Python 大规模异步新闻爬虫、google翻译、百度翻译、有道翻译、百度指数
参考:https://www.yuanrenxue.com/crawler/news-crawler-urlpool.html
url_pool.py
# -*- coding: utf-8 -*-# @Author : 佛祖保佑, 永无 bug# @Date :# @File : url_pool.py# @Software: PyCharm# @description : XXXimport timeimport redisimport pickleimport urllib.parse as urlparseclass UrlDB(object):"""使用 redis 来存储 URL"""status_failure = b'0'status_success = b'1'def __init__(self, db_name):# self.name = db_name + '.urldb'# self.db = leveldb.LevelDB(self.name)self.name = db_name if db_name else 'redis_hashmap'self.db = redis.StrictRedis()def set_success(self, url=None):if isinstance(url, str):url = url.encode('utf8')try:self.db.hset(self.name, url, self.status_success)status = Trueexcept BaseException as be:status = Falsereturn statusdef set_failure(self, url):if isinstance(url, str):url = url.encode('utf8')try:self.db.hset(self.name, url, self.status_failure)status = Trueexcept BaseException as be:status = Falsereturn statusdef has(self, url):if isinstance(url, str):url = url.encode('utf8')try:attr = self.db.hget(self.name, url)return attrexcept BaseException as be:passreturn Falseclass UrlPool(object):""" 使用 UrlPool 来抓取和管理URLs"""def __init__(self, pool_name):self.name = pool_nameself.db = UrlDB(pool_name)self.waiting = dict() # {host: set([urls]), } 按host分组,记录等待下载的URLself.pending = dict() # {url: pended_time, } 记录已被取出(self.pop())但还未被更新状态(正在下载)的URLself.failure = dict() # {url: times,} 记录失败的URL的次数self.failure_threshold = 3self.pending_threshold = 10 # pending的最大时间,过期要重新下载self.waiting_count = 0 # self.waiting 字典里面的url的个数self.max_hosts = ['', 0] # [host: url_count] 目前pool中url最多的host及其url数量self.hub_pool = dict() # {url: last_query_time, } 存放hub urlself.hub_refresh_span = 0self.load_cache()passdef __del__(self):self.dump_cache()def load_cache(self,):path = self.name + '.pkl'try:with open(path, 'rb') as f:self.waiting = pickle.load(f)cc = [len(v) for k, v in self.waiting.items()]print('saved pool loaded! urls:', sum(cc))except BaseException as be:passdef dump_cache(self):path = self.name + '.pkl'try:with open(path, 'wb') as f:pickle.dump(self.waiting, f)print('self.waiting saved!')except BaseException as be:passdef set_hubs(self, urls, hub_refresh_span):self.hub_refresh_span = hub_refresh_spanself.hub_pool = dict()for url in urls:self.hub_pool[url] = 0def set_status(self, url, status_code):if url in self.pending:self.pending.pop(url)if status_code == 200:self.db.set_success(url)returnif status_code == 404:self.db.set_failure(url)returnif url in self.failure:self.failure[url] += 1if self.failure[url] > self.failure_threshold:self.db.set_failure(url)self.failure.pop(url)else:self.add(url)else:self.failure[url] = 1self.add(url)def push_to_pool(self, url=None):host = urlparse.urlparse(url).netlocif not host or '.' not in host:print('try to push_to_pool with bad url:', url, ', len of ur:', len(url))return Falseif host in self.waiting:if url in self.waiting[host]:return Trueself.waiting[host].add(url)if len(self.waiting[host]) > self.max_hosts[1]:self.max_hosts[1] = len(self.waiting[host])self.max_hosts[0] = hostelse:self.waiting[host] = set([url])self.waiting_count += 1return Truedef add(self, url=None, always=False):if always:return self.push_to_pool(url)pended_time = self.pending.get(url, 0)if time.time() - pended_time < self.pending_threshold:print('being downloading:', url)returnif self.db.has(url):returnif pended_time:self.pending.pop(url)return self.push_to_pool(url)def add_many(self, url_list=None, always=False):if isinstance(url_list, str):print('urls is a str !!!!', url_list)self.add(url_list, always)else:for url in url_list:self.add(url, always)def pop(self, count=None, hub_percent=50):print('\n\tmax of host:', self.max_hosts)# 取出的url有两种类型:hub=1, 普通=0url_attr_url = 0url_attr_hub = 1# 1. 首先取出hub,保证获取hub里面的最新url.hubs = dict()hub_count = count * hub_percent // 100for hub in self.hub_pool:span = time.time() - self.hub_pool[hub]if span < self.hub_refresh_span:continuehubs[hub] = url_attr_hub # 1 means hub-urlself.hub_pool[hub] = time.time()if len(hubs) >= hub_count:break# 2. 再取出普通urlleft_count = count - len(hubs)urls = dict()for host in self.waiting:if not self.waiting[host]:continueurl = self.waiting[host].pop()urls[url] = url_attr_urlself.pending[url] = time.time()if self.max_hosts[0] == host:self.max_hosts[1] -= 1if len(urls) >= left_count:breakself.waiting_count -= len(urls)print('To pop:%s, hubs: %s, urls: %s, hosts:%s' % (count, len(hubs), len(urls), len(self.waiting)))urls.update(hubs)return urlsdef size(self,):return self.waiting_countdef empty(self,):return self.waiting_count == 0def test():pool = UrlPool('crawl_url_pool')urls = ['http://1.a.cn/xyz','http://2.a.cn/xyz','http://3.a.cn/xyz','http://1.b.cn/xyz-1','http://1.b.cn/xyz-2','http://1.b.cn/xyz-3','http://1.b.cn/xyz-4',]pool.add_many(urls)# del pool# pool = UrlPool('crawl_url_pool')urls = pool.pop(5)urls = list(urls.keys())print('pop:', urls)print('pending:', pool.pending)pool.set_status(urls[0], 200)print('pending:', pool.pending)pool.set_status(urls[1], 404)print('pending:', pool.pending)if __name__ == '__main__':test()
ezpymysql.py
:大规模异步新闻爬虫: 让MySQL 数据库操作更方便 - 猿人学
# file: ezpymysql.py# Author: veelion"""A lightweight wrapper around PyMySQL.only for python3"""import timeimport loggingimport tracebackimport pymysqlimport pymysql.cursorsversion = "0.7"version_info = (0, 7, 0, 0)class Connection(object):"""A lightweight wrapper around PyMySQL."""def __init__(self, host, database, user=None, password=None,port=0, max_idle_time=7 * 3600, connect_timeout=10,time_zone="+0:00", charset="utf8mb4", sql_mode="TRADITIONAL"):self.host = hostself.database = databaseself.max_idle_time = float(max_idle_time)args = dict(use_unicode=True, charset=charset, database=database,init_command=('SET time_zone = "%s"' % time_zone),cursorclass=pymysql.cursors.DictCursor,connect_timeout=connect_timeout, sql_mode=sql_mode)if user is not None:args["user"] = userif password is not None:args["passwd"] = password# We accept a path to a MySQL socket file or a host(:port) stringif "/" in host:args["unix_socket"] = hostelse:self.socket = Nonepair = host.split(":")if len(pair) == 2:args["host"] = pair[0]args["port"] = int(pair[1])else:args["host"] = hostargs["port"] = 3306if port:args['port'] = portself._db = Noneself._db_args = argsself._last_use_time = time.time()try:self.reconnect()except BaseException as be:logging.error("Cannot connect to MySQL on %s", self.host, exc_info=True)def _ensure_connected(self):# Mysql by default closes client connections that are idle for# 8 hours, but the client library does not report this fact until# you try to perform a query and it fails. Protect against this# case by preemptively closing and reopening the connection# if it has been idle for too long (7 hours by default).if self._db is None or (time.time() - self._last_use_time > self.max_idle_time):self.reconnect()self._last_use_time = time.time()def _cursor(self):self._ensure_connected()return self._db.cursor()def __del__(self):self.close()def close(self):"""Closes this database connection."""if getattr(self, "_db", None) is not None:self._db.close()self._db = Nonedef reconnect(self):"""Closes the existing database connection and re-opens it."""self.close()self._db = pymysql.connect(**self._db_args)self._db.autocommit(True)def query(self, query, *parameters, **kwparameters):"""Returns a row list for the given query and parameters."""cursor = self._cursor()try:cursor.execute(query, kwparameters or parameters)result = cursor.fetchall()return resultfinally:cursor.close()def get(self, query, *parameters, **kwparameters):"""Returns the (singular) row returned by the given query."""cursor = self._cursor()try:cursor.execute(query, kwparameters or parameters)return cursor.fetchone()finally:cursor.close()def execute(self, query, *parameters, **kwparameters):"""Executes the given query, returning the lastrowid from the query."""cursor = self._cursor()try:cursor.execute(query, kwparameters or parameters)return cursor.lastrowidexcept Exception as e:if e.args[0] == 1062:passelse:traceback.print_exc()raise efinally:cursor.close()insert = execute# =============== high level method for table ===================def table_has(self, table_name, field, value):if isinstance(value, str):value = value.encode('utf8')sql_str = f'SELECT {field} FROM {table_name} WHERE {field}="{value}"'d = self.get(sql_str)return ddef table_insert(self, table_name, item):"""item is a dict : key is mysql table field"""fields = list(item.keys())values = list(item.values())field_str = ','.join(fields)val_str = ','.join(['%s'] * len(item))for i in range(len(values)):if isinstance(values[i], str):values[i] = values[i].encode('utf8')sql_str = f'INSERT INTO {table_name} ({field_str}) VALUES({val_str})'try:last_id = self.execute(sql_str, *values)return last_idexcept Exception as e:if e.args[0] == 1062:# just skip duplicated itempasselse:traceback.print_exc()print('sql:', sql)print('item:')for i in range(len(fields)):vs = str(values[i])if len(vs) > 300:print(fields[i], ' : ', len(vs), type(values[i]))else:print(fields[i], ' : ', vs, type(values[i]))raise edef table_update(self, table_name, updates, field_where, value_where):"""updates is a dict of {field_update:value_update}"""upsets = []values = []for k, v in updates.items():s = '%s=%%s' % kupsets.append(s)values.append(v)upsets = ','.join(upsets)sql_str = f'UPDATE {table_name} SET {upsets} WHERE {field_where}="{value_where}"'self.execute(sql_str, *values)if __name__ == '__main__':db = Connection('localhost','db_name','user','password')# 获取一条记录sql = 'select * from test_table where id=%s'data = db.get(sql, 2)# 获取多天记录sql = 'select * from test_table where id>%s'data = db.query(sql, 2)# 插入一条数据sql = 'insert into test_table(title, url) values(%s, %s)'last_id = db.execute(sql, 'test', 'http://a.com/')# 或者last_id = db.insert(sql, 'test', 'http://a.com/')# 使用更高级的方法插入一条数据item = {'title': 'test','url': 'http://a.com/',}last_id = db.table_insert('test_table', item)
functions.py
# -*- coding: utf-8 -*-# @Author : 佛祖保佑, 永无 bug# @Date :# @File : functions.py# @Software: PyCharm# @description : XXXimport reimport requestsimport cchardetimport tracebackimport urllib.parse as urlparseasync def fetch(session=None, url=None, headers=None, timeout=9, binary=False):_headers = {'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; ''Windows NT 6.1; Win64; x64; Trident/5.0)'),}_headers = headers if headers else _headerstry:async with session.get(url, headers=_headers, timeout=timeout) as response:status_code = response.statushtml_bin_or_text = ''html_content = await response.read()if not binary:encoding = cchardet.detect(html_content)['encoding']html_bin_or_text = html_content.decode(encoding, errors='ignore')request_url = str(response.url)except Exception as e:msg = 'Failed download: {} | exception: {}, {}'.format(url, str(type(e)), str(e))print(msg)html_bin_or_text = ''status_code = -1request_url = urlreturn status_code, html_bin_or_text, request_urldef downloader(url=None, timeout=10, headers=None, debug=False, binary=False):_headers = {'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; ''Windows NT 6.1; Win64; x64; Trident/5.0)'),}_headers = headers if headers else _headersrequest_url = urltry:r = requests.get(url, headers=_headers, timeout=timeout)if binary:html_bin_or_text = r.contentelse:encoding = cchardet.detect(r.content)['encoding']html_bin_or_text = r.content.decode(encoding, errors='ignore')status_code = r.status_coderequest_url = r.urlexcept BaseException as be:if debug:traceback.print_exc()msg = 'failed download: {}'.format(url)print(msg)html_bin_or_text = b'' if binary else ''status_code = -1return status_code, html_bin_or_text, request_urlg_bin_postfix = {'exe', 'doc', 'docx', 'xls', 'xlsx', 'ppt', 'pptx', 'pdf','jpg', 'png', 'bmp', 'jpeg', 'gif', 'zip', 'rar', 'tar','bz2', '7z', 'gz', 'flv', 'mp4', 'avi', 'wmv', 'mkv', 'apk'}g_news_postfix = ['.html?', '.htm?', '.shtml?', '.shtm?']def clean_url(url=None):# 1. 是否为合法的http urlif not url.startswith('http'):return ''# 2. 去掉静态化url后面的参数for np in g_news_postfix:p = url.find(np)if p > -1:p = url.find('?')url = url[:p]return url# 3. 不下载二进制类内容的链接up = urlparse.urlparse(url)path = up.pathif not path:path = '/'postfix = path.split('.')[-1].lower()if postfix in g_bin_postfix:return ''# 4. 去掉标识流量来源的参数# badquery = ['spm', 'utm_source', 'utm_source', 'utm_medium', 'utm_campaign']good_queries = []for query in up.query.split('&'):qv = query.split('=')if qv[0].startswith('spm') or qv[0].startswith('utm_'):continueif len(qv) == 1:continuegood_queries.append(query)query = '&'.join(good_queries)url = urlparse.urlunparse((up.scheme,up.netloc,path,up.params,query,'' # crawler do not care fragment))return urlg_pattern_tag_a = re.compile(r'<a[^>]*?href=[\'"]?