X2Paddle实践之——Tensorflow版本VGG模型转化为paddle版本模型
最近经常会刷到很多关于paddle的文章,说实在的paddle我之前读研的时候还是有用过的,后面就没怎么再用过了,经过几年的捶打完善,感觉现在已经是一款不错的深度学习框架了,是时候捡起来学习了解一下了。
PaddlePaddle地址在这里,首页截图如下所示:
上面图中的每一个项目都是当前很火的项目,不过我们今天的主要学习内容不在上面,之前也做过不同框架之间模型转化的工作,今天也是这样的内容,因为PaddlePaddle自家提供了类似的开源工具X2Paddle,顾名思义,就是提供其他框架转化为PaddlePaddle自家模型文件的工具。
话不多说,这里先来看X2Paddle,地址在这里,首页如下:
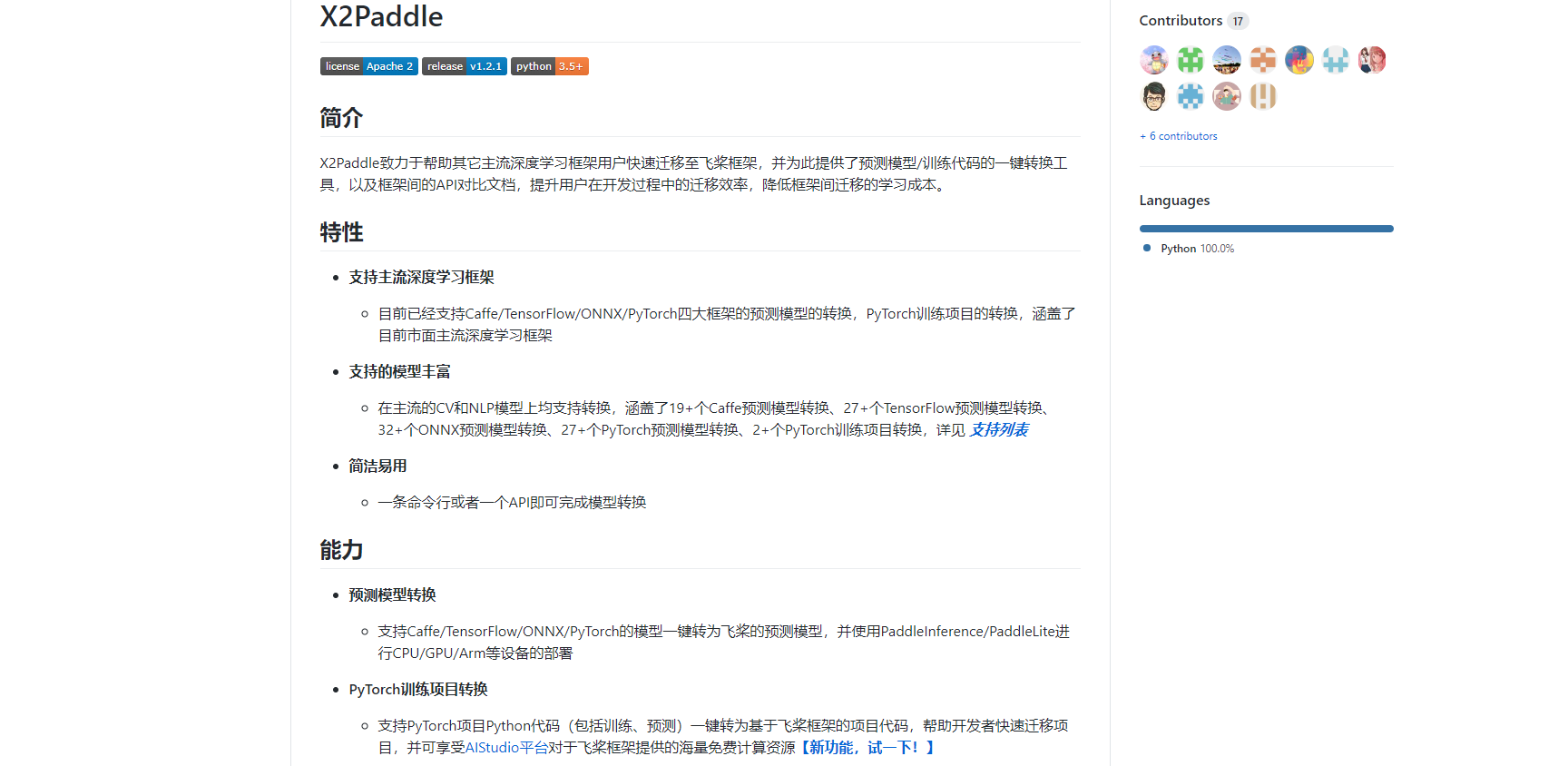
感兴趣的话可以去仔细了解一下,我们今天主要是借助具体的实践来学习一下具体的操作使用,VGG_16是CV领域的一个经典模型,这里就以VGG_16为例,给大家展示如何将TensorFlow训练好的模型转换为飞桨模型。
首先下载模型,地址如下:
http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz
之后解压缩,截图如下所示:

接下来我们需要重新加载参数,并将网络结构和参数一起保存为checkpoint模型,代码如下:
with tf.Session() as sess:inputs = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3], name="inputs")logits, endpoint = vgg.vgg_16(inputs, num_classes=1000, is_training=False)load_model = slim.assign_from_checkpoint_fn("vgg_16.ckpt", slim.get_model_variables("vgg_16"))load_model(sess)data = numpy.random.rand(5, 224, 224, 3)input_tensor = sess.graph.get_tensor_by_name("inputs:0")output_tensor = sess.graph.get_tensor_by_name("vgg_16/fc8/squeezed:0")result = sess.run([output_tensor], {input_tensor:data})numpy.save("tensorflow.npy", numpy.array(result))saver = tf.train.Saver()saver.save(sess, "checkpoint/model")
完成上述处理,我们就可以着手将模型转为PaddlePaddle模型了,代码如下:
parser = convert._get_parser()parser.meta_file = "checkpoint/model.meta"parser.ckpt_dir = "checkpoint"parser.in_nodes = ["inputs"]parser.input_shape = ["None,224,224,3"]parser.output_nodes = ["vgg_16/fc8/squeezed"]parser.use_cuda = "True"parser.input_format = "NHWC"parser.save_dir = "paddle_model"convert.run(parser)
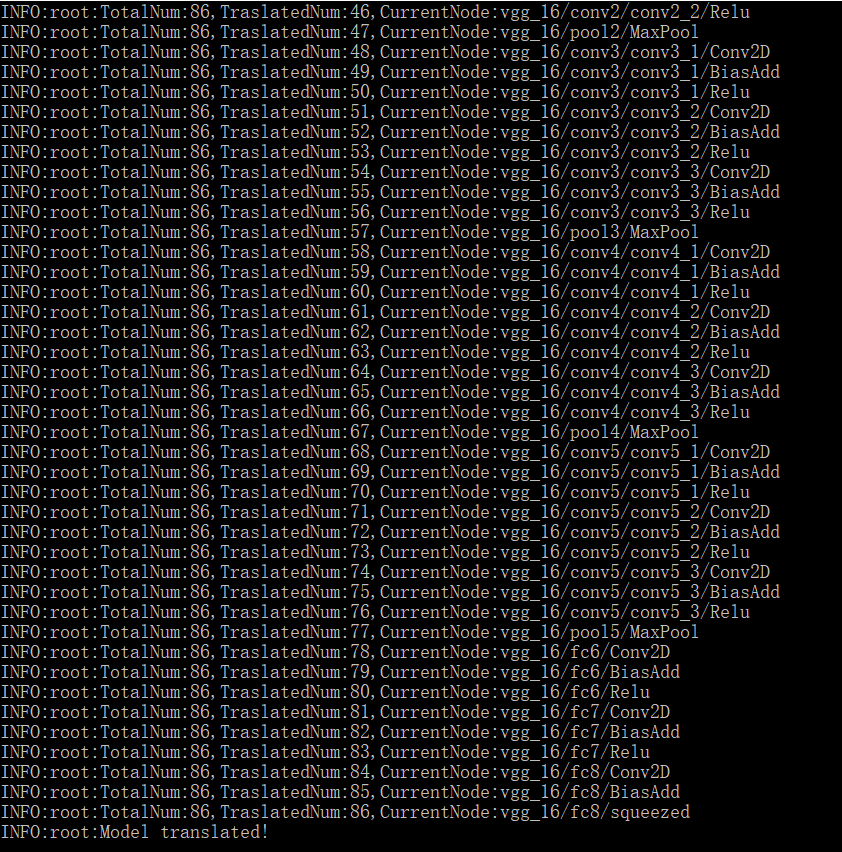
由于是初次学习使用,这里我附上完整的日志输出,如下:
