parquet列式存储格式
一、历史背景
Parquet是Hadoop生态圈中主流的列式存储格式,它使用 Google 的 Dremel 论文中概述的技术,列式存储嵌套的数据结构(传说中3秒查询1PB的数据)。最早是由Twitter和Cloudera合作开发,当时Twitter的日增压缩的数据量达到100TB+,存储在HDFS上,他们会使用多种计算框架(例如MapReduce、Hive、Pig等)对这些数据做分析和挖掘;日志结构是复杂的嵌套数据类型,例如一个典型的日志schema有87列,嵌套了7层。所以需要设计一种列式存储格式,既能支持关系型数据,又能支持复杂的嵌套类型的数据,同时能够适配多种数据处理框架。于是Parquet第一个版本- Apache Parquet 1.0 – 在 2013 年 7 月发布。直到2015年5月开始从Apache孵化器里毕业成为Apache顶级项目。
有这样一句话流传:如果说HDFS是大数据时代文件系统的事实标准、Parquet就是大数据时代存储格式的标准。
二、简单介绍
先简单介绍下:
Parquet是一种支持嵌套结构的列式存储格式
非常适用于OLAP场景,实现按列存储和扫描
诸如Parquet这种列式存储,特点或优势主要体现在以下2个方面:
1、更高的压缩比
列存使得更容易对每个列使用高效的压缩和编码,降低磁盘空间。
2、更小的io操作
使用映射下推和谓词下推,只读取需要的列,跳过不满足条件的列,能够减少不必要的数据扫描,带来性能提升,并在表字段比较多的时候更加明显。
关于映射下推和谓词下推:
映射下推,这是列存最突出的优势,它是指在获取数据时只需要扫描需要的列,不用全部扫描。比如sql中的按列查询。
谓词下推,是指将一些过滤条件尽可能的在最底层执行以减少结果集。谓词就是指这些过滤条件,即返回boolean:true和false的表达式,比如sql中的大于、小于、等于、Like、is null等。
三、Parquet项目概述
Parquet是与语言无关,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet适配的组件:
查询引擎:包括Hive、Presto、Impala、Pig、Drill、Tajo、HAWQ、IBM Big SQL等,
计算框架:包括MapReduce,Spark,CassCading、Crunch、Scalding、Kite等,
数据模型:包括Avro、Thrift、Protocol Buffer,POJOs等。
Parquet项目主要分为三个部分:parquet-mr、parquet-format、parquet-cpp
项目组成及自下而上交互的方式如下图所示:
这里的话可以分为三层:
数据存储层:定义Parquet文件格式,其中元数据在parquet-format项目中定义,包括Parquet原始类型定义、Page类型、编码类型、压缩类型等等;
对象转换层:这一层在parquet-mr项目中,包含多个模块,作用是完成其他对象模型与Parquet内部数据模型的映射和转换,parquet的编码方式使用的是triping and assembly 算法。
对象模型层:定义如何读取parquet文件的内容,这一层转换包括Avro、Thrift、Protocal Buffer 等对象模型/序列化格式、Hive serde 等的适配。并且为了帮助大家理解和使用,Parquet 提供了org.apache.parquet.example 包实现了 java 对象和 Parquet 文件的转换。
其中,对象模型可以简单理解为内存中的数据表示,Avro, Thrift, Protocol Buffer, Pig Tuple, Hive SerDe 等这些都是对象模型。例如 parquet-mr 项目里的 parquet-pig 项目就是负责把内存中的 Pig Tuple 序列化并按列存储成 Parquet 格式,以及反过来把 Parquet 文件的数据反序列化成 Pig Tuple。
这里需要注意的是 Avro, Thrift, Protocol Buffer 等都有他们自己的存储格式,但是 Parquet 并没有使用他们,而是使用了自己在 parquet-format 项目里定义的存储格式。所以如果项目中使用了 Avro 等对象模型,这些数据序列化到磁盘还是使用的 parquet-mr 定义的转换器把他们转换成 Parquet 自己的存储格式。