([^> \'"]+)[^>]*?>(.*?)</a>', re.I | re.S | re.M)def extract_links_re(url=None, html=None):"""use re module to extract links from html"""news_links = set()tag_a_list = g_pattern_tag_a.findall(html)for tag_a in tag_a_list:link = tag_a[0].strip()if not link:continuelink = urlparse.urljoin(url, link)link = clean_url(link)if not link:continuenews_links.add(link)return news_linksdef init_file_logger(f_name=None):# config loggingimport loggingfrom logging.handlers import TimedRotatingFileHandlerch = TimedRotatingFileHandler(f_name, when="midnight")ch.setLevel(logging.INFO)# create formatterfmt = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'formatter = logging.Formatter(fmt)# add formatter to chch.setFormatter(formatter)logger = logging.getLogger(f_name)# add ch to loggerlogger.addHandler(ch)return loggerif __name__ == '__main__':temp_url = 'http://news.baidu.com/'t_status_code, t_html, t_url = downloader(url=temp_url)print(f'[{t_status_code}, {t_url}]:{len(t_html)}')
config.py
db_host = 'localhost'db_db = 'crawler'db_user = 'your-user'db_password = 'your-password'
新闻爬虫 ( 同步 )
news_sync.py
# -*- coding: utf-8 -*-# @Author : 佛祖保佑, 永无 bug# @Date :# @File : news_sync.py# @Software: PyCharm# @description : XXXimport urllib.parse as urlparseimport lzmaimport farmhashimport tracebackfrom ezpymysql import Connectionfrom url_pool import UrlPoolimport functions as fnimport configclass NewsCrawlerSync:def __init__(self, name):self.db = Connection(config.db_host,config.db_db,config.db_user,config.db_password)self.logger = fn.init_file_logger(name + '.log')self.url_pool = UrlPool(name)self.hub_hosts = Noneself.load_hubs()def load_hubs(self,):sql = 'select url from crawler_hub'data = self.db.query(sql)self.hub_hosts = set()hubs = []for d in data:host = urlparse.urlparse(d['url']).netlocself.hub_hosts.add(host)hubs.append(d['url'])self.url_pool.set_hubs(hubs, 300)def save_to_db(self, url, html):url_hash = farmhash.hash64(url)sql = f'select url from crawler_html where urlhash={url_hash}'d = self.db.get(sql, url_hash)if d:if d['url'] != url:msg = 'farm_hash collision: %s <=> %s' % (url, d['url'])self.logger.error(msg)return Trueif isinstance(html, str):html = html.encode('utf8')html_lzma = lzma.compress(html)sql = 'insert into crawler_html(urlhash, url, html_lzma) values(%s, %s, %s)'good = Falsetry:self.db.execute(sql, url_hash, url, html_lzma)good = Trueexcept Exception as e:if e.args[0] == 1062:# Duplicate entrygood = Truepasselse:traceback.print_exc()raise ereturn gooddef filter_good(self, urls):good_links = []for url in urls:host = urlparse.urlparse(url).netlocif host in self.hub_hosts:good_links.append(url)return good_linksdef process(self, url, is_hub):status, html, redirected_url = fn.downloader(url)self.url_pool.set_status(url, status)if redirected_url != url:self.url_pool.set_status(redirected_url, status)# 提取hub网页中的链接, 新闻网页中也有“相关新闻”的链接,按需提取if status != 200:returnif is_hub:new_links = fn.extract_links_re(redirected_url, html)good_links = self.filter_good(new_links)print(f"{len(good_links)} / {len(new_links)}, good_links/new_links")self.url_pool.add_many(good_links)else:self.save_to_db(redirected_url, html)def run(self,):while 1:urls = self.url_pool.pop(5)for url, is_hub in urls.items():self.process(url, is_hub)if __name__ == '__main__':crawler = NewsCrawlerSync('sync_spider')crawler.run()
新闻爬虫 ( 异步 )
news_async.py
# -*- coding: utf-8 -*-# @Author : 佛祖保佑, 永无 bug# @Date :# @File : news_async.py# @Software: PyCharm# @description : XXXimport tracebackimport timeimport asyncioimport aiohttpimport urllib.parse as urlparseimport farmhashimport lzma# import uvloop# asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())import sanicdbfrom url_pool import UrlPoolimport functions as fnimport configclass NewsCrawlerAsync:def __init__(self, name):self.hub_hosts = set()self._workers = 0self._workers_max = 30self.logger = fn.init_file_logger(name + '.log')self.url_pool = UrlPool(name)self.loop = asyncio.get_event_loop()self.session = aiohttp.ClientSession(loop=self.loop)self.db = sanicdb.SanicDB(config.db_host,config.db_db,config.db_user,config.db_password,loop=self.loop)async def load_hubs(self, ):sql = 'select url from crawler_hub'data = await self.db.query(sql)hubs = []for d in data:host = urlparse.urlparse(d['url']).netlocself.hub_hosts.add(host)hubs.append(d['url'])self.url_pool.set_hubs(hubs, 300)async def save_to_db(self, url, html):url_hash = farmhash.hash64(url)sql = 'select url from crawler_html where urlhash=%s'd = await self.db.get(sql, url_hash)if d:if d['url'] != url:msg = 'farmhash collision: %s <=> %s' % (url, d['url'])self.logger.error(msg)return Trueif isinstance(html, str):html = html.encode('utf8')html_lzma = lzma.compress(html)sql = 'insert into crawler_html(urlhash, url, html_lzma) values(%s, %s, %s)'good = Falsetry:await self.db.execute(sql, url_hash, url, html_lzma)good = Trueexcept Exception as e:if e.args[0] == 1062:# Duplicate entrygood = Truepasselse:traceback.print_exc()raise ereturn gooddef filter_good(self, urls):good_links = []for url in urls:host = urlparse.urlparse(url).netlocif host in self.hub_hosts:good_links.append(url)return good_linksasync def process(self, url, is_hub):status, html, redirected_url = await fn.fetch(self.session, url)self.url_pool.set_status(url, status)if redirected_url != url:self.url_pool.set_status(redirected_url, status)# 提取hub网页中的链接, 新闻网页中也有“相关新闻”的链接,按需提取if status != 200:self._workers -= 1returnif is_hub:new_links = fn.extract_links_re(redirected_url, html)good_links = self.filter_good(new_links)print(f"{len(good_links)} / {len(new_links)}, good_links / new_links")self.url_pool.add_many(good_links)else:await self.save_to_db(redirected_url, html)self._workers -= 1async def loop_crawl(self):await self.load_hubs()last_rating_time = time.time()counter = 0while 1:to_pop = self._workers_max - self._workerstasks = self.url_pool.pop(to_pop)if not tasks:print('no url to crawl, sleep')await asyncio.sleep(3)continuefor url, is_hub in tasks.items():self._workers += 1counter += 1print('crawl:', url)asyncio.ensure_future(self.process(url, is_hub))gap = time.time() - last_rating_timeif gap > 5:rate = counter / gapprint(f'\tloop_crawl() rate:{round(rate, 2)}, counter: {counter}, workers: {self._workers}')last_rating_time = time.time()counter = 0if self._workers > self._workers_max:print('====== got workers_max, sleep 3 sec to next worker =====')await asyncio.sleep(3)def run(self):try:self.loop.run_until_complete(self.loop_crawl())except KeyboardInterrupt:print('stopped by yourself!')del self.url_poolpassif __name__ == '__main__':nc = NewsCrawlerAsync('async_spider')nc.run()
分布式爬虫 ( CS 模型 )