Use tf.compat.v1.graph_util.extract_sub_graphINFO:root:Tensorflow model loaded!INFO:root:TotalNum:86,TraslatedNum:1,CurrentNode:inputsINFO:root:TotalNum:86,TraslatedNum:2,CurrentNode:vgg_16/conv1/conv1_1/weightsINFO:root:TotalNum:86,TraslatedNum:3,CurrentNode:vgg_16/conv1/conv1_1/biasesINFO:root:TotalNum:86,TraslatedNum:4,CurrentNode:vgg_16/conv1/conv1_2/weightsINFO:root:TotalNum:86,TraslatedNum:5,CurrentNode:vgg_16/conv1/conv1_2/biasesINFO:root:TotalNum:86,TraslatedNum:6,CurrentNode:vgg_16/conv2/conv2_1/weightsINFO:root:TotalNum:86,TraslatedNum:7,CurrentNode:vgg_16/conv2/conv2_1/biasesINFO:root:TotalNum:86,TraslatedNum:8,CurrentNode:vgg_16/conv2/conv2_2/weightsINFO:root:TotalNum:86,TraslatedNum:9,CurrentNode:vgg_16/conv2/conv2_2/biasesINFO:root:TotalNum:86,TraslatedNum:10,CurrentNode:vgg_16/conv3/conv3_1/weightsINFO:root:TotalNum:86,TraslatedNum:11,CurrentNode:vgg_16/conv3/conv3_1/biasesINFO:root:TotalNum:86,TraslatedNum:12,CurrentNode:vgg_16/conv3/conv3_2/weightsINFO:root:TotalNum:86,TraslatedNum:13,CurrentNode:vgg_16/conv3/conv3_2/biasesINFO:root:TotalNum:86,TraslatedNum:14,CurrentNode:vgg_16/conv3/conv3_3/weightsINFO:root:TotalNum:86,TraslatedNum:15,CurrentNode:vgg_16/conv3/conv3_3/biasesINFO:root:TotalNum:86,TraslatedNum:16,CurrentNode:vgg_16/conv4/conv4_1/weightsINFO:root:TotalNum:86,TraslatedNum:17,CurrentNode:vgg_16/conv4/conv4_1/biasesINFO:root:TotalNum:86,TraslatedNum:18,CurrentNode:vgg_16/conv4/conv4_2/weightsINFO:root:TotalNum:86,TraslatedNum:19,CurrentNode:vgg_16/conv4/conv4_2/biasesINFO:root:TotalNum:86,TraslatedNum:20,CurrentNode:vgg_16/conv4/conv4_3/weightsINFO:root:TotalNum:86,TraslatedNum:21,CurrentNode:vgg_16/conv4/conv4_3/biasesINFO:root:TotalNum:86,TraslatedNum:22,CurrentNode:vgg_16/conv5/conv5_1/weightsINFO:root:TotalNum:86,TraslatedNum:23,CurrentNode:vgg_16/conv5/conv5_1/biasesINFO:root:TotalNum:86,TraslatedNum:24,CurrentNode:vgg_16/conv5/conv5_2/weightsINFO:root:TotalNum:86,TraslatedNum:25,CurrentNode:vgg_16/conv5/conv5_2/biasesINFO:root:TotalNum:86,TraslatedNum:26,CurrentNode:vgg_16/conv5/conv5_3/weightsINFO:root:TotalNum:86,TraslatedNum:27,CurrentNode:vgg_16/conv5/conv5_3/biasesINFO:root:TotalNum:86,TraslatedNum:28,CurrentNode:vgg_16/fc6/weightsINFO:root:TotalNum:86,TraslatedNum:29,CurrentNode:vgg_16/fc6/biasesINFO:root:TotalNum:86,TraslatedNum:30,CurrentNode:vgg_16/fc7/weightsINFO:root:TotalNum:86,TraslatedNum:31,CurrentNode:vgg_16/fc7/biasesINFO:root:TotalNum:86,TraslatedNum:32,CurrentNode:vgg_16/fc8/weightsINFO:root:TotalNum:86,TraslatedNum:33,CurrentNode:vgg_16/fc8/biasesINFO:root:TotalNum:86,TraslatedNum:34,CurrentNode:vgg_16/conv1/conv1_1/Conv2DINFO:root:TotalNum:86,TraslatedNum:35,CurrentNode:vgg_16/conv1/conv1_1/BiasAddINFO:root:TotalNum:86,TraslatedNum:36,CurrentNode:vgg_16/conv1/conv1_1/ReluINFO:root:TotalNum:86,TraslatedNum:37,CurrentNode:vgg_16/conv1/conv1_2/Conv2DINFO:root:TotalNum:86,TraslatedNum:38,CurrentNode:vgg_16/conv1/conv1_2/BiasAddINFO:root:TotalNum:86,TraslatedNum:39,CurrentNode:vgg_16/conv1/conv1_2/ReluINFO:root:TotalNum:86,TraslatedNum:40,CurrentNode:vgg_16/pool1/MaxPoolINFO:root:TotalNum:86,TraslatedNum:41,CurrentNode:vgg_16/conv2/conv2_1/Conv2DINFO:root:TotalNum:86,TraslatedNum:42,CurrentNode:vgg_16/conv2/conv2_1/BiasAddINFO:root:TotalNum:86,TraslatedNum:43,CurrentNode:vgg_16/conv2/conv2_1/ReluINFO:root:TotalNum:86,TraslatedNum:44,CurrentNode:vgg_16/conv2/conv2_2/Conv2DINFO:root:TotalNum:86,TraslatedNum:45,CurrentNode:vgg_16/conv2/conv2_2/BiasAddINFO:root:TotalNum:86,TraslatedNum:46,CurrentNode:vgg_16/conv2/conv2_2/ReluINFO:root:TotalNum:86,TraslatedNum:47,CurrentNode:vgg_16/pool2/MaxPoolINFO:root:TotalNum:86,TraslatedNum:48,CurrentNode:vgg_16