stream of any length and produces an output bit stream of a predetermined length.
Before we continue, we need to define some terms:
We known that in a sponge function, data is “absorbed” into the sponge, then the result is “squeezed” out.
So there is an “Absorb” phase and a “Squeeze” phase.
Absorb Phase:
In this phase, the message is divided into blocks and XOR’d into a subset of the state, which is then transformed as a whole using a permutation function f.
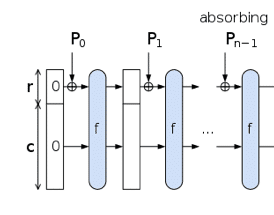
Squeeze Phase:
From Wikipedia. “Output blocks are read from the same subset of the state, alternated with the state transformation function f. The size of the part of the state that is written and read is called the “rate” (denoted r), and the size of the part that is untouched by input/output is called the “capacity” (denoted c). The capacity determines the security of the scheme. The maximum security level is half the capacity.”
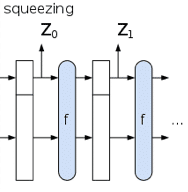
Now to see how it works, consider the following elements:
- An input string N.
- A padding function “pad”.
- A permutation functions “f” that operates of bit blocks of width b.
- A rate “r”.
- Output length = “d”.
- Capacity “c” = b-r.
- Sponge Construction: sponge[f,pad,r](N,d) which results in a bit string Z of the length d.
So, how will the process work now?
- Firstly, the input string is padded with “pad” which results in the padded bit string P with a length divisible by r.
- The padded string P is then broken down into n consecutive r-bit blocks from P[0] to P[n-1].
- Then we initialize the state S to a string of b 0 bits.
Now each block of padded string P starts getting absorbed using the following process:
a) Each block p[i] is padded using a string of c “0 bits” until it reaches length “b”.
b) The resulting string is XOR’d with “S”, i.e. the state coming from the previous block.
c) Finally the block permutation function f is applied to the result, yielding a new State S.NOTE: Each block results in a new state S. As we have seen in step 3, it is initialized value is “0”.
- The result Z is initialized to the empty string.
- IF the length of Z is less than d:
a) The first r bits of S are appended to Z.
b) If Z is still not of required length, the permutation function f is applied to S to create a new state and from there the bits are added to Z.- If Z is too long then it is truncated to d bits.
SHA-3 in action:
Input: Hi
Output:154013cb8140c753f0ac
358da6110fe237481b26c75c3ddc1b
59eaf9dd7b46a0a3aeb2cef164b3c82
d65b38a4e26ea9930b7b2cb3c01da
4ba331c95e62ccb9c3
RIPEMD-160 Hash Function
RIPEMD is a family of cryptographic hash functions developed in Leuven, Belgium, by Hans Dobbertin, Antoon Bosselaers and Bart Preneel at the COSIC research group at the Katholieke Universiteit Leuven, and first published in 1996.
While RIPEMD is based upon the design principles of MD4, its performance is a lot similar to SHA-1. RIPEMD-160 is the 160-bit version of this hash function and is commonly used in generating bitcoin addresses.
The bitcoin public key first runs though the SHA-256 hash function and then through RIPEMD-160. The reason why we do that is because the output of 160 bits is a lot smaller than 256 bits which helps in saving up space.
Along with that, RIPEMD-160 is the only hash function which produces the shortest hashes whose uniqueness is still sufficiently assured.
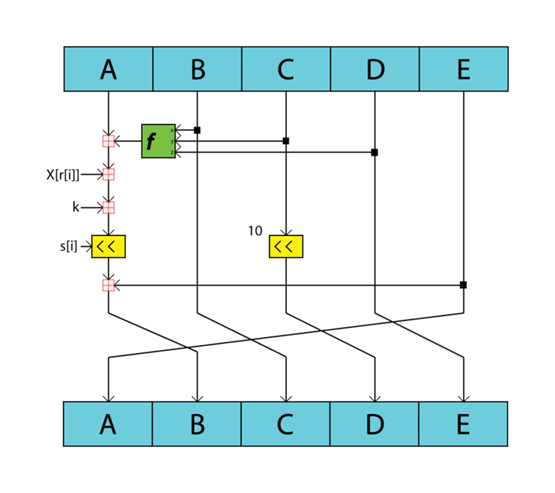
Image Credit: Wikipedia
The image above shows a snapshot of a sub-block from the compression function of the RIPEMD-160 hash algorithm.
RIPEMD-160 in action:
Input: Hi
Output: 242485ab6bfd3502bcb3442ea2e211687b8e4d89
CryptoNight Hash Function
Now we have the CryptoNight hash function which is used by Monero. Unlike bitcoin, Monero wanted their mining to be as GPU unfriendly as possible. The only way that they could do that was by making their hash algorithm memory-hard.