server.py
# -*- coding: utf-8 -*-# @Author : 佛祖保佑, 永无 bug# @Date :# @File : server.py# @Software: PyCharm# @description : XXXfrom sanic import Sanicfrom sanic import responsefrom my_url_pool import UrlPoolurl_pool = UrlPool(__file__)# 初始化 url_pool,根据你的需要进行修改hub_urls = []url_pool.set_hubs(hub_urls, 300)url_pool.add('https://news.sina.com.cn/')# initmain_app = Sanic(__name__)@main_app.listener('after_server_stop')async def cache_url_pool(app=None, loop=None):global url_poolprint('caching url_pool after_server_stop')del url_poolprint('bye!')@main_app.route('/task')async def task_get(request=None):count = request.args.get('count', 10)try:count = int(count)except BaseException as be:count = 10urls = url_pool.pop(count)return response.json(urls)@main_app.route('/task', methods=['POST', ])async def task_post(request=None):result = request.jsonurl_pool.set_status(result['url'], result['status'])if result['url_real'] != result['url']:url_pool.set_status(result['url_real'], result['status'])if result['new_urls']:print('receive URLs:', len(result['new_urls']))for url in result['new_urls']:url_pool.add(url)return response.text('ok')if __name__ == '__main__':main_app.run(host='0.0.0.0', port=8080, debug=False, access_log=False, workers=1)pass
client.py
# -*- coding: utf-8 -*-# @Author : 佛祖保佑, 永无 bug# @Date :# @File : client.py# @Software: PyCharm# @description : XXXimport reimport cchardetimport tracebackimport timeimport jsonimport asyncioimport urllib.parse as urlparseimport aiohttp# import uvloop# asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())p_tag_a = re.compile(r'<a[^>]*?href=[\'"]?([^> \'"]+)[^>]*?>(.*?)</a>', re.I | re.S | re.M)def extract_links_re(url, html):new_links = set()aa = p_tag_a.findall(html)for a in aa:link = a[0].strip()if not link:continuelink = urlparse.urljoin(url, link)if not link.startswith('http'):continuenew_links.add(link)return new_linksclass CrawlerClient:def __init__(self, ):self._workers = 0self.workers_max = 20self.server_host = 'localhost'self.server_port = 8080self.headers = {'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; ''Windows NT 6.1; Win64; x64; Trident/5.0)')}self.loop = asyncio.get_event_loop()self.queue = asyncio.Queue(loop=self.loop)self.session = aiohttp.ClientSession(loop=self.loop)async def download(self, url, timeout=25):status_code = 900html = ''url_now = urltry:async with self.session.get(url_now, headers=self.headers, timeout=timeout) as response:status_code = response.statushtml = await response.read()encoding = cchardet.detect(html)['encoding']html = html.decode(encoding, errors='ignore')url_now = str(response.url)except BaseException as be:# traceback.print_exc()print('=== exception: ', be, type(be), str(be))msg = 'Failed download: {} | exception: {}, {}'.format(url, str(type(be)), str(be))print(msg)return status_code, html, url_nowasync def get_urls(self, ):count = self.workers_max - self.queue.qsize()if count <= 0:print('no need to get urls this time')return Noneurl = f'http://{self.server_host}:{self.server_port}/task?count={count}'try:async with self.session.get(url, timeout=3) as response:if response.status not in [200, 201]:returnjsn = await response.text()urls = json.loads(jsn)msg = f'get_urls() to get [{count}] but got[{len(urls)}], @{time.strftime("%Y-%m-%d %H:%M:%S")}'print(msg)for kv in urls.items():await self.queue.put(kv)print('queue size:', self.queue.qsize(), ', _workers:', self._workers)except BaseException as be:traceback.print_exc()returnasync def send_result(self, result):url = f'http://{self.server_host}:{self.server_port}/task'try:async with self.session.post(url, json=result, timeout=3) as response:return response.statusexcept BaseException as be:traceback.print_exc()pass@staticmethoddef save_html(url, html):print('saved:', url, len(html))@staticmethoddef filter_good(urls):"""根据抓取目的过滤提取的URLs,只要你想要的"""good = []for url in urls:if url.startswith('http'):good.append(url)return goodasync def process(self, url, is_hub):status, html, url_now = await self.download(url)self._workers -= 1print('downloaded:', url, ', html:', len(html))if html:new_urls = extract_links_re(url, html)new_urls = self.filter_good(new_urls)self.save_html(url, html)else:new_urls = []result = {'url': url,'url_real': url_now,'status': status,'new_urls': new_urls,}await self.send_result(result)async def loop_get_urls(self, ):print('loop_get_urls() start')while 1:await self.get_urls()await asyncio.sleep(1)async def loop_crawl(self, ):print('loop_crawl() start')asyncio.ensure_future(self.loop_get_urls())counter = 0while 1:item = await self.queue.get()url, url_level = itemself._workers += 1counter += 1asyncio.ensure_future(self.process(url, url_level))if self._workers > self.workers_max:print('====== got workers_max, sleep 3 sec to next worker =====')await asyncio.sleep(3)def start(self):try:self.loop.run_until_complete(self.loop_crawl())except KeyboardInterrupt:print('stopped by yourself!')passdef run():ant = CrawlerClient()ant.start()if __name__ == '__main__':run()
google 翻译
google 翻译:Google 翻译
# -*- coding: utf-8 -*-# @Author : 佛祖保佑, 永无 bug# @Date :# @File : translate_google.py# @Software: PyCharm# @description : XXXimport requestsimport urllib3urllib3.disable_warnings()def test(kw=None):url = 'https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&hl=zh-CN'custom_headers = {'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8'}# kw = 'this is a test'payload = f"f.req=[[[\"MkEWBc\",\"[[\\\"{kw}\\\",\\\"auto\\\",\\\"zh-CN\\\",true],[null]]\",null,\"generic\"]]]&"resp = requests.post(url, data=payload, headers=custom_headers)print(resp.status_code)print(resp.text)passif __name__ == '__main__':kw_list = ['I love u', 'hello, baby', 'king','this is a test']for item in kw_list:test(kw=item)pass
百度 翻译
百度翻译:百度翻译-200种语言互译、沟通全世界!