/conv3/conv3_1/Conv2DINFO:root:TotalNum:86,TraslatedNum:49,CurrentNode:vgg_16/conv3/conv3_1/BiasAddINFO:root:TotalNum:86,TraslatedNum:50,CurrentNode:vgg_16/conv3/conv3_1/ReluINFO:root:TotalNum:86,TraslatedNum:51,CurrentNode:vgg_16/conv3/conv3_2/Conv2DINFO:root:TotalNum:86,TraslatedNum:52,CurrentNode:vgg_16/conv3/conv3_2/BiasAddINFO:root:TotalNum:86,TraslatedNum:53,CurrentNode:vgg_16/conv3/conv3_2/ReluINFO:root:TotalNum:86,TraslatedNum:54,CurrentNode:vgg_16/conv3/conv3_3/Conv2DINFO:root:TotalNum:86,TraslatedNum:55,CurrentNode:vgg_16/conv3/conv3_3/BiasAddINFO:root:TotalNum:86,TraslatedNum:56,CurrentNode:vgg_16/conv3/conv3_3/ReluINFO:root:TotalNum:86,TraslatedNum:57,CurrentNode:vgg_16/pool3/MaxPoolINFO:root:TotalNum:86,TraslatedNum:58,CurrentNode:vgg_16/conv4/conv4_1/Conv2DINFO:root:TotalNum:86,TraslatedNum:59,CurrentNode:vgg_16/conv4/conv4_1/BiasAddINFO:root:TotalNum:86,TraslatedNum:60,CurrentNode:vgg_16/conv4/conv4_1/ReluINFO:root:TotalNum:86,TraslatedNum:61,CurrentNode:vgg_16/conv4/conv4_2/Conv2DINFO:root:TotalNum:86,TraslatedNum:62,CurrentNode:vgg_16/conv4/conv4_2/BiasAddINFO:root:TotalNum:86,TraslatedNum:63,CurrentNode:vgg_16/conv4/conv4_2/ReluINFO:root:TotalNum:86,TraslatedNum:64,CurrentNode:vgg_16/conv4/conv4_3/Conv2DINFO:root:TotalNum:86,TraslatedNum:65,CurrentNode:vgg_16/conv4/conv4_3/BiasAddINFO:root:TotalNum:86,TraslatedNum:66,CurrentNode:vgg_16/conv4/conv4_3/ReluINFO:root:TotalNum:86,TraslatedNum:67,CurrentNode:vgg_16/pool4/MaxPoolINFO:root:TotalNum:86,TraslatedNum:68,CurrentNode:vgg_16/conv5/conv5_1/Conv2DINFO:root:TotalNum:86,TraslatedNum:69,CurrentNode:vgg_16/conv5/conv5_1/BiasAddINFO:root:TotalNum:86,TraslatedNum:70,CurrentNode:vgg_16/conv5/conv5_1/ReluINFO:root:TotalNum:86,TraslatedNum:71,CurrentNode:vgg_16/conv5/conv5_2/Conv2DINFO:root