四、Parquet数据模型
Parquet 支持嵌套结构的数据模型,而非扁平式的数据模型(二维表),这是 Parquet 相对其他列存比如 ORC 的一大特点或优势。支持嵌套式结构,意味着 Parquet 能够很好的将诸如 Protobuf,thrift,json 等对象模型进行列式存储。
Parquet 的数据模型也是 schema 表达方式,根叫做message,message包含多个fields。
每个fields包含三个属性:
repetition:分为三种,required(唯一的),repeated(重复的)、optional(出现0次或一次,可选)
type:可以是一个primitive基本类型或是group复杂类型
name:字段名
举个例子说明:
message AddressBook {required string owner;repeated string ownerPhoneNumbers;repeated group contacts {required string name;optional string phoneNumber;}}
这个 schema 中每条记录表示一个人的 AddressBook。有且只有一个 owner, 可以有 0 个或者多个 ownerPhoneNumbers, 可以有 0 个或者多个 contacts。每个 contact 有且只有一个 name,这个 contact 的 phoneNumber 可以有0个或1个。这个 schema 可以用下面的树结构来表示。
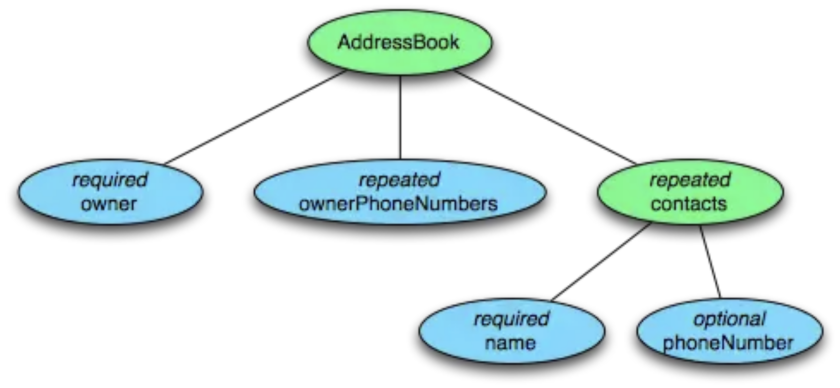
Parquet 格式的数据类型没有复杂的 Map, List, Set 等,而是使用 repeated fields 和 groups 来表示。例如 List 和 Set 可以被表示成一个 repeated field,Map 可以表示成一个包含有 key-value 对的 repeated group field,而且 key 是 required 的。
五、文件结构
一个Parquet文件的由Header、Data Block和Footer三部分组成。
1、在文件的首尾各有一个内容为PAR1的Magic Number,用于标识这个文件为Parquet文件。Header部分就是开头的Magic Number。
2、在Parquet中,存储数据的模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
行组,Row Group:Parquet 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。
列块,Column Chunk:行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。
页,Page:Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
Data Block就是具体存放数据的区域,由多个Row Group组成,每个Row Group包含了一批数据。
举个例子:假设一个文件有1000行数据,按照相应大小切分成了两个Row Group,每个拥有500行数据。每个Row Group中,数据按列汇集存放,每列的所有数据组合成一个Column Chunk。因此一个Row Group由多个Column Chunk组成,Column Chunk的个数等于列数。每个Column Chunk中,数据按照Page为最小单元来存储,根据内容分为Data Page和Dictionary Page。这样逐层设计的目的在于:
多个Row Group可以实现数据的并行加载
不同Column Chunk用来实现列存储
进一步分割成Page,可以实现更细粒度的数据访问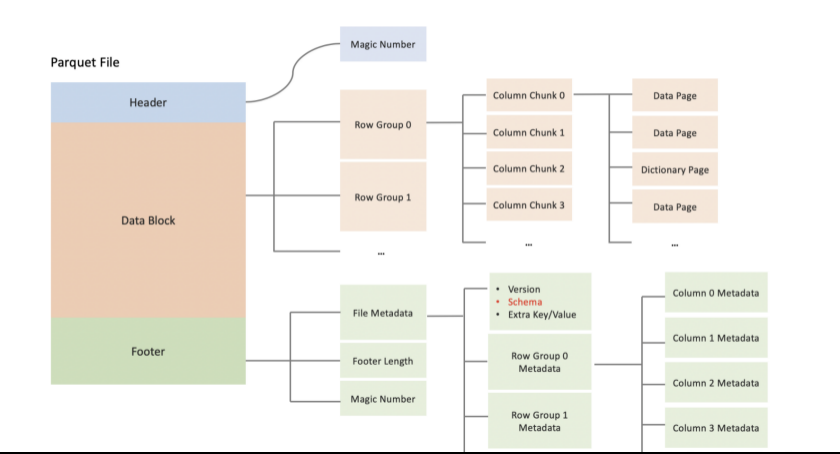
