集合概览
在网上找了个集合类图,在此表示感谢原作者: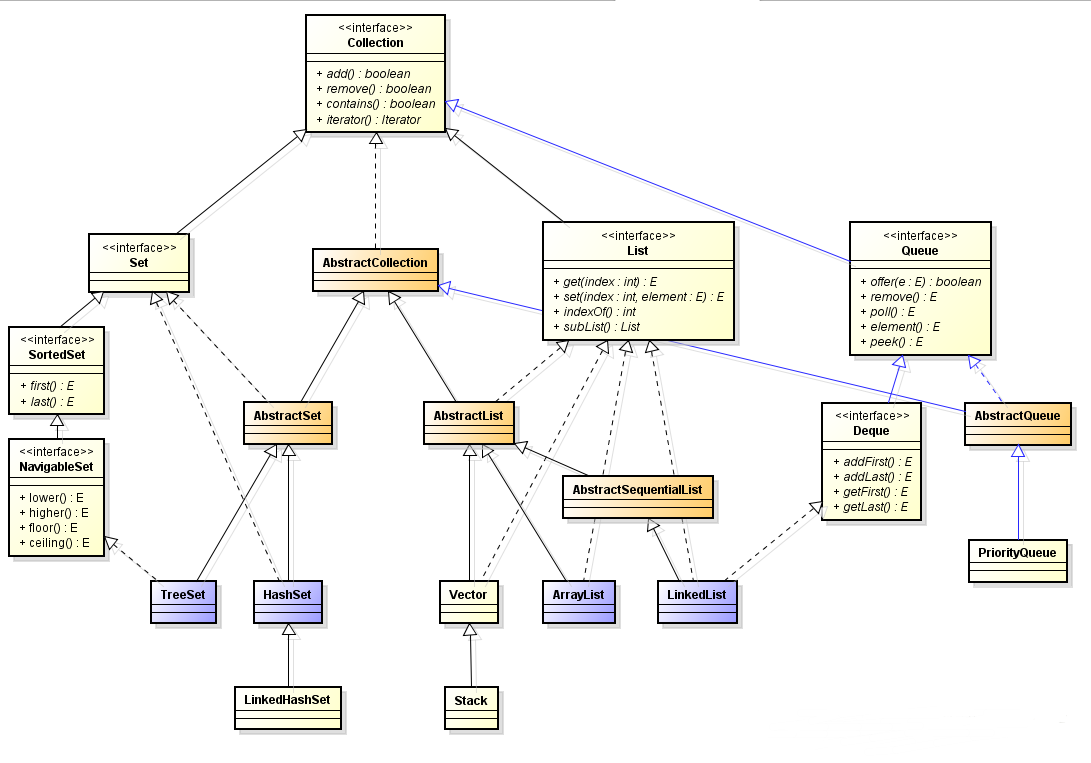
1.Set
Set集合不允许包含相同的元素,如果试图把两个相同元素加入同一个集合中,add方法返回false。
Set判断两个对象相同不是使用==运算符,只要两个对象用equals方法比较返回true就是重复。
从Java源码来看,Java是先实现了Map,然后通过包装一个value都为null的Map就实现了Set集合。
1.1 HashSet
- HashSet集合中,当hashCode()返回值相等,且equals()方法也相等的两个元素才叫重复。
- HashSet速度快的原因:
hash算法的价值在于速度,当需要查询集合中某个元素时,hash算法可直接根据该元素的hashcode值计算出该元素的存储位置 - HashSet特性:
不是线程同步的
不能保证元素的插入顺序,顺序有可能发生变化
存储的元素可以是null,但只能放入一个null
1.2 TreeSet
TreeSet支持两种排序方式,自然排序 和定制排序。
自然排序(默认排序方式):
使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按升序排列。如:
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
TreeSet判断两个对象是否相等的唯一标准是:这两个对象的compareTo方法返回结果为0
定制排序:
参考:http://blog.csdn.net/zcl_love_wx/article/details/60757075
注:
TreeSet在添加第一个元素时,由于不会与其他任何元素进行比较,所以不会实现Comparable接口,只有在添加后续的元素时,才会实现Comparable接口,然后调用compareTo方法比较,然后按升序排列。
如果希望TreeSet能正常运作,所有元素只能是同一种数据类型。
1.3 LinkedHashSet
- LinkedHashSet需要维护元素的插入顺序(这样使得元素看起 来像是以插入顺序保存的),所以性能略低于HashSet。
- LinkedHashSet在但在迭代访问全部元素时会有很好的性能,因为它以添加顺序直接访问。
1.4 总结
只有当一个集合需要保持顺序时,才应该用TreeSet,否则都应该用HashSet
2. List
List判断两个对象的相等条件是,equals()方法的返回值为true
2.1 ArrayList和Vector几个常见方法
addAll(int index,Collection c):将集合c插入到List集合的index索引处
set(int index,Object o):将集合中index索引处的元素替换为o,并返回旧元素。
subList(int from,int to):返回从from到to(不包含)的子集合。
其实大多数截取从一个索引到另一个索引的所有值,都是不包含后一个索引的值的。最初我一直记不清楚,后来发现,如果两个索引的值都包含的话,我们将永远不能做到只取一个值的情况。
replaceAll(UnaryPerator uo):根据uo指定的计算规则,重新设置List集合
sort(Comparator c):根据自定义的比较器指定的计算规则对List排序。
2.2 ArrayList和Vector集合的listIterator()方法返回一个ListIterator对象,扩展了操作集合的方法:
hasPrevious():是否有上一个元素
previous():返回上一个元素
add(String e):添加一个元素。Iterator就不可以。
ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历。但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。nextIndex()和previousIndex()方法可以定位当前元素的索引位置。Iterator就不可以。
2.3 ArrayList、Vector、LinkedList的区别
- ArrayList 和Vector底层都是采用数组方式存储数据,所以在查询时效率特别高(直接按下标查询)。但是插入和删除数据时涉及到数组元素移动等内存操作,所以相对来说就慢。
- Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差
- LinkedList使用双向链表实现存储,查询时要按索引下标进行向前或向后遍历,所以慢。但是插入数据时只需要记录本项的前后项,即更改一下指针的指向,所以插入速度较快!