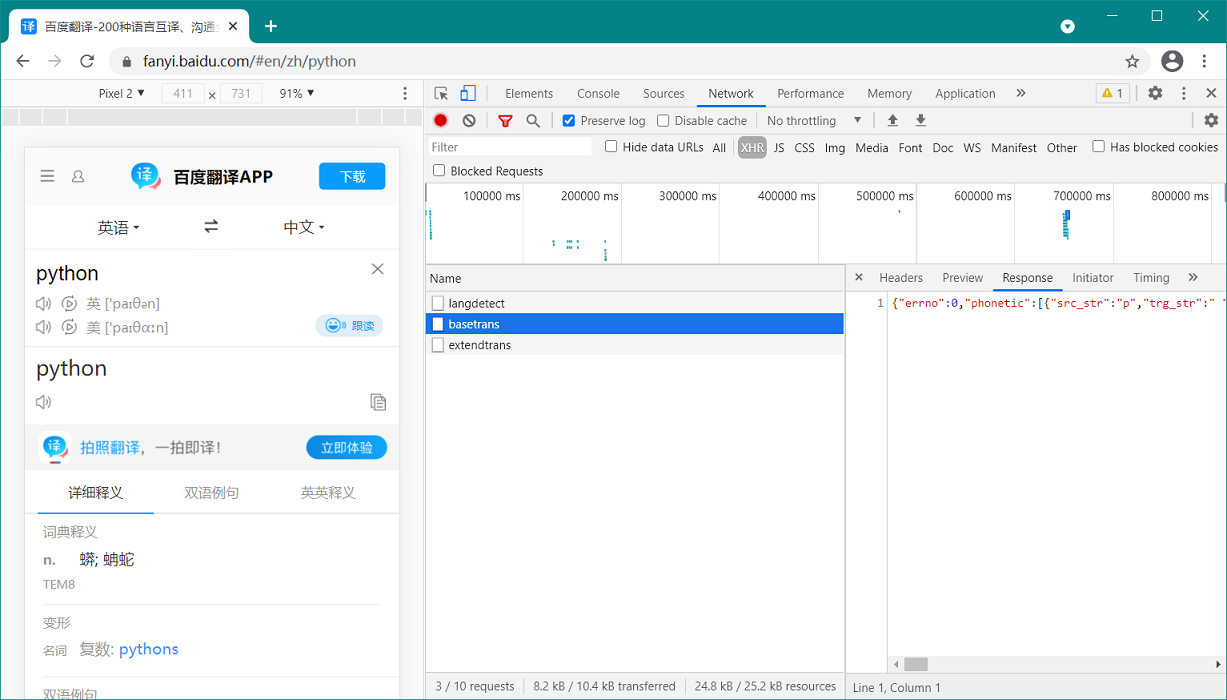
查看 basetrans 请求。
( 多请求几次,可以发现 sign 每次都不一样,所以需要 逆向 sign )

使用 postman 来精简请求参数,看那些参数是必须的,那些参数是可以直接删除的。精简后参数
- 请求URL:https://fanyi.baidu.com/basetrans
- 请求头:Content-Type: application/x-www-form-urlencoded
Cookie: BAIDUID=AF87393A8DB7C8FED7859A909FF081A3:SL=0:NR=50:FG=1;
User-Agent: Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36 - 请求 body:query=king&from=en&to=zh&token=94c55bca8b920035077b58d58ba32bea&sign=612765.899756
postman 生成的 Python 代码:
import requestsurl = "https://fanyi.baidu.com/basetrans"payload = "query=king&from=en&to=zh&token=94c55bca8b920035077b58d58ba32bea&sign=612765.899756"headers = {'Content-Type': 'application/x-www-form-urlencoded','Cookie': 'BAIDUID=AF87393A8DB7C8FED7859A909FF081A3:SL=0:NR=50:FG=1;','User-Agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) ''AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36'}response = requests.request("POST", url, headers=headers, data=payload)print(response.text)
JS 断点调试

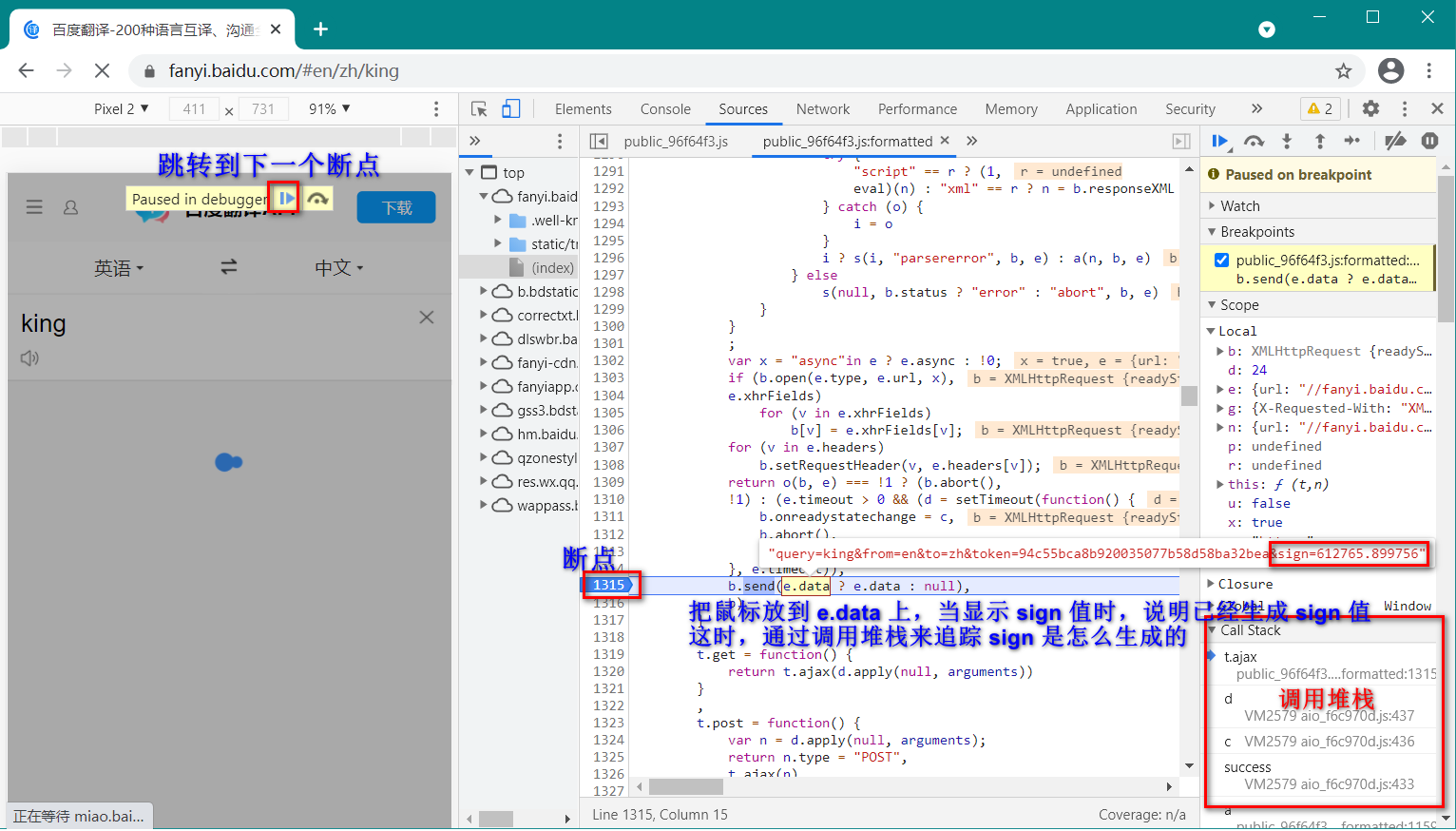
打断点,然后通过调用堆栈追踪 sign 是怎么生成的。。。
因为 多个 ajax 请求都会走 b.send(e.data ? e.data:null) 这个函数,所以需要点击好几次 “跳转到下一个断点“ 才能看到 sign 值。
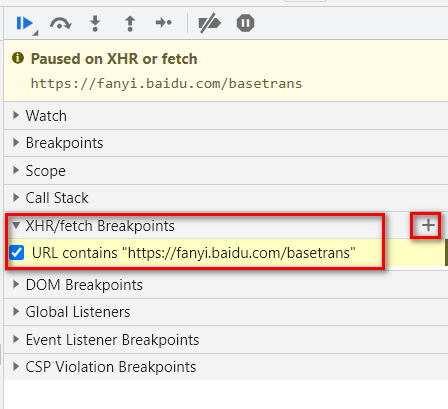
如果想直接断点就能看到 sign 值,则可以添加 “URL包含“ 断点。
这里使用 “跳转到下一个断点“ 来追踪 sign 值。
生成 sign 的函数
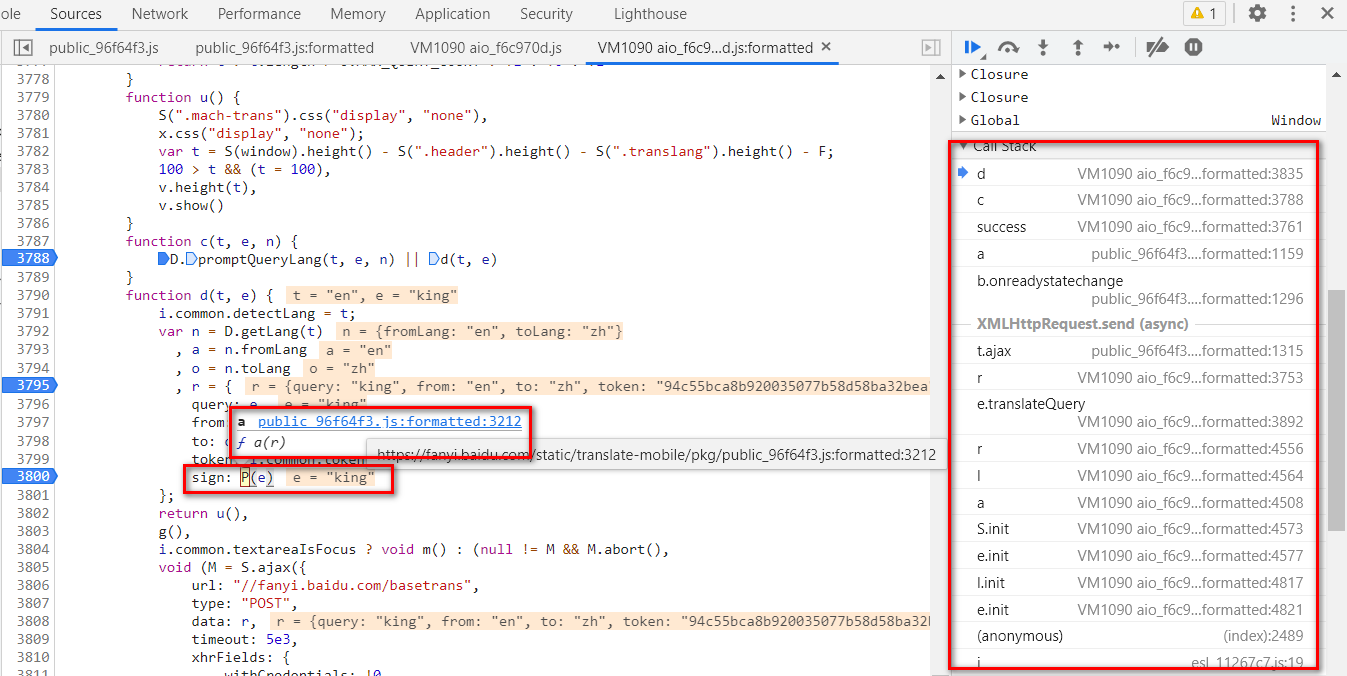
点击 P(e) 函数,查看函数实现

方法 1:直接使用 Python 实现这个函数的逻辑
方法 2:把 js 代码扣出来,直接 Python 执行
代码太多,这里直接 扣 js 代码
function n(r, o) {for (var t = 0; t < o.length - 2; t += 3) {var e = o.charAt(t + 2);e = e >= "a" ? e.charCodeAt(0) - 87 : Number(e),e = "+" === o.charAt(t + 1) ? r >>> e : r << e,r = "+" === o.charAt(t) ? r + e & 4294967295 : r ^ e}return r}function sign(r) {var t = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);if (null === t) {var a = r.length;a > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(a / 2) - 5, 10) + r.substr(-10, 10))} else {for (var C = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), h = 0, f = C.length, u = []; f > h; h++)"" !== C[h] && u.push.apply(u, e(C[h].split(""))),h !== f - 1 && u.push(t[h]);var g = u.length;g > 30 && (r = u.slice(0, 10).join("") + u.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + u.slice(-10).join(""))}var l = void 0, d = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);// l = null !== i ? i : (i = o.common[d] || "") || "";l = "320305.131321201";for (var m = l.split("."), S = Number(m[0]) || 0, s = Number(m[1]) || 0, c = [], v = 0, F = 0; F < r.length; F++) {var p = r.charCodeAt(F);128 > p ? c[v++] = p : (2048 > p ? c[v++] = p >> 6 | 192 : (55296 === (64512 & p) && F + 1 < r.length && 56320 === (64512 & r.charCodeAt(F + 1)) ? (p = 65536 + ((1023 & p) << 10) + (1023 & r.charCodeAt(++F)),c[v++] = p >> 18 | 240,c[v++] = p >> 12 & 63 | 128) : c[v++] = p >> 12 | 224,c[v++] = p >> 6 & 63 | 128),c[v++] = 63 & p | 128)}for (var w = S, A = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), b = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), D = 0; D < c.length; D++)w += c[D], w = n(w, A);return w = n(w, b),w ^= s,0 > w && (w = (2147483647 & w) + 2147483648),w %= 1e6,w.toString() + "." + (w ^ S)}console.log(sign('king'))
执行结果:

也可以直接在 Chrome 上的 console 中执行 js

Python 直接调用 JS 代码( js_code = r”””js代码””” 中 r 不能少 )
// l = null !== i ? i : (i = o.common[d] || “”) || “”; // l 的值 等于 gkt,通过调试可知,这是个固定值
l = “320305.131321201”; // 直接 令 l = “320305.131321201”;
