HTTP相关知识总结
HTTP
- 一、引例
- 引:在浏览器中输入url地址(www.baidu.com),为什么会出现页面?
- 二、HTTP长连接,短连接
- 三、HTTP 1.0和HTTP 1.1以及HTTP2.0
- 1、HTTP1.0和HTTP1.1的一些区别
- 2、HTTP2
- 四、HTTP 和 HTTPS 的区别?
- 续:HTTPS的一次请求流程
- 五、状态码
- 六、HTTP包含哪几部分
- 1 、HTTP请求
- 2、HTTP请求响应
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW(万维网) 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。
HTTP位于应用层。HTTP是基于TCP的。
一、引例
引:在浏览器中输入url地址(www.baidu.com),为什么会出现页面?
主要是有这么几个步骤:
1、首先浏览器会根据这个域名解析到对应的IP(这个过程是交由DNS来解析的)
- 先去浏览器缓存中检查有没有解析过这个域名对应的IP,如果有直接返回
- 如果没有,就去本地缓存中去寻找(对应的就是本地hosts文件,查看有没有对应的映射) ,如果有则使用这个域名对应的ip
- 如果没有则会请求本地DNS服务器去查询它的缓存记录,如果存在就返回(80%是都可以查到的)
- 如果本地DNS服务器没有的话,就去请求DNS根服务器进行查询,根DNS服务器里面没有域名与IP的对应关系,但是可以返回给本地DNS服务器一个域服务器的地址,告诉本地DNS服务器去这个域服务器上去寻找
- 本地DNS服务器继续向域服务器发出请求,域服务器会告诉本地DNS服务器,你的域名的解析服务器的地址。
- 然后本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系,拿到这个IP,同时进行缓存以便下次查询使用
- 2、拿到IP以后就相当于找到服务器,先建立TCP连接(三次握手)
- 3、连接成功,浏览器想服务器发送HTTP请求
- 4、服务器处理接收的请求(包括参数、cookies等等),并返回HTTP报文(可以使HTML响应)
- 5、浏览器根据获得的响应渲染页面
- 6、断开连接
二、HTTP长连接,短连接
短连接
- 简单来讲就是客户端和服务器端每进行一次HTTP操作,就建立一次连接,当任务结束(数据传输完毕)就关闭连接
- 管理简单,对服务器压力小,但是频繁的请求会在TCP频繁建立连接、关闭连接上耗费大量的时间
长连接
- 长连接的话,举个例子来讲就是当我们打开一个网页的时候,客户端和服务端之间用于传输的HTTP的数据的TCP连接不会关闭,客户端再次访问这个服务器的时候,会继续使用这一条已经建立的连接。
- 从HTTP/1.1起,默认使用长连接
使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive- Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
- 长连接一般用于请求比较频繁以及点对点的通讯这种要求响应速度的,还有就是数据库连接使用的是长连接
- 长连接有一个问题就是,因为长时间保持着连接,随着客户端连接数的增多,服务器可能会崩掉
三、HTTP 1.0和HTTP 1.1以及HTTP2.0
参考博文:https://mp.weixin.qq.com/s/GICbiyJpINrHZ41u_4zT-A?
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。
1、HTTP1.0和HTTP1.1的一些区别
- HTTP1.1引入了长连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive。HTTP1.0需要使用keep-alive参数来告知服务器端要建立一个长连接。
- HTTP1.1增加了24个错误状态响应码,比如有100(Continue,在post请求中有应用)、409(Conflict)表示请求的资源与资源的当前状态发生冲突、410(Gone)表示服务器上的某个资源被永久性的删除。
- 缓存处理:在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
- HTTP 1.1增加host字段:在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
大家可以了解一下SPDY对HTTP1.x的优化(SPDY强制使用的是HTTPS)
2、HTTP2
- 性能十分棒(低延迟):我们通过看这个就有所了解了https://http2.akamai.com/demo
相比于HTTP1.x新增的特性
- 新的二进制格式:HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
- 多路复用 :就是连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
- header压缩。对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- 服务端推送:例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。
四、HTTP 和 HTTPS 的区别?
参考博文:http 与 https 的区别以及加密详解
续:HTTPS的一次请求流程
- 先建立一个tcp的连接
- 浏览器获取证书
- 浏览器验证证书->去ca验证,ca已经把根证书存到了我们的操作系统中
- 浏览器通过公钥加密一个对称密钥
- 服务器接收到密文,通过自己的私钥解密,得到对称密钥
- 接下来的传输使用对称加密算法,以及对称密钥进行通信
五、状态码
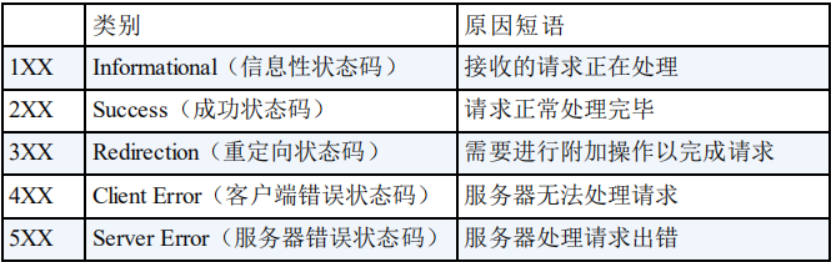
- 100:继续请求(例如post请求中的应用)
- 200:请求成功(status 200是我们一生的追求)
- 301:永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
- 302:临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI
- 305:使用代理。所请求的资源必须通过代理访问
- 400:客户端请求的语法错误,服务器无法理解
- 403:服务器理解请求客户端的请求,但是拒绝执行此请求
- 404:(入门常客) 服务器无法根据客户端的请求找到资源(网页)。
- 405:客户端请求中的方法被禁止
- 500:服务器内部错误,无法完成请求
- 502:作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
- 504:充当网关或代理的服务器,未及时从远端服务器获取请求
六、HTTP包含哪几部分
1 、HTTP请求
请求行
- 方法字段:GET、POST、DELETE等
- URL字段
- HTTP协议版本
请求头(key:value)
- Connection:Keep-Alive
连接类型,持续连接 - Host:localhost
请求的地址域名和端口,不包括协议 - Content-Type: application/json
- Cookie: JSESSIONID=10A0F661B3B*******B09058DF
- Origin: http://www.study.com
请求来源地址,包括协议
- Connection:Keep-Alive
空行
- 发送回车符和换行符,通知服务器以下不再有请求头
请求体
- 请求数据
2、HTTP请求响应
- 状态行
- 消息报头
- 响应正文




























")




还没有评论,来说两句吧...