新书上市 | 世界名校数据挖掘经典《斯坦福数据挖掘教程(第3版)》
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
此曲只应天上有,人间难得几回闻。
《斯坦福数据挖掘教程(第3版)》上架之后,这是我们第一次整篇文章介绍这本书。

这本书相当受欢迎(前两个版本累计销量超过 5 万册),尤其是受学校青睐——在此也说声抱歉,出于出版时间的原因,很多学校依然采用了旧版作为教材;同时也请知悉,新版已上架,正在使用这本书作为教材的学校可以考虑更新了。
实际上,这本书已经在大家面前出过 2 次镜了,一次是 2020 年图灵奖公布的次日图灵君用一篇文章讲了讲图灵奖得主之一 Jeffrey Ullman 和这本书「不一样的」故事;一次是 423 活动那次,这本书在没有赶上大促优惠的情况下进入了新书畅销榜单。
除了是一本畅销多年的世界名校数据挖掘入门经典书,《斯坦福数据挖掘教程(第3版)》之于 Jeffrey Ullman 和弟子 Anand Rajaraman 还有特别的意义。那就是这本书原本只是作为开源电子版出版的,后来才有了纸质书的诞生,个中原因大家可以在文末链接阅读相关文章。
好了,回到这本书,我们继续说说它的缘起。本书源于Ullman 及弟子 Rajaraman 在斯坦福大学教授多年的一门季度课程——「多年」真的不是随便叫叫的,我去这本书的网站上看了看,斯坦福大学开设这门课程,最早可以追溯到 2000 年,着实佩服。
课程名为“Web 挖掘”(编号 CS345A),原本是为高年级研究生设计的,没成想高年级本科生也非常感兴趣,于是现在就成为本科生和研究生兼修的一门课程。Jure Leskovec 到斯坦福大学任职后,共同对相关材料进行了重新组织。他开设了一门有关网络分析的新课程 CS224W, 并为 CS345A 增加了一些内容,重新编号为 CS246。三位作者还开设了一门大规模数据挖掘的项目课程 CS341。目前本书包含了以上三门课程的所有教学内容。

图书核心特色
这本书核心的特色是:它是一本数据挖掘领域全景路线图式的入门参考技术书,下面解释一下关键词。
1.全景路线图
一方面可以让你了解数据挖掘这个大领域下的各个小领域;
另一方面让你可以纵览整个数据构建模型的过程,这个过程中你会遇到什么问题,尤其是从普通规模数据到极大规模数据发生了哪些状况,你的解决方案是如何转换的。
2.入门
跟上面一条紧密关联。普通书入门从简单操作开始,一步步来,读者见树木而不见森林,好书入门从全景图开始,教读者抓核心内容,对整个领域了然于胸之后深入自己感兴趣的关键点。而这本书介绍的正是高手入门之道,书中并没有每个细分领域的详细讲解,但是为你展示了最新的参考论文和进阶资料,方便你进一步探索。
3.技术
虽然有概念,但并非聚焦于概念,而是教你怎么用,可直接应用于实际的大规模数据挖掘工作——海量 Web 数据是目前大数据挖掘工作的核心,数据分析师、数据科学家、机器学习专家都不可错过。

