[官方Flink入门笔记 ] 九、Flink SQL 编程实践
一 .简介
1.1. Flink SQL是什么

1.2. Window Aggregation
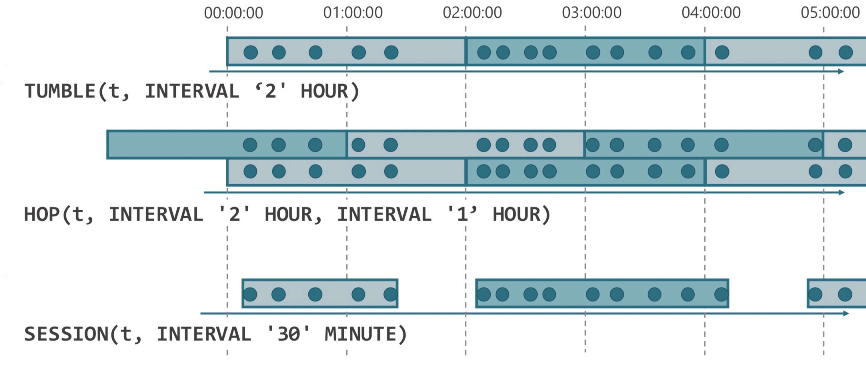
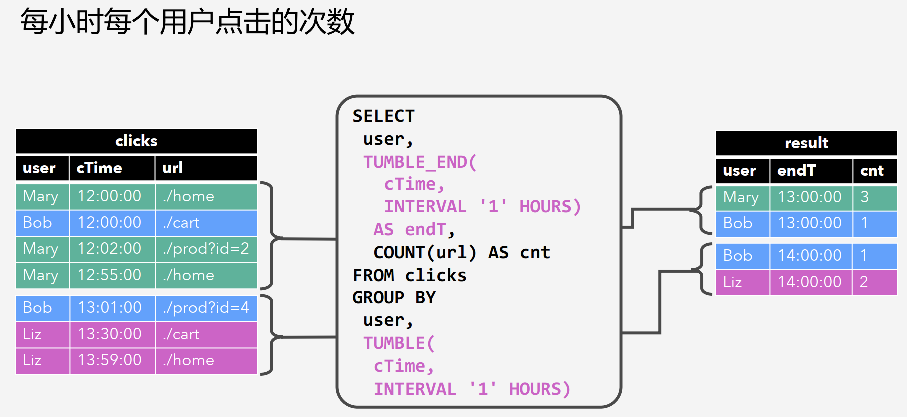
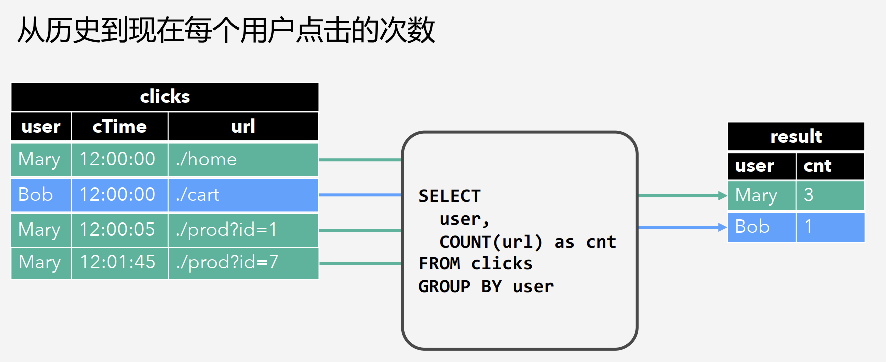
1.3. Group Aggregation

