Python爬取招聘网站数据,并可视化展示招聘需求、薪资、招聘人数等数据
课程亮点
- 爬虫的基本流程
- re正则表达式模块的简单使用
- requests模块的使用
- 保存csv
环境介绍
- python 3.8 >>> 安装包找木子老师领取
- pycharm 2021专业版 需要激活可以找木子老师领取
- pycharm 社区版 (免费) 没有主题
专业版 (需要激活码)
模块使用
- requests >>> pip install requests (数据请求模块)
- re
- json
- csv
- time
如果你要去爬取网站数据内容
- 就要去分析 数据是从哪里来得
通过开发者工具进行分析
(找数据内容) - 发送请求 对于目标网址发送请求
- 获取数据内容 网页源代码 response.text
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
点这里即可免费在线观看
爬虫代码
导入模块
import requests # 数据请求模块 pip install requestsimport re # 正则表达式模块import json # 序列化与反序列化import pprint # 格式化输出模块import csvimport time # 时间模块
发送请求 对于目标网址发送请求
url = f'https://search.51job.com/list/010000%252C020000%252C030200%252C040000%252C180200,000000,0000,00,9,99,python,2,1.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'}# 发送请求 requests调用里面get请求方法 然后把 url 以及 headers 传进去response = requests.get(url=url, headers=headers)# <Response [200]> 返回响应对象 response 200状态码 表示请求成功
解析数据内容 提取想要数据
# re正则表达式 re正则表达式 可以直接提取字符串数据# 使用re模块里面findall()方法html_data = re.findall('window.__SEARCH_RESULT__ = (.*?)</script>', response.text)[0]# 正则匹配出来的数据 是列表 []json_data = json.loads(html_data)['engine_jds']print(json_data)for index in json_data:# 等号左边都是自定义变量# pprint.pprint(index)title = index['job_title'] # 职位名字company_name = index['company_name'] # 公司名字money = index['providesalary_text'] # 薪资job_welf = index['jobwelf'] # 福利# job_info = index['attribute_text'] #基本信息area = index['attribute_text'][0] # 城市exp = index['attribute_text'][1] # 经验edu = index['attribute_text'][2] # 学历company_type = index['companyind_text'] # 公司类型date = index['updatedate'] # 发布日期href = index['job_href'] # 招聘详情页# 复制一行 ctrl + Ddit = {'职位名字': title,'公司名字': company_name,'薪资': money,'公司福利': job_welf,'地区': area,'经验': exp,'学历': edu,'公司类型': company_type,'发布日期': date,'详情页': href,}print(title, company_name, money, area, exp, edu, job_welf, company_type, date, href)csv_writer.writerow(dit)
保存数据
f = open('数据.csv', mode='a', encoding='utf-8', newline='')csv_writer = csv.DictWriter(f, fieldnames=['职位名字','公司名字','薪资','公司福利','地区','经验','学历','公司类型','发布日期','详情页',])csv_writer.writeheader() # 写入表头
运行代码

数据可视化代码
导入模块
import pandas as pdfrom pyecharts.charts import *from pyecharts import options as optsimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=False
导入数据
boss = pd.read_csv('data.csv', engine='python', encoding='utf-8')boss
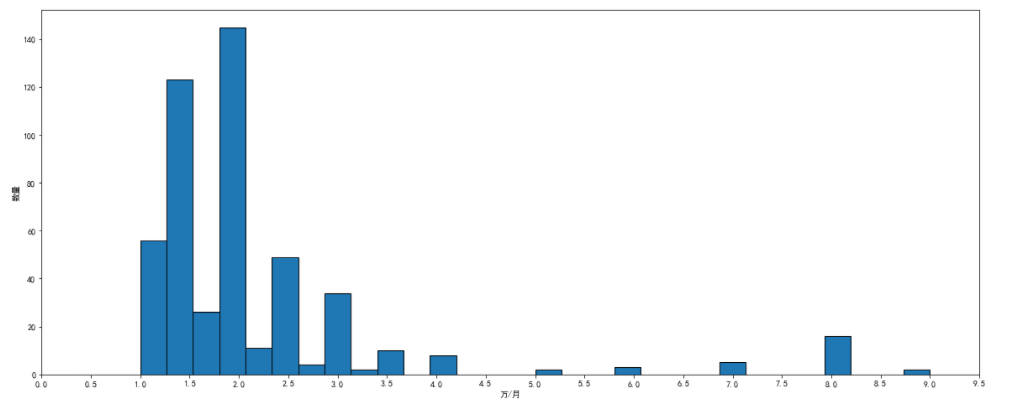
薪资区间
import numpy as npdef shulie(first,end,step):x = []for i in np.arange(first, end,step):x.append(i)return xlist_1 = shulie(0,10,0.5)boss['top'].plot.hist(bins=30,figsize=(20,8),edgecolor="black")plt.xticks(list_1)plt.xlabel('万/月')plt.ylabel('数量')plt.show()
经验、学历要求情况
c = (Pie(init_opts=opts.InitOpts(width="1000px", height="600px", bg_color="#2c343c")).add(series_name="经验需求占比",data_pair=data_pair_1,rosetype="radius",radius="55%",center=["25%", "50%"],label_opts=opts.LabelOpts(is_show=False, position="center", color="rgba(255, 255, 255, 0.3)"),).add(series_name="学历需求占比",data_pair=data_pair_2,radius="55%",center=["75%", "50%"],label_opts=opts.LabelOpts(is_show=False, position="center", color="rgba(255, 255, 255, 0.3)"),).set_series_opts(tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"),label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"),).set_global_opts(title_opts=opts.TitleOpts(title="经验、学历需求占比",pos_left="center",pos_top="20",title_textstyle_opts=opts.TextStyleOpts(color="#fff"),),legend_opts=opts.LegendOpts(is_show=False),).set_colors(["#D53A35", "#334B5C", "#61A0A8", "#D48265", "#749F83"]))c.render_notebook()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TbQWT2OU-1632641295183)(https://upload-images.jianshu.io/upload\_images/27098966-2a173fd9f7108354.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)\]
哪些地区招聘人员比较多
from pyecharts.globals import SymbolTypeaddress_count = boss.groupby('地区').count()['公司名字'].sort_values()x = address_count.index.tolist()y = address_count.values.tolist()c = (PictorialBar().add_xaxis(x).add_yaxis("",y,label_opts=opts.LabelOpts(is_show=False),symbol_size=18,symbol_repeat="fixed",symbol_offset=[0, 0],is_symbol_clip=True,symbol=SymbolType.ROUND_RECT,).reversal_axis().set_global_opts(title_opts=opts.TitleOpts(title="地区人员招聘数量"),xaxis_opts=opts.AxisOpts(is_show=False),yaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=False),axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(opacity=0)),),))c.render_notebook()