接下来让我们来详细看看书中的内容。
图书核心内容
本书是关于数据挖掘的,但是主要关注极大规模数据的挖掘。“极大规模”的意思是,这些数据大到无法在内存中存放。因为本书重点强调数据的规模,所以例子大多来自 Web 本身或者 Web 上导出的数据。另外,本书从算法的角度来看待数据挖掘,即数据挖掘是将算法 应用于数据,而不是使用数据来“训练”某种类型的机器学习引擎。
本书的主要内容包括:
(1) 分布式文件系统和 MapReduce,其中后者用于创建在极大规模数据集上成功应用的并行算法;
(2) 相似性搜索,包括最小哈希和局部敏感哈希的关键技术;
(3) 数据流处理以及针对快速到达、须立即处理且易丢失的数据的专用算法;
(4) 搜索引擎技术,包括谷歌的 PageRank、链接作弊检测以及计算网页导航度(hub)和权威度(authority)的 HITS 方法;
(5) 频繁项集挖掘,包括关联规则、购物篮分析、A-Priori 算法及其改进;
(6) 极大规模高维数据集的聚类算法;
(7) Web 应用中的两个关键问题——广告管理和推荐系统;
(8) 对极大规模的图(特别是社会网络图)的结构进行分析和挖掘的算法;
(9) 通过降维来获得大规模数据集的重要性质的技术,包括 SVD 和隐性语义索引;
(10) 可以应用于极大规模数据的机器学习算法,包括感知机、支持向量机、梯度下降法、决策树和神经网络;
(11) 神经网络与深度学习,包括最重要的几个特例——卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM)。
用思维导图展示一下图书的内容。
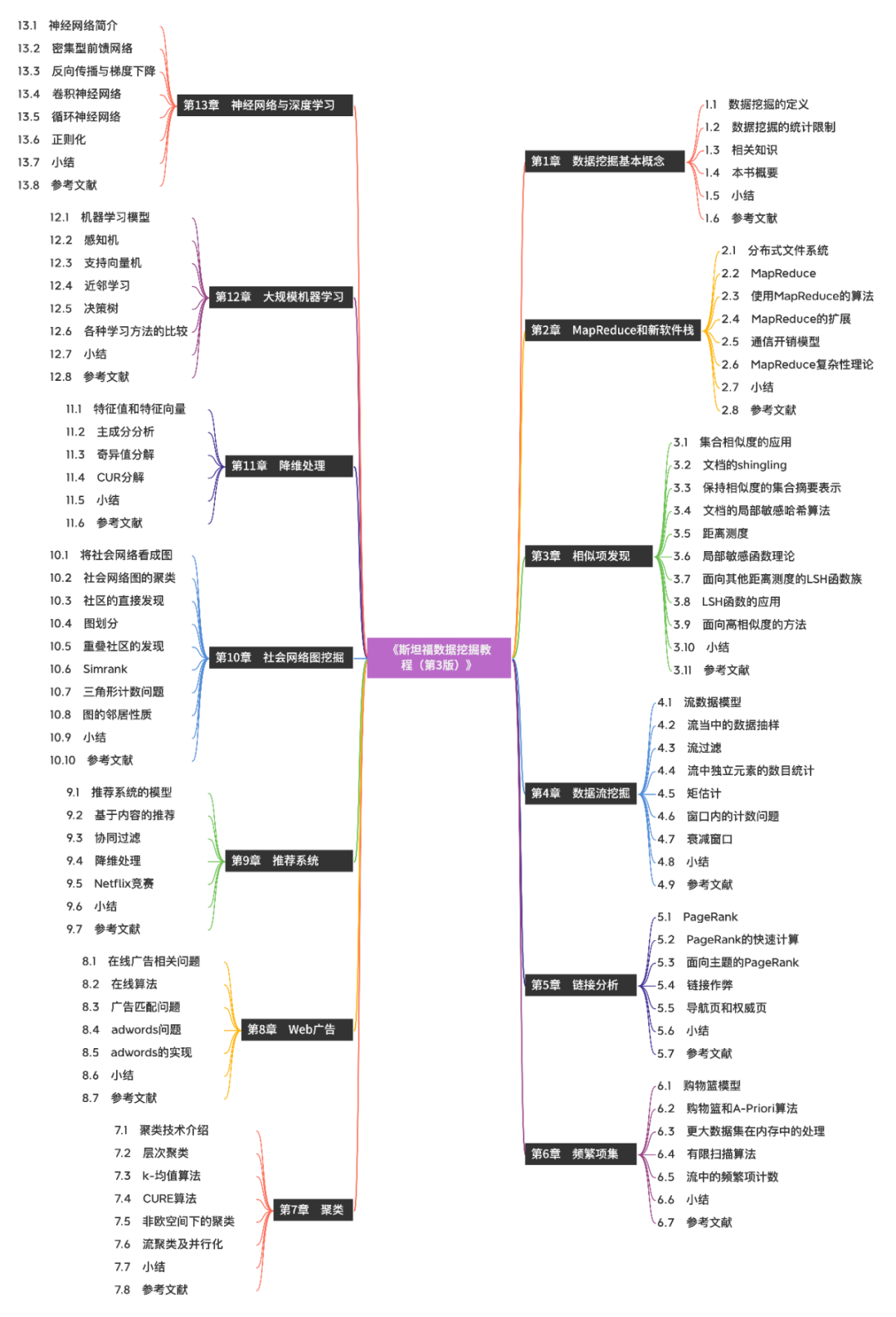
(放大可查看大图)
作译者团队
这本《斯坦福数据挖掘教程》与《数据挖掘导论(完整版)》同为国内读者最喜爱的数据挖掘入门书之一。作者团超级强大,第一作者是 AI 领域无人不知的 Jure Leskovec,他在图神经网络方面的研究用“顶尖”形容不为过。第三作者 Jeffrey Ullman 为 2020 年图灵奖得主,因在编程语言实现领域对基础算法和理论的贡献而获奖。
在翻译上,由国内知名 NLP 专家王斌老师担纲翻译,王斌老师独自翻译了前两个版本。到第 3 版,曾就读于斯坦福大学 Jure 实验室的王达侃老师加入,共同翻译。