# @Author : 佛祖保佑, 永无 bug# @Date :# @File : translate_baidu.py# @Software: PyCharm# @description : XXXimport execjsimport requestsjs_code = r"""function n(r, o) {for (var t = 0; t < o.length - 2; t += 3) {var e = o.charAt(t + 2);e = e >= "a" ? e.charCodeAt(0) - 87 : Number(e),e = "+" === o.charAt(t + 1) ? r >>> e : r << e,r = "+" === o.charAt(t) ? r + e & 4294967295 : r ^ e}return r}function sign(r) {var t = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);if (null === t) {var a = r.length;a > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(a / 2) - 5, 10) + r.substr(-10, 10))} else {for (var C = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), h = 0, f = C.length, u = []; f > h; h++)"" !== C[h] && u.push.apply(u, e(C[h].split(""))),h !== f - 1 && u.push(t[h]);var g = u.length;g > 30 && (r = u.slice(0, 10).join("") + u.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + u.slice(-10).join(""))}var l = void 0, d = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);// l = null !== i ? i : (i = o.common[d] || "") || "";l = "320305.131321201";for (var m = l.split("."), S = Number(m[0]) || 0, s = Number(m[1]) || 0, c = [], v = 0, F = 0; F < r.length; F++) {var p = r.charCodeAt(F);128 > p ? c[v++] = p : (2048 > p ? c[v++] = p >> 6 | 192 : (55296 === (64512 & p) && F + 1 < r.length && 56320 === (64512 & r.charCodeAt(F + 1)) ? (p = 65536 + ((1023 & p) << 10) + (1023 & r.charCodeAt(++F)),c[v++] = p >> 18 | 240,c[v++] = p >> 12 & 63 | 128) : c[v++] = p >> 12 | 224,c[v++] = p >> 6 & 63 | 128),c[v++] = 63 & p | 128)}for (var w = S, A = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), b = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), D = 0; D < c.length; D++)w += c[D], w = n(w, A);return w = n(w, b),w ^= s,0 > w && (w = (2147483647 & w) + 2147483648),w %= 1e6,w.toString() + "." + (w ^ S)}console.log(sign('king'))"""js_func = execjs.compile(js_code)def test(kw=None):url = "https://fanyi.baidu.com/basetrans"sign = js_func.call('sign', kw)payload = f"query={kw}&from=en&to=zh&token=94c55bca8b920035077b58d58ba32bea&sign={sign}"headers = {'Content-Type': 'application/x-www-form-urlencoded','Cookie': 'BAIDUID=AF87393A8DB7C8FED7859A909FF081A3:SL=0:NR=50:FG=1;','User-Agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) ''AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36'}response = requests.request("POST", url, headers=headers, data=payload)# print(response.text)print(response.json()['trans'][0]['dst'])if __name__ == '__main__':kw_list = ['hello baby', 'I love u','king']for item in kw_list:test(kw=item)pass
执行结果:

有道 翻译
参考:爬虫破解js加密破解(二) 有道词典js加密参数 sign破解 - 淋哥 - 博客园
JS逆向 —— 百度翻译参数(sign)爬虫 超级详细:【2019.05】JS逆向——破解百度翻译参数(sign)爬虫 超级详细_ybsde博客-CSDN博客_js逆向
Python 执行 js 代码
关于 Python 执行 js 代码
- 通过 python 模块 execjs 来解析 js 文件 (安装: pip install PyExecJS)
- python 调用 node.js(需要先安装 node.js)
- 使用 PyV8 在 Python 爬虫中执行 js 代码:python pyv8_百度搜索
- 使用 浏览器( selenium、PhantomJS) 执行 js:网络爬虫之记一次js逆向解密经历 - 奥辰 - 博客园
PyV8、PyExecJS、js2py 区别:PyV8、PyExecJS、js2py区别 - 简书
PyV8 github 地址:https://github.com/emmetio/pyv8-binaries
Python 使用 execjs 示例:
python 的 execjs 只支持一些常规的 js 代码 :python 使用execjs执行接js解密时报错execjs UnicodeDecodeError: ‘gbk’ codec can’t decode byte_zhaojiafu的博客-CSDN博客
import execjsjs_str = '''function add(x, y){return x + y;}'''test = execjs.compile(js_str)# call 即调用js函数,add 为 js_str 中的函数名,1,2 为所需要的参数。result = test.call('add', 1, 2)print(result)
有道词典 js 加密参数 sign破解
分析:

然后转到 Headers,查看 请求体,可以看到有请求验证字段,如:salt,sign 等 :

Ctrl + Shift + F : 全局搜索 sign 这个关键字,搜索所有 包含 sign 的 js 文件,发现只搜索出一个,双击这个 js 文件:

在 js 文件内容中 搜索 sign ,分析 sign 怎么产生的:

提取 js 的 加密函数( 这里是 md5 );
通过 js 调试,可以找到 md5 函数:

把 md5 函数提取出来,放到一个单独的 js 文件里面,然后,再通过 js调试 把 md5 函数所依赖的 js 函数全部 提取出来。