3、此外Footer部分由File Metadata、Footer Length和Magic Number三部分组成。Footer Length是一个4字节的数据,用于标识Footer部分的大小,帮助找到Footer的起始指针位置。Magic Number同样是PAR1。File Metada包含了非常重要的信息,包括Schema和每个Row Group的Metadata。每个Row Group的Metadata又由各个Column的Metadata组成,每个Column Metadata包含了其Encoding、Offset、Statistic信息等。
六、Parquet vs ORC
除了 Parquet,另一个常见的列式存储格式是 ORC(OptimizedRC File)。在 ORC 之前,Apache Hive 中就有一种列式存储格式称为 RCFile(RecordColumnar File),ORC 是对 RCFile 格式的改进,主要在压缩编码、查询性能方面做了优化。因此 ORC/RC 都源于 Hive,主要用来提高 Hive 查询速度和降低 Hadoop 的数据存储空间。
Parquet 与 ORC 的不同点总结以下:
嵌套结构支持:Parquet 能够很完美的支持嵌套式结构,而在这一点上 ORC 支持的并不好,表达起来复杂且性能和空间都损耗较大。
更新与 ACID 支持:ORC 格式支持 update、delete 操作与 ACID,而 Parquet 并不支持。
压缩与查询性能:在压缩空间与查询性能方面,Parquet 与 ORC 总体上相差不大。可能 ORC 要稍好于 Parquet。
查询引擎支持:这方面 Parquet 可能更有优势,支持 Hive、Impala、Presto 等各种查询引擎,而 ORC 与 Hive 接触的比较紧密,而与 Impala 适配的并不好。
七、Parquet常用工具
与JSON、CSV等文件相比,Parquet是无法直接读的,需要通过一些工具来窥探其内容,这里列举2种:
1、parquet-mr 项目提供的工具parquet-tools
由官方提供,下载源码编译jar包(https://github.com/apache/parquet-mr/tree/master/parquet-tools)
cd parquet-tools && mvn clean package -Plocal #包含hadoop客户端
cd parquet-tools && mvn clean package #不包含客户端
parquet-tools采用命令行形式,通过参数来指定相关功能
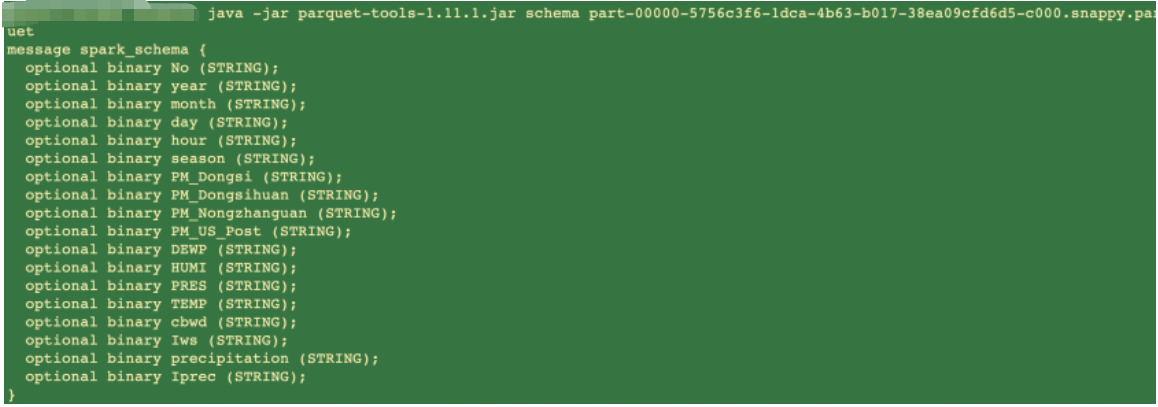
例如使用 parquet_tools schema demo.parquet,查看schema信息
本地jar包示例:
java -jar ./parquet-tools-1.11.2.jar schema part-00000-5756c3f6-1dca-4b63-b017-38ea09cfd6d5-c000.snappy.parquet
//常用命令示例:
//查看parquet文件中字段XXX的dump信息
parquet_tools dump -c 字段 -d demo.parquet
//查看parquet文件的dump信息
parquet_tools dump -d demo.parquet
//查看parquet文件的前10行内容
parquet_tools head -n 10 demo.parquet
//查看parquet文件的meta信息
parquet_tools meta demo.parquet
//查看parquet文件的schema信息
parquet_tools schema demo.parquet
2、开源工具:bigdata-file-viewer
通过下载jar包(https://github.com/Eugene-Mark/bigdata-file-viewer)
有UI可以查看数据,通过命令行启动UI

扩展:
论文翻译导读:https://blog.csdn.net/macyang/article/details/8566105

























")








还没有评论,来说两句吧...