哈希表(哈希函数的设计与哈希冲突的解决)
文章目录
- 一、什么是哈希表
- 二、哈希函数
- 三、哈希冲突的原因与解决方法
- 1、数组扩容
- 2、一个优秀的哈希函数
- 3、开放寻址法
- 4、链表法
- 四、总结
一、什么是哈希表
哈希表就是数组+哈希函数,其核心思想是利用数组可以按照下标索引随机访问数据的特性。
举个栗子:一个班级有50个人,每个人都有学号,按自然数顺序编号,学号1是小明,学号2是小红,学号3是小强,以此类推。在这个栗子中一个班级就是一个数组容器,学号就是数组的下标,学生就是数组中的元素,通过学号找人就是利用数组下标随机访问元素的特性。而如何给学生编号就是哈希函数的事情了。

二、哈希函数
哈希函数,顾名思义,是一个函数,表达式:hash(key),key就是与数组下标不相干的关键词,而哈希函数计算的值就是与数组下标建立联系,可以直接作为数组下标,也可以将哈希值做取模等运算得到数组下标。
刚才学号的栗子就是hash(自然数)=自然数,计算得到的哈希值可以直接用作数组下标,而深入到哈希表的实际应用,往往计算出的哈希值会很大,将其直接作为数组下标的话会使数组的长度很长,浪费内存。所以在有限的数组中通过哈希函数映射下标,势必会造成哈希冲突。
三、哈希冲突的原因与解决方法
产生哈希冲突的原因不仅仅是因为数组的有界,还包括哈希函数的计算以及对哈希值的映射都会产生哈希冲突。
解决哈希冲突的方式也是根据这三个原因对症下药:
- 数组有界就适当扩容。
- 设计优秀的哈希算法。
- 开放寻址法和链表法为哈希值找到合适的映射。
1、数组扩容
数组中空闲的位置越多,一定程度上哈希冲突也会越小。但是不能因为这个原因就把数组的长度设置的很长,而是设置一个合理的初始长度,后面再慢慢扩容。
什么时候扩容?扩容多少?都是有考究的。扩容太少导致频繁扩容影响性能,扩容太多浪费内存。一般经验所得,当元素个数占数组长度的3/4时扩容,扩容后的长度是原来的两倍。这也是java中HashMap的扩容思想,但是还是需要根据实际情况做调整。
什么时候扩容有一个名词,装载因子,代表元素个数占数组长度的比例:装载因子=元素个数/数组长度。装载因子的设置要权衡时间和空间复杂度,装载因子太大,哈希冲突越严重,装载因子太小,内存浪费严重。
如果内存空间不紧张,对执行效率要求很高,可以降低装载因子的阈值;相反,如果内存空间紧张,对执行效率要求又不高,可以增加装载因子的大小,甚至可以大于 1(对于链表法冲突解决)。