Jure Leskovec(尤雷·莱斯科夫)
近年来最优秀的 AI 科学家之一(其实没有“之一”这两个字,估计 99% 人也不会反对,从这里你就知道 Jure 的实力了,有其他很多媒体专门写过 Jure 有多强大,回头我们转载一篇文章来看看)。
Pinterest 公司首席科学家,斯坦福大学计算机科学系副教授,研究方向为大型社交和信息网络的数据挖掘。
他的研究成果获得了很多奖项,如 Microsoft Research Faculty Fellowship、Alfred P. Sloan Fellowship 和 Okawa Foundation Fellowship,还获得了很多最佳论文奖,同时也被《纽约时报》《华尔街日报》《华盛顿邮报》《连线》及 NBC、CBC 等流行的社会媒体刊载。
他还创建了斯坦福网络分析平台(SNAP)。
Anand Rajaraman(阿南德·拉贾拉曼)
数据库和 Web 技术领域领军者,硅谷连续创业者和风险投资人,斯坦福大学计算机科学系助理教授。
自 1996 年起创立过多家公司,这些公司先后被亚马逊、谷歌和沃尔玛集团收购,而他本人历任亚马逊技术总监、沃尔玛负责全球电子商务业务的副总裁。之后创立了风投公司 Milliways Ventures 和 Rocketship VC,投资过 Facebook、Lyft 等众多公司。
作为学者,他主要研究数据库系统、Web 和社交媒体,他的研究论文在学术会议上获得了多个奖项,他在 2012 年被《快公司》杂志列入“商界最具创造力 100 人”。
Jeffrey Ullman(杰弗里·厄尔曼)
计算机科学家,美国国家工程院院士,2020 年图灵奖得主。
早年在贝尔实验室工作,之后任教于普林斯顿大学,十年后加入斯坦福大学直至退休,一生的科研、著书和育人成果卓著。
他是 ACM 会员,曾获 SIGMOD 创新奖、高德纳奖、冯诺依曼奖等多项科研大奖;合著有“龙书”《编译原理》、数据库名著《数据库系统实现》等多部经典著作。
Ullman 培养了很多了不起的学生,其中包括谷歌联合创始人 Sergey Brin,本书第二作者也是他的得意弟子。目前担任 Gradiance 公司 CEO。
王斌博士
小米 AI 实验室主任,NLP 首席科学家。中国中文信息学会理事,《中文信息学报》编委。
加入小米公司之前,是中科院研究员、博导及中科院大学教授。译有《信息检索导论》《大数据:互联网大规模数据挖掘与分布式处理》和《机器学习实战》等书。
王达侃
优刻得 AI 部门负责人,曾任 WeWork Research & Applied Science 中国区负责人,并曾在 LinkedIn、Twitter 和微软亚洲研究院负责 AI 以及大数据方向的研发工作。
硕士毕业于斯坦福大学计算机系,本科毕业于上海交通大学 ACM 班。
国内外读者好评
| Amazon 读者
斯坦福大学“海量数据挖掘”公开课课参考书