二 .实例
所需的案例参考: https://github.com/ververica/sql-training
2.1. 数据介绍
数据是 Rides 表,这是一张出租车的行车记录数据流,包含了时间和位置信息,运行 DESCRIBE Rides; 可以查看表结构。
Flink SQL> DESCRIBE Rides;root|-- rideId: Long // 行为ID (包含两条记录,一条入一条出)|-- taxiId: Long // 出租车ID|-- isStart: Boolean // 开始 or 结束|-- lon: Float // 经度|-- lat: Float // 纬度|-- rideTime: TimeIndicatorTypeInfo(rowtime) // 时间|-- psgCnt: Integer // 乘客数
2.2. 实例1:过滤
例如我们现在只想查看发生在纽约的行车记录。
注:Docker 环境中已经预定义了一些内置函数,如 isInNYC(lon, lat) 可以确定一个经纬度是否在纽约,toAreaId(lon, lat) 可以将经纬度转换成区块。
因此,此处我们可以使用 isInNYC 来快速过滤出纽约的行车记录。在 SQL CLI 中运行如下 Query:
SELECT * FROM Rides WHERE isInNYC(lon, lat);
SQL CLI 便会提交一个 SQL 任务到 Docker 集群中,从数据源(Rides 流存储在Kafka中)不断拉取数据,并通过 isInNYC 过滤出所需的数据。SQL CLI 也会进入可视化模式,并不断刷新展示过滤后的结果:
2.3. 实例2:Group Aggregate
我们的另一个需求是计算搭载每种乘客数量的行车事件数。也就是搭载1个乘客的行车数、搭载2个乘客的行车… 当然,我们仍然只关心纽约的行车事件。
因此,我们可以按照乘客数psgCnt做分组,使用 COUNT(*) 计算出每个分组的事件数,注意在分组前需要先过滤出isInNYC的数据。在 SQL CLI 中运行如下 Query:
SELECT psgCnt, COUNT(*) AS cntFROM RidesWHERE isInNYC(lon, lat)GROUP BY psgCnt;
2.4. 实例3:Window Aggregate
为了持续地监测纽约的交通流量,需要计算出每个区块每5分钟的进入的车辆数。我们只关心至少有5辆车子进入的区块。
此处需要涉及到窗口计算(每5分钟),所以需要用到 Tumbling Window 的语法。“每个区块” 所以还要按照 toAreaId 进行分组计算。“进入的车辆数” 所以在分组前需要根据 isStart字段过滤出进入的行车记录,并使用 COUNT(*) 统计车辆数。最后还有一个 “至少有5辆车子的区块” 的条件,这是一个基于统计值的过滤条件,所以可以用 SQL HAVING 子句来完成。
最后的 Query 如下所示:
SELECTtoAreaId(lon, lat) AS area,TUMBLE_END(rideTime, INTERVAL '5' MINUTE) AS window_end,COUNT(*) AS cntFROM RidesWHERE isInNYC(lon, lat) and isStartGROUP BYtoAreaId(lon, lat),TUMBLE(rideTime, INTERVAL '5' MINUTE)HAVING COUNT(*) >= 5;
在 SQL CLI 中运行后,每个 area + window_end 的结果输出后就不会再发生变化,但是会每隔 5 分钟会输出一批新窗口的结果。因为 Docker 环境中的source我们做了10倍的加速读取(相对于原始速度),所以演示的时候,大概每隔30秒就会输出一批新窗口。
2.5. Window Aggregate 与 Group Aggregate 的区别
Window Aggregate 是当window结束时才输出,其输出的结果是最终值,不会再进行修改,其输出流是一个 Append 流。而 Group Aggregate 是每处理一条数据,就输出最新的结果,其结果是在不断更新的,就好像数据库中的数据一样,其输出流是一个 Update 流。
另外一个区别是,window 由于有 watermark ,可以精确知道哪些窗口已经过期了,所以可以及时清理过期状态,保证状态维持在稳定的大小。而 Group Aggregate 因为不知道哪些数据是过期的,所以状态会无限增长,这对于生产作业来说不是很稳定,所以建议对 Group Aggregate 的作业配上 State TTL 的配置。

例如统计每个店铺每天的实时PV,那么就可以将 TTL 配置成 24+ 小时,因为一天前的状态一般来说就用不到了。
SELECT DATE_FORMAT(ts, 'yyyy-MM-dd'), shop_id, COUNT(*) as pvFROM TGROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd'), shop_id
当然,如果 TTL 配置地太小,可能会清除掉一些有用的状态和数据,从而导致数据精确性地问题。这也是用户需要权衡地一个参数。
2.6. 将 Append 流写入 Kafka
在 Flink 中,目前 Update 流只能写入支持更新的外部存储,如 MySQL, HBase, ElasticSearch。Append 流可以写入任意地存储,不过一般写入日志类型的系统,如 Kafka。
预定义了一张 Kafka 的结果表 Sink_TenMinPsgCnts
每10分钟的搭乘的乘客数可以使用 Tumbling Window 来描述,我们使用 INSERT INTO Sink_TenMinPsgCnts 来直接将 Query 结果写入到结果表。
INSERT INTO Sink_TenMinPsgCntsSELECTTUMBLE_START(rideTime, INTERVAL '10' MINUTE) AS cntStart,TUMBLE_END(rideTime, INTERVAL '10' MINUTE) AS cntEnd,CAST(SUM(psgCnt) AS BIGINT) AS cntFROM RidesGROUP BY TUMBLE(rideTime, INTERVAL '10' MINUTE);
2.7. 将 Update 流写入 ElasticSearch
将一个持续更新的 Update 流写入 ElasticSearch 中。我们希望将“每个区域出发的行车数”,写入到 ES 中。
预定义好了一张 Sink_AreaCnts 的 ElasticSearch 结果表。该表中只有两个字段 areaId 和 cnt。
同样的,我们也使用 INSERT INTO 将 Query 结果直接写入到 Sink_AreaCnts 表中。
INSERT INTO Sink_AreaCntsSELECT toAreaId(lon, lat) AS areaId, COUNT(*) AS cntFROM RidesWHERE isStartGROUP BY toAreaId(lon, lat);在 SQL CLI 中执行上述 Query 后,Elasticsearch 会自动地创建 area-cnts 索引。Elasticsearch 提供了一个 REST API 。我们可以访问查看area-cnts索引的详细信息: http://localhost:9200/area-cnts查看area-cnts索引的统计信息: http://localhost:9200/area-cnts/_stats返回area-cnts索引的内容:http://localhost:9200/area-cnts/_search显示 区块 49791 的行车数:http://localhost:9200/area-cnts/_search?q=areaId:49791随着 Query 的一直运行,你也可以观察到一些统计值(_all.primaries.docs.count, _all.primaries.docs.deleted)在不断的增长:http://localhost:9200/area-cnts/_stats



























")


")


还没有评论,来说两句吧...