:TotalNum:86,TraslatedNum:72,CurrentNode:vgg_16/conv5/conv5_2/BiasAddINFO:root:TotalNum:86,TraslatedNum:73,CurrentNode:vgg_16/conv5/conv5_2/ReluINFO:root:TotalNum:86,TraslatedNum:74,CurrentNode:vgg_16/conv5/conv5_3/Conv2DINFO:root:TotalNum:86,TraslatedNum:75,CurrentNode:vgg_16/conv5/conv5_3/BiasAddINFO:root:TotalNum:86,TraslatedNum:76,CurrentNode:vgg_16/conv5/conv5_3/ReluINFO:root:TotalNum:86,TraslatedNum:77,CurrentNode:vgg_16/pool5/MaxPoolINFO:root:TotalNum:86,TraslatedNum:78,CurrentNode:vgg_16/fc6/Conv2DINFO:root:TotalNum:86,TraslatedNum:79,CurrentNode:vgg_16/fc6/BiasAddINFO:root:TotalNum:86,TraslatedNum:80,CurrentNode:vgg_16/fc6/ReluINFO:root:TotalNum:86,TraslatedNum:81,CurrentNode:vgg_16/fc7/Conv2DINFO:root:TotalNum:86,TraslatedNum:82,CurrentNode:vgg_16/fc7/BiasAddINFO:root:TotalNum:86,TraslatedNum:83,CurrentNode:vgg_16/fc7/ReluINFO:root:TotalNum:86,TraslatedNum:84,CurrentNode:vgg_16/fc8/Conv2DINFO:root:TotalNum:86,TraslatedNum:85,CurrentNode:vgg_16/fc8/BiasAddINFO:root:TotalNum:86,TraslatedNum:86,CurrentNode:vgg_16/fc8/squeezedINFO:root:Model translated!
执行成功截图如下所示:
转化成功后会出现 paddle_model 目录,如下:

截图如下所示:
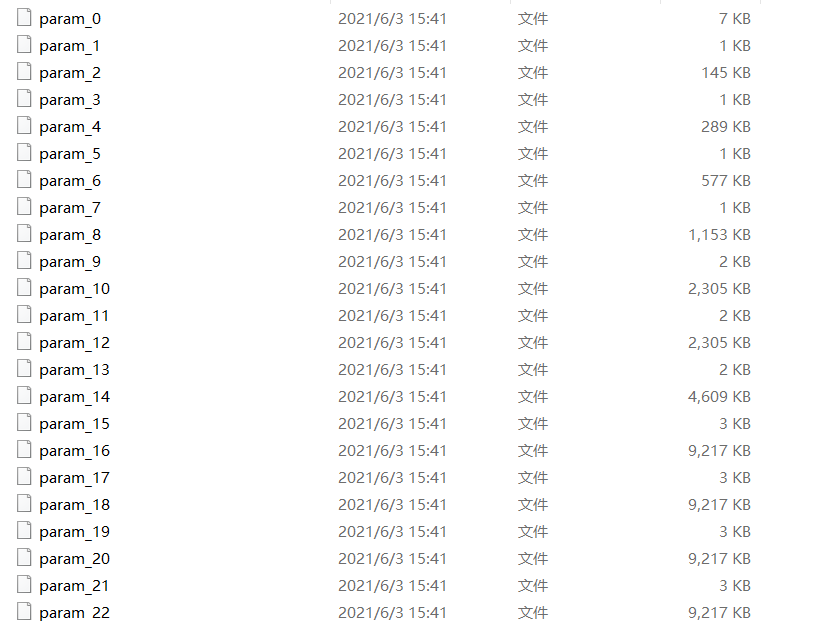
转化的工作到这里其实就已经结束了,但是一般的转化都逃不开精度损失的问题,这里需要做一下验证计算。代码如下:
model = ml.ModelLoader("paddle_model", use_cuda=False)numpy.random.seed(13)data = numpy.random.rand(5, 224, 224, 3).astype("float32")# NHWC -> NCHWdata = numpy.transpose(data, (0, 3, 1, 2))results = model.inference(feed_dict={model.inputs[0]:data})numpy.save("paddle.npy", numpy.array(results))
执行的时候报错了,错误信息如下:
AssertionError: In PaddlePaddle 2.x, we turn on dynamic graph mode by default, and 'data()' is only supported in static graph mode. So if you want to use this api, please call 'paddle.enable_static()' before this api to enter static graph mode.