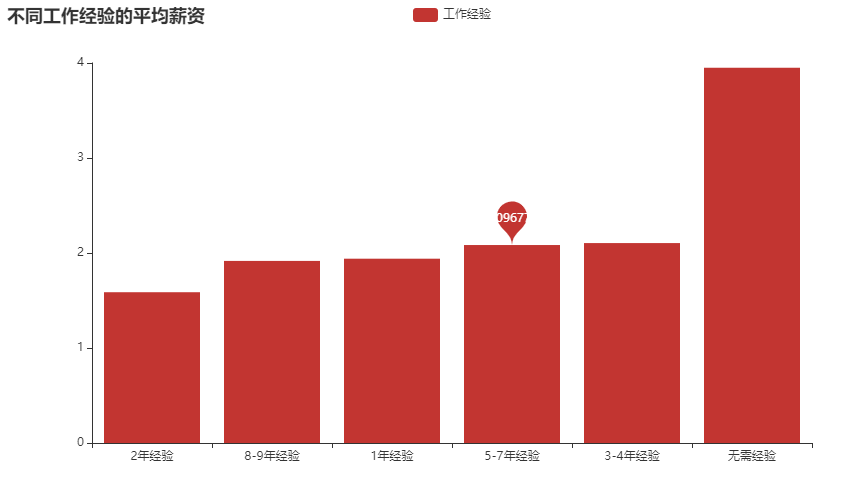
经验要求 和 薪资情况的情况 是不是薪资越高 经验要求越高
mean = boss.groupby('经验')['工资平均'].mean().sort_values()x = mean.index.tolist()y = mean.values.tolist()c = (Bar().add_xaxis(x).add_yaxis("工作经验",y,markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(name="无需经验", coord=[x[3], y[3]], value=y[3])])).set_global_opts(title_opts=opts.TitleOpts(title="不同工作经验的平均薪资")).set_series_opts(label_opts=opts.LabelOpts(is_show=False)))c.render_notebook()
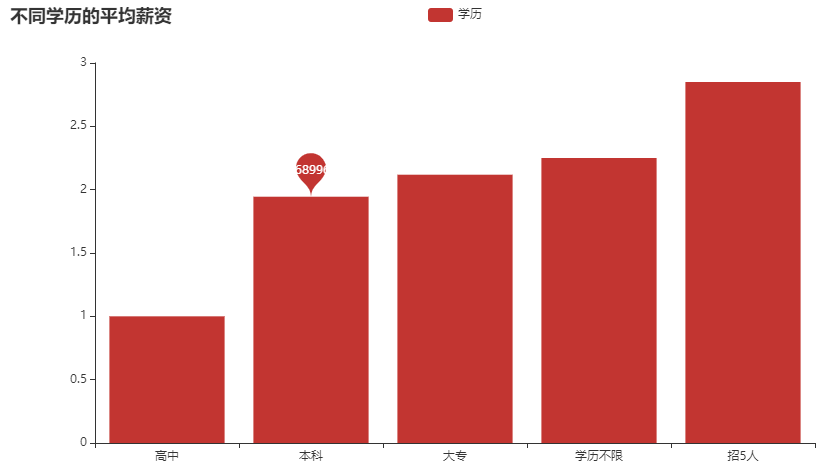
mean = boss.groupby('学历')['工资平均'].mean().sort_values()x = mean.index.tolist()y = mean.values.tolist()c = (Bar().add_xaxis(x).add_yaxis("学历",y,markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(name="学历不限", coord=[x[1], y[1]], value=y[1])])).set_global_opts(title_opts=opts.TitleOpts(title="不同学历的平均薪资")).set_series_opts(label_opts=opts.LabelOpts(is_show=False)))c.render_notebook()
词云图
公司福利
import jiebawords = jieba.lcut(text)#通过遍历words的方式,统计出每个词出现的频次counts = { }for word in words:if len(word) == 1:continueelse:counts[word] = counts.get(word,0) + 1c = (WordCloud().add(series_name="热点分析", data_pair=new, word_size_range=[6, 66]).set_global_opts(title_opts=opts.TitleOpts(title="公司福利", title_textstyle_opts=opts.TextStyleOpts(font_size=23)),tooltip_opts=opts.TooltipOpts(is_show=True),))c.render_notebook()


























Oracle中用Exp命令导出指定用户下的所有表的前N行数据,并用imp数据导入到本地数据库中--修改编码")








还没有评论,来说两句吧...