Enter CryptoNight
CryptoNight is a memory-hard hash function. It is designed to be inefficiently computable on GPU, FPGA and ASIC architectures. The brief overview of how CryptoNight works is as follows:
- The algorithm first initializes a large scratchpad with pseudo-random data.
- After that numerous read/write operations takes place at pseudo-random addresses
- contained in the scratchpad.
- Finally, the entire scratchpad is hashed to produce the final value.
The diagram below shows the schematic of the CryptoNight hash algorithm.
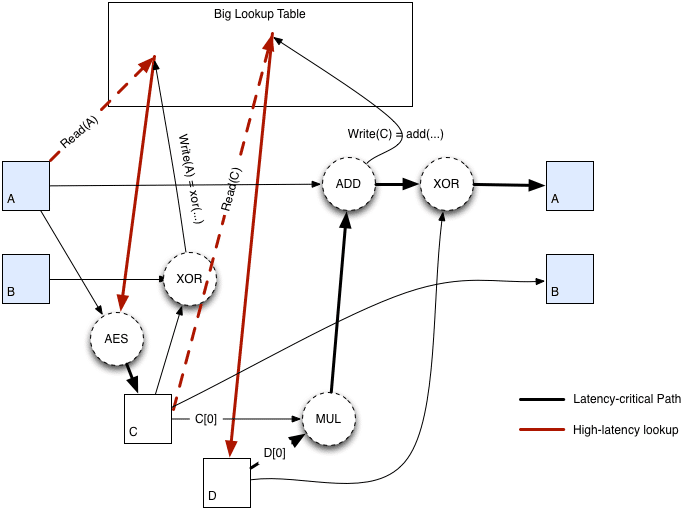
Image Credit: Dave’s Data
NOTE: All the data and code taken from CryptoNight whitepaper
Step 1: Scratchpad Initialization
The first step of the CryptoNight hash function is scratchpad initialization. The initialization takes place like this:
- The input data is hashed using Keccak with parameters b= 1600 and c=512.
- The first 32 bytes of the output of the Keccak is interpreted as an AES-256 key [AES] and expanded to 10 round keys.
- A scratchpad of 2097152 bytes (2 MiB) is allocated.
- Bytes 64-191 are extracted from the Keccak final state and split into 8 blocks of 16 bytes each.
Each block is then encrypted using the following procedure:
for i = 0..9 do:
block = aes_round(block, round_keys[i])
- AES encryption is performed on the blocks and the result is XOR’d with the round key.
- The resultant blocks become the first 128 bytes of the scratchpad. Afterwards the blocks undergo encryption again which becomes the second 128 bytes of the scratchpad. The process goes on and on until fully initialized.
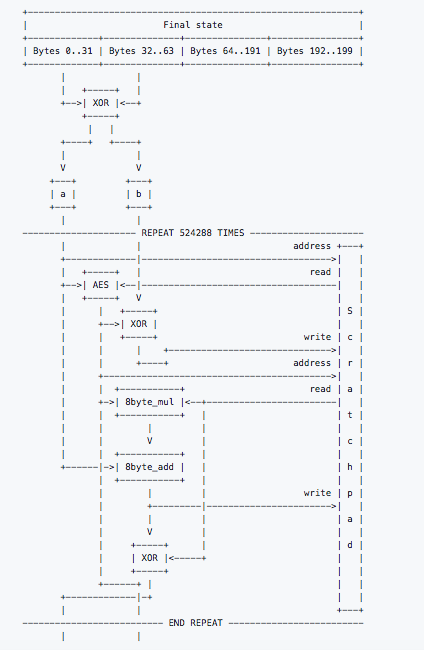
Image: Taken from GitHub. The diagram shows the Scratch Pad initialization.
Step 2: Memory Hard Loop
This step of the hash function exists to make the hash as hard to mine as possible for GPUS.
- Firstly, bytes 0..31 and 32..63 of the Keccak output are XORed, and the resulting 32 bytes are used to initialize variables a and b, 16 bytes each.
- The variables a and b then enter the main loop.
- Loop is iterated 524,288 times.
- When a 16-byte value needs to be converted into an address in the scratchpad, it is interpreted as a little-endian integer, and the 21 low-order bits are used as a byte index. However, the 4 low-order bits of the index are cleared to ensure the 16-byte alignment.
- The resultant data is entered into the scratchpad in 16-byte blocks.
Each iteration can be expressed with the following pseudo-code:

- In the code above, the 8byte_add function represents each of the arguments as a pair of 64-bit little-endian values and adds them together, component-wise, modulo 2^64. The result is converted back into 16 bytes.