代码更正为下面的,其实主要就是静态图的问题。
paddle.enable_static()model = ml.ModelLoader("paddle_model", use_cuda=False)numpy.random.seed(13)data = numpy.random.rand(5, 224, 224, 3).astype("float32")# NHWC -> NCHWdata = numpy.transpose(data, (0, 3, 1, 2))results = model.inference(feed_dict={model.inputs[0]:data})numpy.save("paddle.npy", numpy.array(results))
之后计算一下模型的损失,通过把两个模型文件加载进来后,通过numpy.fabs来求两个模型结果的差异即可,如下:
paddle_result = numpy.load("paddle.npy")tensorflow_result = numpy.load("tensorflow.npy")diff = numpy.fabs(paddle_result - tensorflow_result)print(numpy.max(diff))
结果如下所示:
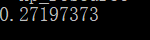
误差的数据还是比较小的,在可接受的范围内。
最后附上完整代码,如下:
#!usr/bin/env python#encoding:utf-8from __future__ import division'''__Author__:沂水寒城功能: VGG Tensorflow 转 Paddle 实战'''import osimport tensorflow.contrib.slim as slimfrom tensorflow.contrib.slim.nets import vggimport tensorflow as tfimport numpy'''保存模型为checkpoint格式'''with tf.Session() as sess:inputs = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3], name="inputs")logits, endpoint = vgg.vgg_16(inputs, num_classes=1000, is_training=False)load_model = slim.assign_from_checkpoint_fn("vgg_16.ckpt", slim.get_model_variables("vgg_16"))load_model(sess)data = numpy.random.rand(5, 224, 224, 3)input_tensor = sess.graph.get_tensor_by_name("inputs:0")output_tensor = sess.graph.get_tensor_by_name("vgg_16/fc8/squeezed:0")result = sess.run([output_tensor], {input_tensor:data})numpy.save("tensorflow.npy", numpy.array(result))saver = tf.train.Saver()saver.save(sess, "checkpoint/model")'''将模型转换为飞桨模型'''import tf2fluid.convert as convertimport argparseparser = convert._get_parser()parser.meta_file = "checkpoint/model.meta"parser.ckpt_dir = "checkpoint"parser.in_nodes = ["inputs"]parser.input_shape = ["None,224,224,3"]parser.output_nodes = ["vgg_16/fc8/squeezed"]parser.use_cuda = "True"parser.input_format = "NHWC"parser.save_dir = "paddle_model"convert.run(parser)'''预测结果差异对比'''import numpyimport paddleimport tf2fluid.model_loader as mlpaddle.enable_static()model = ml.ModelLoader("paddle_model", use_cuda=False)numpy.random.seed(13)data = numpy.random.rand(5, 224, 224, 3).astype("float32")# NHWC -> NCHWdata = numpy.transpose(data, (0, 3, 1, 2))results = model.inference(feed_dict={model.inputs[0]:data})numpy.save("paddle.npy", numpy.array(results))'''对比模型损失'''import numpypaddle_result = numpy.load("paddle.npy")tensorflow_result = numpy.load("tensorflow.npy")diff = numpy.fabs(paddle_result - tensorflow_result)print(numpy.max(diff))
初次的实践使用就到这里了,后面有时间继续深入研究下。

























")








还没有评论,来说两句吧...