对于单纯的数组扩容,数据的迁移很简单,对应位置复制过去即可,但是哈希表的扩容迁移就比较复杂,哈希表的长度变了,元素的位置也变了,需要一个个重新计算哈希映射新位置。扩容的时间复杂度是O(n),简单的插入一个数据的时间复杂度是O(1),如果刚好碰上扩容,时间复杂度就是O(n)。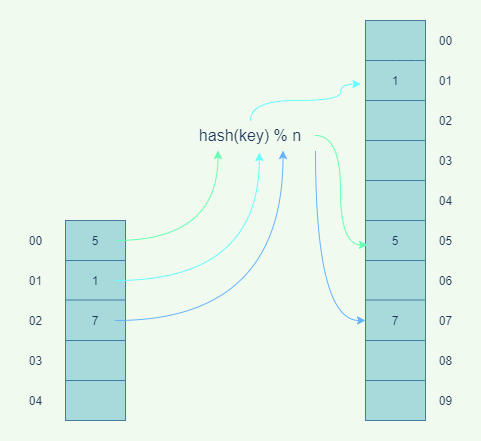
扩容在一定程度上影响插入数据的性能,所以要避免无效的扩容,除了设计合理的装载因子和扩容比例,还可以从扩容的过程中优化:
(1)扩容动作摊分到每个插入操作中,新数据插入新数组中,插入数据的同时复制一个旧数组中的一个元素到新数组,这样每次插入操作的时间复杂度都是O(1),但是需要兼容维护新旧数组,查找和删除操作先到旧数组查找,没有再到新数组查找。(jdk1.8 ConcurrentHashMap多线程扩容思想)
(2)对于链表法解决冲突构成的哈希表,迁移时可以链表为单位复制,无需所有元素重新计算哈希值。(ConcurrentHashMap扩容以链表为单位整体迁移复制)
2、一个优秀的哈希函数
一个不合理的哈希函数,会使得数组扩容功亏一篑。若计算的哈希值本身很容易冲突,或者映射到数组下标不均匀分布,再多的空闲位置也没用。这就要求一个优秀的哈希函数必须具有以下2个要素:
- 哈希值尽量随机且均匀分布,这样不仅可以最小化哈希冲突,而且即使出现了冲突,也会平均在各个位置,有利于冲突的解决改善(开放寻址法和链表法)。
- 哈希算法的计算性能要高,不能影响哈希表的正常操作。
数组扩容和优秀的哈希函数仍然无法避免哈希冲突,还可以从哈希值映射上下手,常用的方法有开放寻址法和链表法。
3、开放寻址法
开放寻址法,就是当发生哈希冲突时,重新找到空闲的位置,然后插入元素。寻址方式有多种,常用的有线性寻址、二次方寻址、双重哈希寻址:
- 线性寻址,当需要插入元素的位置被占用时,顺序向后寻址,如果到数组最后也没找到一个空闲位置,则从数组开头寻址,直到找到一个空闲位置插入数据。线性寻址的每次寻址步长是1,寻址公式
hash(key)+n(n是寻址的次数)。 - 二次方寻址,就是线性寻址的总步长的二次方,即
hash(key)+n^2。 - 双重哈希寻址,顾名思义就是多次哈希直到找到一个不冲突的哈希值。
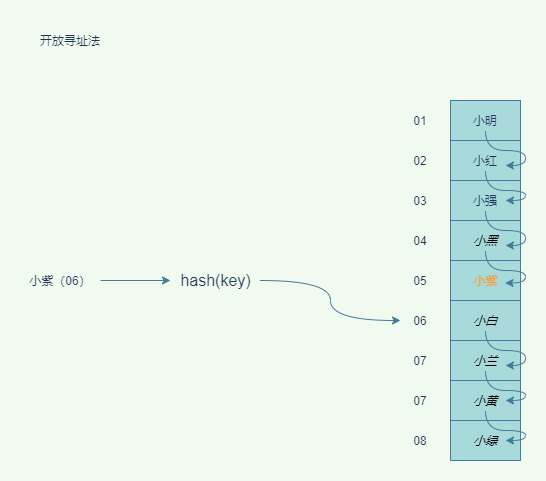
采用开放寻址法解决哈希冲突,又该如何查找元素和删除元素呢?
查找元素的过程和插入元素类似,用相同的寻址方式,寻址的同时比对key或者value是否相等,相等则认为元素存在,不相等则继续寻址,如果探测到空闲位置依然没有找到则认为该元素不存在。
删除有些特别,不能单纯的把要删除的元素设置为空,因为在查找元素的过程中探测到的空闲位置是删除元素的位置,就会使得查找元素的寻址算法失效,本来存在的元素误判定为不存在。该如何解决这个问题呢?