- On the other hand, the 8byte_mul function, however, uses only the first 8 bytes of each argument, which are interpreted as unsigned 64-bit little-endian integers and multiplied together. The result is converted into 16 bytes, and finally the two 8-byte halves of the result are swapped.
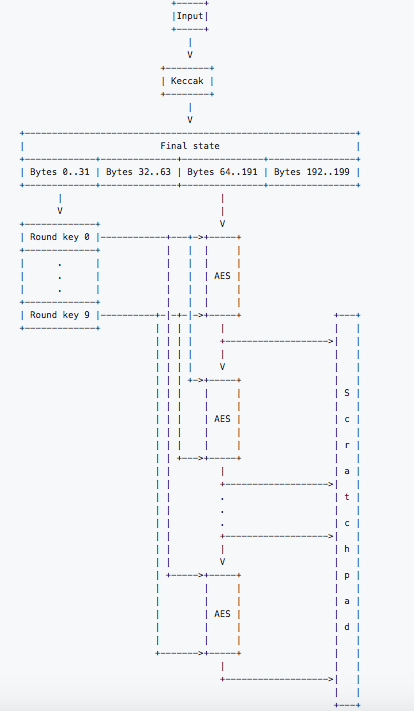
Image: This is a diagram of the Memory Hard Loop segment.
Step 3: The Result Calculation
Finally, we have the result calculation.
- When the memory-hard loop function is done, bytes 32-63 of the Keccak output is expanded into 10 AES round keys in the same manner as in the first part.
- Bytes 64..191 are extracted from the Keccak state and XOR’d with the first 128 bytes of the scratchpad.
- The resultant state is then encrypted in the same manner as in the first part, but using the new keys.
- The result is XOR’d with the second 128 bytes from the scratchpad, encrypted again, and so on.
- After XORing with the last 128 bytes of the scratchpad, the result is encrypted the last time and then the bytes 64..191 in the Keccak state are replaced with the result.
- The Keccak state is then passed through Keccak-f (the Keccak permutation) with b = 1600.
- The 2 low-order bits of the first byte of the state are used to select a hash function: 0=BLAKE-256 [BLAKE], 1=Groestl-256 [GROESTL], 2=JH-256 [JH], and 3=Skein-256 [SKEIN]. The chosen hash function is then applied to the Keccak state, and the resulting hash is FINALLY the output of CryptoNight.
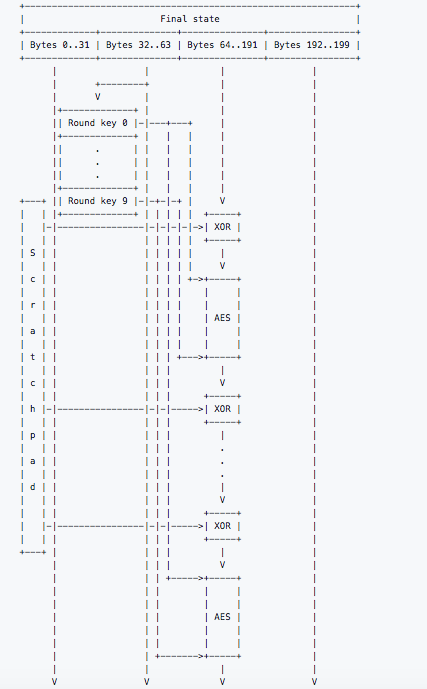
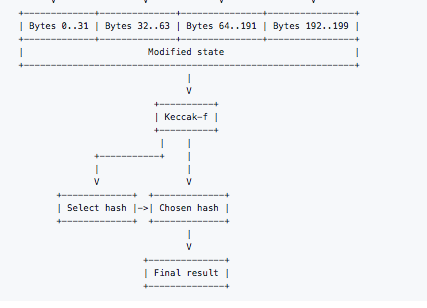
Image: Diagram of the final result generation.
Unlike the Scrypt Hashing algorithm the Cryptonight algorithm is dependent on all the previous blocks for each new block. CryptoNight is elegantly simple and its clever use of native AES encryption and fast 64 bit multipliers keeps the algorithm CPU friendly while making it as GPU unfriendly as possible.
CryptoNight in action:
Input: This is a test
Output: a084f01d1437a09c6985401b60d43554ae105802c5f5d8a9b3253649c0be6605
Conclusion
So there you have it! Four of the most commonly used hashing algorithms in cryptocurrencies. Having a basic and fundamental understanding of how they work will help you respect the sheer amount of calculations that goes on behind the scenes. Newer hashing algorithms may still come along in the future which makes the ones mentioned above completely obsolete. However, isn’t this constant innovation the most exciting part of the crypto-ecosystem?




























还没有评论,来说两句吧...