目录结构:
提取 的 所有 js 函数如下( yd_js.js):
function n(e, t) {return e << t | e >>> 32 - t}function r(e, t) {var n, r, i, o, a;return i = 2147483648 & e,o = 2147483648 & t,n = 1073741824 & e,r = 1073741824 & t,a = (1073741823 & e) + (1073741823 & t),n & r ? 2147483648 ^ a ^ i ^ o : n | r ? 1073741824 & a ? 3221225472 ^ a ^ i ^ o : 1073741824 ^ a ^ i ^ o : a ^ i ^ o}function i(e, t, n) {return e & t | ~e & n}function o(e, t, n) {return e & n | t & ~n}function a(e, t, n) {return e ^ t ^ n}function s(e, t, n) {return t ^ (e | ~n)}function l(e, t, o, a, s, l, c) {return e = r(e, r(r(i(t, o, a), s), c)),r(n(e, l), t)}function c(e, t, i, a, s, l, c) {return e = r(e, r(r(o(t, i, a), s), c)),r(n(e, l), t)}function u(e, t, i, o, s, l, c) {return e = r(e, r(r(a(t, i, o), s), c)),r(n(e, l), t)}function f(e, t, i, o, a, l, c) {return e = r(e, r(r(s(t, i, o), a), c)),r(n(e, l), t)}function d(e) {for (var t, n = e.length, r = n + 8, i = 16 * ((r - r % 64) / 64 + 1), o = Array(i - 1), a = 0, s = 0; s < n;)a = s % 4 * 8,o[t = (s - s % 4) / 4] = o[t] | e.charCodeAt(s) << a,s++;return t = (s - s % 4) / 4,a = s % 4 * 8,o[t] = o[t] | 128 << a,o[i - 2] = n << 3,o[i - 1] = n >>> 29,o}function p(e) {var t, n = "", r = "";for (t = 0; t <= 3; t++)n += (r = "0" + (e >>> 8 * t & 255).toString(16)).substr(r.length - 2, 2);return n}function h(e) {e = e.replace(/\x0d\x0a/g, "\n");for (var t = "", n = 0; n < e.length; n++) {var r = e.charCodeAt(n);if (r < 128)t += String.fromCharCode(r);else if (r > 127 && r < 2048)t += String.fromCharCode(r >> 6 | 192),t += String.fromCharCode(63 & r | 128);else if (r >= 55296 && r <= 56319) {if (n + 1 < e.length) {var i = e.charCodeAt(n + 1);if (i >= 56320 && i <= 57343) {var o = 1024 * (r - 55296) + (i - 56320) + 65536;t += String.fromCharCode(240 | o >> 18 & 7),t += String.fromCharCode(128 | o >> 12 & 63),t += String.fromCharCode(128 | o >> 6 & 63),t += String.fromCharCode(128 | 63 & o),n++}}} elset += String.fromCharCode(r >> 12 | 224),t += String.fromCharCode(r >> 6 & 63 | 128),t += String.fromCharCode(63 & r | 128)}return t;}function md5(e) {var t, n, i, o, a, s, m, g, v, y = Array();for (e = h(e),y = d(e),s = 1732584193,m = 4023233417,g = 2562383102,v = 271733878,t = 0; t < y.length; t += 16)n = s,i = m,o = g,a = v,s = l(s, m, g, v, y[t + 0], 7, 3614090360),v = l(v, s, m, g, y[t + 1], 12, 3905402710),g = l(g, v, s, m, y[t + 2], 17, 606105819),m = l(m, g, v, s, y[t + 3], 22, 3250441966),s = l(s, m, g, v, y[t + 4], 7, 4118548399),v = l(v, s, m, g, y[t + 5], 12, 1200080426),g = l(g, v, s, m, y[t + 6], 17, 2821735955),m = l(m, g, v, s, y[t + 7], 22, 4249261313),s = l(s, m, g, v, y[t + 8], 7, 1770035416),v = l(v, s, m, g, y[t + 9], 12, 2336552879),g = l(g, v, s, m, y[t + 10], 17, 4294925233),m = l(m, g, v, s, y[t + 11], 22, 2304563134),s = l(s, m, g, v, y[t + 12], 7, 1804603682),v = l(v, s, m, g, y[t + 13], 12, 4254626195),g = l(g, v, s, m, y[t + 14], 17, 2792965006),m = l(m, g, v, s, y[t + 15], 22, 1236535329),s = c(s, m, g, v, y[t + 1], 5, 4129170786),v = c(v, s, m, g, y[t + 6], 9, 3225465664),g = c(g, v, s, m, y[t + 11], 14, 643717713),m = c(m, g, v, s, y[t + 0], 20, 3921069994),s = c(s, m, g, v, y[t + 5], 5, 3593408605),v = c(v, s, m, g, y[t + 10], 9, 38016083),g = c(g, v, s, m, y[t + 15], 14, 3634488961),m = c(m, g, v, s, y[t + 4], 20, 3889429448),s = c(s, m, g, v, y[t + 9], 5, 568446438),v = c(v, s, m, g, y[t + 14], 9, 3275163606),g = c(g, v, s, m, y[t + 3], 14, 4107603335),m = c(m, g, v, s, y[t + 8], 20, 1163531501),s = c(s, m, g, v, y[t + 13], 