Hadoop 单机安装
**前提:**确保JDK环境已经配置好
步骤:
1、 下载并配置环境,本文默认安装目录 /opt/apps
配置安装目录并下载hadoop
# 创建apps目录mkdir /opt/apps# 进入该路径cd /opt/apps# 下载hadoop压缩包wget http://archive.apache.org/dist/hadoop/core/hadoop-2.9.2/hadoop-2.9.2.tar.gz
解压并配置环境变量
# 解压hadoop压缩包tar -zxvf hadoop-2.9.2.tar.gz# 更改名称mv hadoop-2.9.2.tar.gz hadoop# 删除下载的压缩包rm -r hadoop-2.9.2.tar.gz# 将hadoop添加到环境遍历中echo "export HADOOP_HOME=/opt/apps/hadoop" >> /etc/profileecho "export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin" >> /etc/profile# 环境变量生效source /etc/profile# 查看hadoop是否安装成功hadoop version
安装成功如下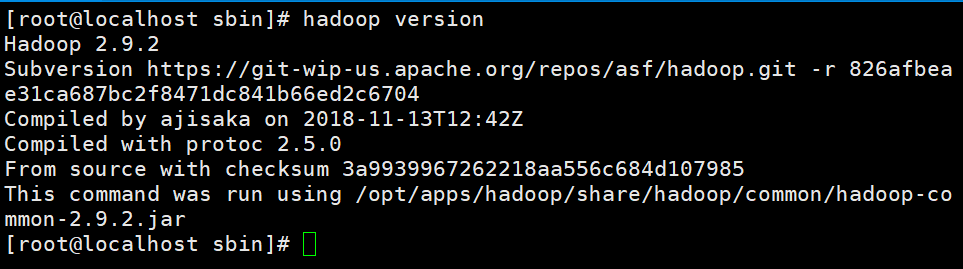
2、配置hadoop文件,给改configuration里内容
cd /opt/apps/hadoop/etc/hadoop
① vim core-site.xml (用于定义系统级别的参数,如HDFS URI 、Hadoop的临时目录等)
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value><description>配置hdfs端口,默认9000</description></property><property><name>hadoop.tmp.dir</name><value>/opt/apps/hadoop/tmp</value><description>hadoop临时工作目录</description></property><property><name>hadoop.native.lib</name><value>false</value><description>Should native hadoop libraries, if present, be used.