只需要删除元素不是物理删除而是逻辑删除。给删除的元素做上delete标记,当查询元素寻址时遇到delete标记的位置时不会停下来而是继续向后探测,但是在插入元素寻址遇到delete标记的位置就会把应该删除的元素替换掉。
三种寻址方式都有着明显的不足:
- 线性寻址,寻址的性能虽然元素个数的增多逐步下降,最坏时间复杂度是O(n)。
- 二次方寻址,寻址的次数比线性寻址较低了,但是会因为步长是二次方,所以需要较长的数组长度,内存利用率可能较低。
- 双重哈希寻址,多次哈希可能会浪费时间,需要优质的哈希函数做支撑。
而整个开放寻址法的不足也很明显:
- 插入、查找、删除都需要寻址。
- 数组中元素越多,空闲位置越少,哈希冲突越剧烈。所以装载因子不能太大,要及时扩容减小冲突,但是数组内存利用率较低。
看似开放寻址法有挺多问题,但是也有一些优点:
- 数据都存储在数组中,可以有效地利用 CPU 缓存加快查询速度。
- 而且,这种方法实现的哈希表,序列化也简单,不像链表还要考虑指针。
总结而得,当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中ThreadLocal内部类ThreadLocalMap使用开放寻址法解决散列冲突的原因。
4、链表法
链表法相对于开放寻址法实现起来简单一些,在数组内存利用率上比开放寻址法高,同时对装载因子的忍耐度也相对较高。开放寻址法的装载因子只能小于1,越趋近于1,冲突越剧烈,寻址过程越耗时,而链表法的装载因子可以大于1(但是内存不紧张,在意性能的一般不会装载因子不会大于1)。
链表法就是将产生哈希冲突的元素链接成一个链表,每个链表可以设想成一个桶(bucket)或者槽(slot):
- 插入元素就是通过哈希找到对应的桶,然后插入到链表中,时间复杂度为O(1);
- 查找元素也是通过哈希找到对应的桶,然后遍历链表;
- 删除元素同样通过哈希找到对应的桶,遍历链表找到需要删除的元素删除。
当哈希比较均匀时,理论上查询和删除的时间复杂度为O(n/m),n是数组中元素的个数,m是数组中桶的个数。但是当哈希冲突非常严重时,数据都集中在一个桶里,数组退化成链表,查找和删除的时间复杂度为趋近与O(n)。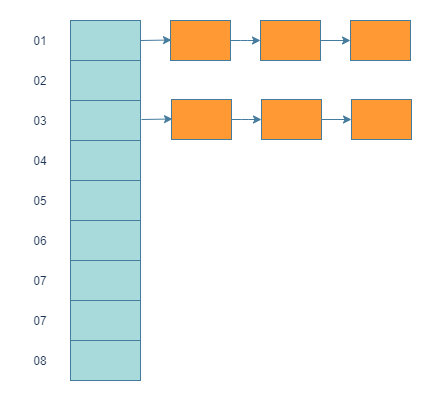
针对数组退化成链表或者链表过长导致的性能下降,可以在合适的时机将链表转换为红黑树,极端情况下数组退化成一个红黑树,时间复杂度也是O(logn),比O(n)强多了。(jdk8中ConcurrentHashMap对于jdk7有所优化,当链表节点的个数大于8个且数组的长度大于64时,链表转换为红黑树;当红黑树的节点小于8个时又退化为链表。)
可以容忍的缺点:
- 因为链表节点需要存放指针,所以内存占用上比开放寻址法高。
- 链表中的节点在内存中是不连续分布的,所以对CPU缓存的利用率也不高,序列化也比开放寻址法复杂。
优点:
- 内存利用率较高。
- 优化策略灵活,红黑树和链表可以互相转换。
四、总结
哈希表的两个核心哈希函数的设计与哈希冲突的解决。
- 哈希表就是数组+哈希函数,其核心思想是利用数组可以按照下标索引随机访问数据的特性。
- 哈希冲突的原因:数组的有界,哈希函数的计算,哈希值的映射。
- 解决哈希冲突的方法:数组扩容,设计优秀的哈希函数,开放寻址法和链表法为哈希值找到合适的映射。
- 开放寻址法,插入、查找、删除都需要相同的寻址逻辑,所以时间复杂度一样。数组中元素越多,空闲位置越少,哈希冲突越剧烈。
- 链表法需要注意,当哈希冲突非常严重时,数组会退化成链表,查找和删除的时间复杂度趋近于O(n),可以采用红黑树进行优化。
参考:极客时间专栏《数据结构与算法之美》。
PS: 如若文章中有错误理解,欢迎批评指正,同时非常期待你的评论、点赞和收藏。我是徐同学,愿与你共同进步!




























异步(ajax)返回json格式数据")

")



还没有评论,来说两句吧...