- LinkedList也实现了Deque接口,所以也可被当成双端队列使用,也可当成栈使用,也可当成队列使用。
2.4 Stack类
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。
peek():返回栈顶第一元素,但并不弹出。
pop():返回栈顶第一个元素,并弹出。
push(Object o):将元素加入栈顶。
empty方法测试堆栈是否为空
search方法检测一个元素在堆栈中的位置。
Stack刚创建后是空栈。
2.5 固定长度的List
Arrays类的asList(Object … a)方法,可以将一个数组转成一个List集合,而该集合既不是ArrayList的实现类,也不是Vector的,而是Arrays的内部类ArrayList的实例。Arrays.ArrayList是一个固定长度的List集合,程序只能遍历该集合,不能进行增、删操作。
2.6 使用List集合建议
- 遍历List集合
对于ArrayList 和Vector集合使用get(i)遍历
对于LinkedList集合使用Iterator遍历 - 包含大量数据的List集合,如果经常插入、删除,用LinkedList好。
- 有多个线程访问List时,可使用Collections将集合包装成线程安全的集合。
3. Queue集合
- Queue集合用于模拟队列。队列是先进先出的容器。
- Deque代表双端队列,可同时从两端添加或删除元素。它不仅可以当成双端队列,还可以当成栈使用,所以也有pop()、push()方法。
- PriorityDeque是按队列元素的大小写进行重新排序的(和TreeSet一样也有自然排序和定制排序)。所以pop()或peek()方法取出的是最小元素。
- ArrayList和ArrayDeque底层都采用一个动态的、可重新分配大小的Object[]数组形式保存集合,因此在随机访问时性能很好,但插入、删除操作性能差。
- LinkedList也实现了Deque接口,所以也可被当成双端队列使用,也可当成栈使用,也可当成队列使用。当然,LinkedList实现的队列也是线程不安全的。
4. 线性表性能分析
数组是以一块连续内存区来保存所有元素的容器。对于所有内部基于数组的集合实现(如ArrayList、Vector),使用随机访问的性能比使用Iterator迭代访问要好,因为随机访问会被映射成对数组的访问。但插入和删除数据时涉及到数组元素移动等内存操作,所以相对来说就慢。
5. 操作集合的工具类:Collections
5.1 对List集合元素进行排序
reverse(List list) 反转指定的list集合
sort(List list) 按自然排序将list排序
sort(List list,Comparator c) 按排序器c指定的规则将list进行排序
swap(List list ,int i , int j) 将list集合中索引为i与j的元素对调交换
5.2 查找、替换的方法
int binarySearch(List list, Object key):二分法搜索key对应的元素在list里的索引。前提是list已经有序。
Object max(Collection c):返回集合中最大元素。按自然排序的结果。返回最小元素一样。
Object max(Collection c,Comparator comp):按给定的排序规则返回最大元素。返回最小元素一样。
void fill(List list,Object obj):用obj替换list的所有元素
int frequency(Collection c,Object o):o在c中出现的次数
int indexOfSubList(List source,List target):返回target子集在source中第1次出现的索引,没有返回-1
int lastIndexOfSubList()List source,List target):返回target子集在source中最后一次出现的索引,没有返回-1
boolean replaceAll(List list,Object oldVal,Object newVal):用newVal替换list中的所有oldVal
5.3 同步控制:SynchronizedXxx()方法
Java集合中,HashSet、TreeSet、HashMap、TreeMap、ArrayList、LinkedList、ArrayDeque等 都是线程不安全的,可通过SynchronizedXxx方法包装成线程安全的集合,如:
Collection c = Collections.synchronizedCollection(new ArrayList<>());List list = Collections.synchronizedList(new ArrayList());Set set = Collections.synchronizedSet(new HashSet());Map map = Collections.synchronizedMap(new HashMap<>());
6. Map