</description></property></configuration>
② vim hadoop-env.sh (用来定义hadoop运行环境相关的配置信息)
更改文件中 JAVA_HOME 为你的 JAVA_HOME 路径
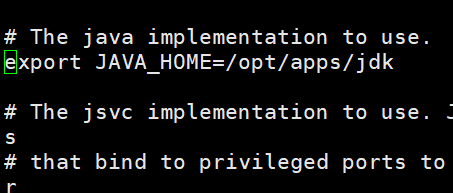
③ vim hdfs-site.xml (如名称节点和数据节点的存放位置、文件副本的个数、文件的读取权限等)
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.secondary.http.address</name><!--这里是你自己的ip,端口默认--><value>localhost:50090</value></property></configuration>
④ cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
⑤ vim yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><!-- 自己的ip端口默认 --><value>localhost</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
3、启动Hadoop
cd /opt/apps/hadoop/sbin# 格式化hadoop namenode -format# 启动./start-all.sh# 查看进程情况jps
出现如下成功安装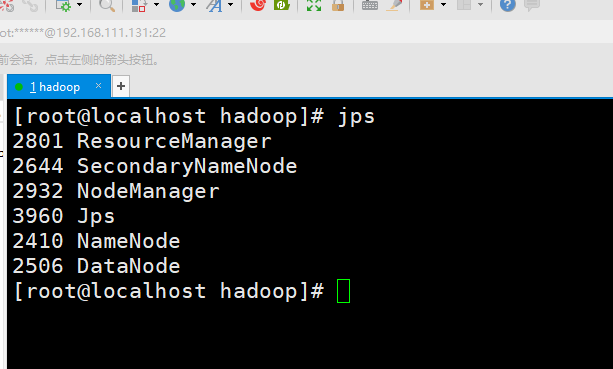
访问端口 50070 可以访问网页端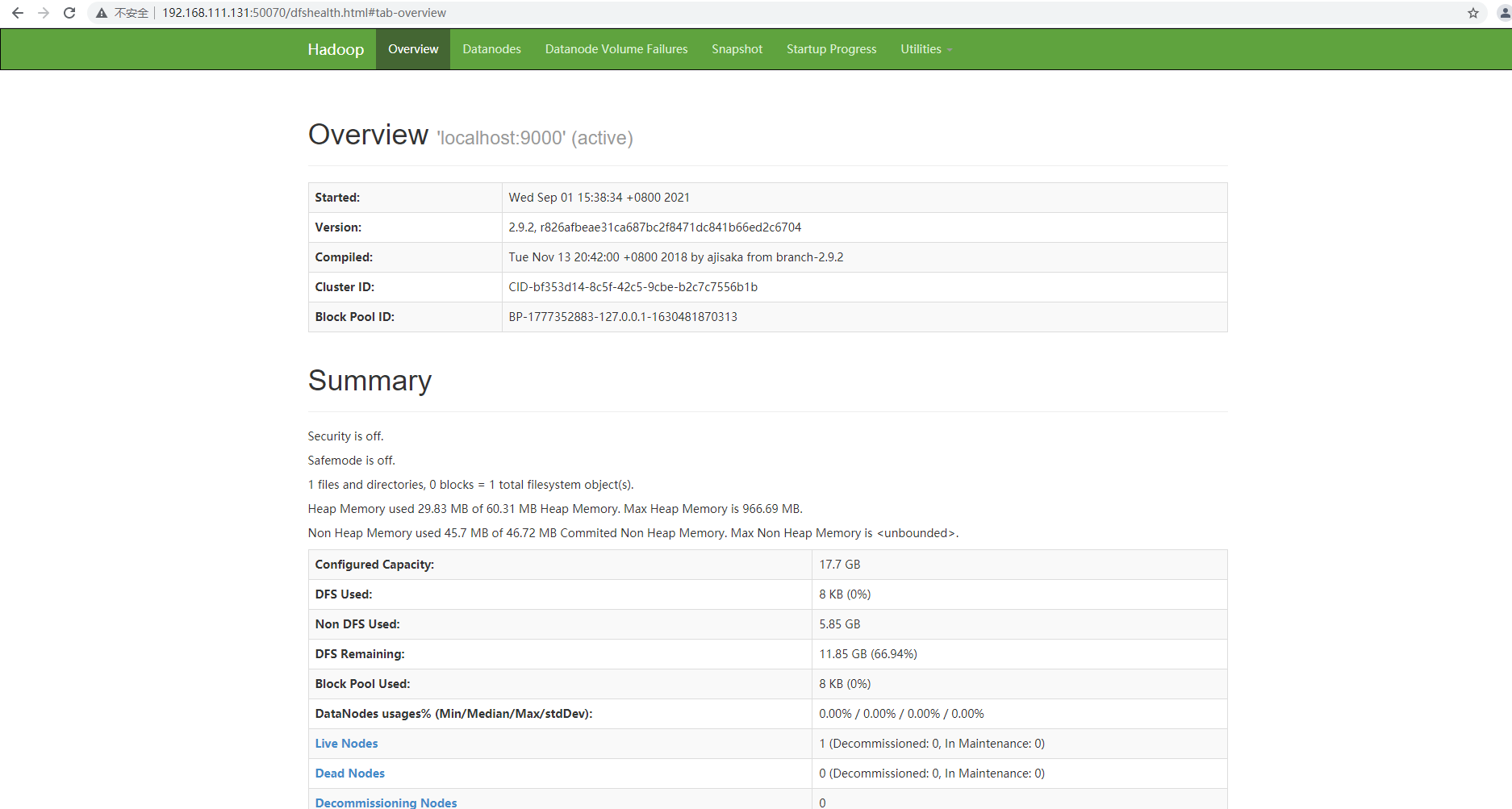

























")








还没有评论,来说两句吧...