我买这本书是为了参加斯坦福大学 MMDS 的在线课程,但后来决定全面阅读这本书(课程不包括一些高级主题)。这本书的内容是非常容易理解的。例如,在第 5 章中,作者介绍了 PageRank 算法,不同于一般书通过概率和线性代数(马尔科夫链和特征向量)来介绍它,他们稍微介绍了一下理论,之后提供了许多例子,所以这本书的实用性深得我心。概率论和线性代数方面的知识会有帮助,但不强求,不过知道一些非常基本的概念,如矩阵乘法等是必需的。
这本书涵盖的主题相当广泛,从 MapReduce 和位置敏感哈希(LSH),再到图和大规模机器学习算法。朋友们,值得拥有。
数据挖掘就看这本书(某大学教授)

这本书是我在数据挖掘方法方面的首选参考书。名声在外的作者团队们对于自己的写作主题门儿清。这些材料来自于作者所教授的几门斯坦福大学计算机科学课程。就第 3 版而言,写作清晰、简洁,无重大错误。
本书涵盖了许多最常用的数据挖掘方法的理论和实践方面。作者不仅讨论了这些算法如何工作的理论,还对其局限性和常见的失败进行了深入探讨。
我把这本书作为我教授的课程的补充教材。该书的处理水平适合高级本科生和初级研究生。
| 豆瓣读者
真正讲大数据处理思路的书

最好的数据挖掘图书之一

回到图书

作者:Jure Leskovec,Anand Rajaraman,Jeffrey Ullman
译者:王斌 , 王达侃
| 图书特色
- 当今 AI 领域最知名的学者之一Jure Leskovec、2020 年图灵奖得主 Jeffrey Ullman 及弟子作品
- 国内知名 NLP 专家王斌、AI 青年学者王达侃执笔翻译
- “数据挖掘全景式入门参考书”,源自斯坦福大学公开课“CS246:海量数据挖掘”“CS224W:图机器学习”和“CS341:项目实战课”
- 配套资源丰富,包括开源英文原书 PDF、PPT、视频讲解
本书源自斯坦福大学公开课“CS246:海量数据挖掘”“CS224W:图机器学习”和“CS341:项目实战课”,主要关注极大规模数据的挖掘。书中包括分布式文件系统、相似性搜索、搜索引擎技术、频繁项集挖掘、聚类算法、广告管理及推荐系统、社会网络图挖掘和大规模机器学习等主要内容。第3版新增了决策树、神经网络和深度学习等内容。几乎每节都有对应的习题,以此来巩固所讲解的内容。读者还可以从网上获取相关拓展资料。

数据挖掘是数据时代的一项必杀技
这本书可以带你入门
—----—-—-—---— 送书 —----—---—-—---
内容简介
1、如正文所介绍的那样。本次赠书活动由图灵教育大力支持,一共送书图书3本,欢迎大家积极参与,具体活动规则见下方~
活动规则
参与方式:在下方公众号后台回复 “送书”关键字,记得是“送书”二字哈,即可参与本次的送书活动。
公布时间:2021年6月18号(周五)晚上20点
领取事宜:请小伙伴添加小助手微信: WebFighting,或者扫码添加好友。添加小助手的每一个人都可以领取一份Python学习资料,更重要的是方便联系。

注意事项:一定要留意微信消息,如果你是幸运儿就尽快在小程序中填写收货地址、书籍信息。一天之内没有填写收货信息,送书名额就转给其他人了噢,欢迎参与


























")
、requires_grad、eval()")






还没有评论,来说两句吧...