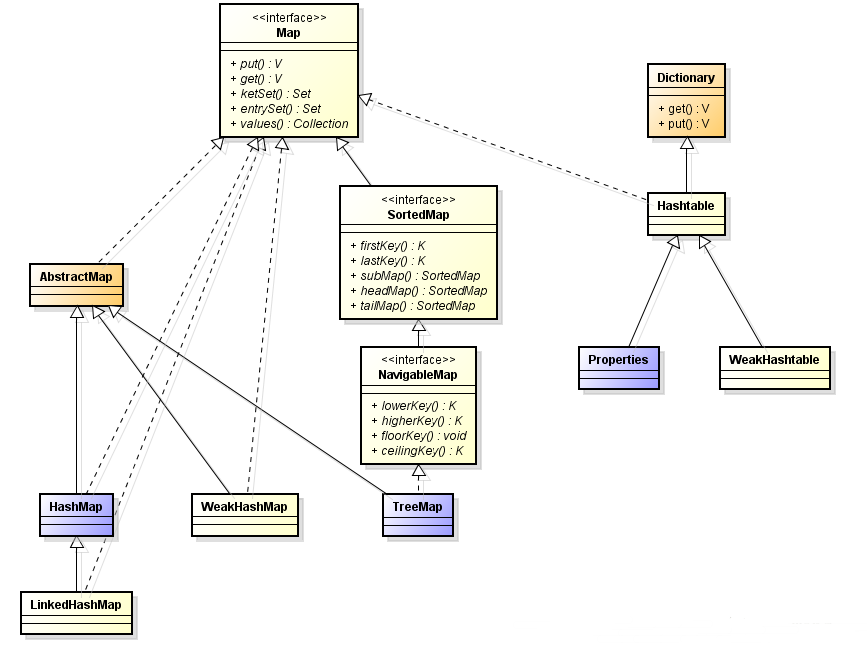
6.1. Map常见方法
keySet():返回Map集合里所有key组成的Set集合
entrySet():返回Map中所有Entry对象组成的set集合,Entry是Map的内部类。
forEach(BiConsumer action):Java8新增遍历Map的方法
6.2. Entry这个内部类,封装了一个key-value对,介绍其如下三个方法:
Object getKey():返回Entry里包含的key值
Object getValue():返回Entry里包含的value值
Object setValue(V value):设置Entry里包含的value,并返回新设的值
6.3 TreeMap
如果程序需要一个总是排好序的Map时,则应该考虑用TreeMap
TreeMap和TreeSet有很多类似之处
6.4 HashMap
6.5LinkedHashMap
LinkedHashMap也使用双端链表来维护key-value对的次序,和linkedHashSet一样也维护了插入顺序,所以迭代也快。
6.6 WeakHashMap
WeakHashMap中只保留了对实际对象的弱引用;
如果WeakHashMap中的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,WeakHashMap也可以自动删除这些key所对应的key-value对。
WeakHashMap<String, String> w = new WeakHashMap<>();w.put(new String("语文"), new String("良好"));w.put("Java", "优秀");w.put("数学", new String("中等"));System.gc();System.out.println(w);//{Java=优秀, 数学=中等},语文被回收了
6.7 Properties
Properties相当于一个key、value都为String类型的Map
Properties类可以把键值对和属性文件关联起来,从而可以key-value对写入属性文件,也可以把属性文件中的”属性名=属性值”加载到Properties对象中。
Properties修改key、value的方法:
String getProperty(String key ):获取Properties中key对应的value
setProperty(String key,String value):给Properties设置键和值
读写属性文件的方法:
void load(InputStream in):从属性文件中加载所有key-value对到Properties里
void store(OutPutStream out, String comments):将Properties中的key-value对输出到指定的属性文件中
示例:
Properties outP = new Properties();outP.setProperty("username", "peter");outP.setProperty("password", "123456");//将两个key-value对添加到a.txt属性文件中outP.store(new FileOutputStream("a.txt"), "备注信息");Properties inP = new Properties();//将属性文件加载到Properties里inP.load(new FileInputStream("a.txt"));System.out.println(inP.getProperty("username"));
6.8 Map性能分析
HashMap是为快速查询设计的,其实现原理是利用key的hash值快速定位到value值在hash表的位置。但HashMap底层是采用数组来存储key-value对。所以在使用containsKey(Object key)或containsValue(Object val)时只能通过遍历数组来查询。
TreeMap存储数组的结构是二叉树,所以在使用containsKey(Object key)或containsValue(Object val)时都是二分查询,要快于HashMap的这两个操作。
Hash表里可以存储元素的位置被称为桶(bucket)。通常桶里只存一个元素,此时有最好的性能。hash算法可根据hashCode值计算出“桶”的存储位置,接着从桶中取出元素。当发生hash冲突时,一个桶会存储多个元素,它们以链表形式存储,且必须安顺序搜索。
hash属性:
- 容量:hash表中桶的数量
- 尺寸:当前hash表中记录的数量
3.负载因子:尺寸/容量。为0时 表示空hash表;为0.5时 表示半满的hash表
轻负载的hash表冲突少,适宜插入、查询,但用Iterator迭代慢。
较高的负载极限可降低hash所占内存空间,但会增加查询时间。
默认负载极限为:0.75

























")








还没有评论,来说两句吧...