5, 2850285829),v = c(v, s, m, g, y[t + 2], 9, 4243563512),g = c(g, v, s, m, y[t + 7], 14, 1735328473),m = c(m, g, v, s, y[t + 12], 20, 2368359562),s = u(s, m, g, v, y[t + 5], 4, 4294588738),v = u(v, s, m, g, y[t + 8], 11, 2272392833),g = u(g, v, s, m, y[t + 11], 16, 1839030562),m = u(m, g, v, s, y[t + 14], 23, 4259657740),s = u(s, m, g, v, y[t + 1], 4, 2763975236),v = u(v, s, m, g, y[t + 4], 11, 1272893353),g = u(g, v, s, m, y[t + 7], 16, 4139469664),m = u(m, g, v, s, y[t + 10], 23, 3200236656),s = u(s, m, g, v, y[t + 13], 4, 681279174),v = u(v, s, m, g, y[t + 0], 11, 3936430074),g = u(g, v, s, m, y[t + 3], 16, 3572445317),m = u(m, g, v, s, y[t + 6], 23, 76029189),s = u(s, m, g, v, y[t + 9], 4, 3654602809),v = u(v, s, m, g, y[t + 12], 11, 3873151461),g = u(g, v, s, m, y[t + 15], 16, 530742520),m = u(m, g, v, s, y[t + 2], 23, 3299628645),s = f(s, m, g, v, y[t + 0], 6, 4096336452),v = f(v, s, m, g, y[t + 7], 10, 1126891415),g = f(g, v, s, m, y[t + 14], 15, 2878612391),m = f(m, g, v, s, y[t + 5], 21, 4237533241),s = f(s, m, g, v, y[t + 12], 6, 1700485571),v = f(v, s, m, g, y[t + 3], 10, 2399980690),g = f(g, v, s, m, y[t + 10], 15, 4293915773),m = f(m, g, v, s, y[t + 1], 21, 2240044497),s = f(s, m, g, v, y[t + 8], 6, 1873313359),v = f(v, s, m, g, y[t + 15], 10, 4264355552),g = f(g, v, s, m, y[t + 6], 15, 2734768916),m = f(m, g, v, s, y[t + 13], 21, 1309151649),s = f(s, m, g, v, y[t + 4], 6, 4149444226),v = f(v, s, m, g, y[t + 11], 10, 3174756917),g = f(g, v, s, m, y[t + 2], 15, 718787259),m = f(m, g, v, s, y[t + 9], 21, 3951481745),s = r(s, n),m = r(m, i),g = r(g, o),v = r(v, a);return (p(s) + p(m) + p(g) + p(v)).toLowerCase()}// t = (new Date).getTime() + parseInt(10 * Math.random(), 10);// console.log((new Date).getTime());// console.log(t);
python 代码 ( yd.py ):
import execjsimport timeimport randomimport requestsimport json"""通过在js文件中查找salt或者sign,可以找到1.可以找到这个计算salt的公式r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))2.sign:n.md5("fanyideskweb" + t + r + "p09@Bn{h02_BIEe]$P^nG");md5 一共需要四个参数,第一个和第四个都是固定值得字符串,第三个是所谓的salt,第二个参数是输入的需要翻译的单词"""def get_md5(v):# 读取js文件with open('yd_js.js', encoding='utf-8') as f:js = f.read()# 通过compile命令转成一个js对象js_obj = execjs.compile(js)res = js_obj.call('md5', v)return resdef get_sign(key, salt):sign = "fanyideskweb" + str(key) + str(salt) + "n%A-rKaT5fb[Gy?;N5@Tj"sign = get_md5(sign)return signdef you_dao(key):url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"ts = str(int((time.time() * 1000)))salt = str(ts) + str(random.randint(0, 10))data = {"i": key,"from": "AUTO","to": "AUTO","smartresult": "dict","client": "fanyideskweb","salt": str(salt),"sign": get_sign(key, salt),"ts": ts,"bv": "5872543b025b19167cde3785ecf1e925","doctype": "json","version": "2.1","keyfrom": "fanyi.web","action": "FY_BY_REALTIME","typoResult": "false",}headers = {"Host": "fanyi.youdao.com",# "Proxy-Connection":"keep-alive","Content-Length": str(len(data)),"Accept": "application/json, text/javascript, */*; q=0.01","Origin": "http://fanyi.youdao.com","X-Requested-With": "XMLHttpRequest","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/75.0.3770.90 Safari/537.36","Content-Type": "application/x-www-form-urlencoded; charset=UTF-8","Referer": "http://fanyi.youdao.com/","Accept-Encoding": "gzip, deflate","Accept-Language": "zh-CN,zh;q=0.9","Cookie": "OUTFOX_SEARCH_USER_ID=-803834638@61.149.7.46; ""JSESSIONID=aaa2KqSwX9shJdA5Mk9Ww; OUTFOX_SEARCH_USER_ID_NCOO=1481235354.231604; ""___rl__test__cookies=1564486753731",}r = requests.post(url=url, data=data, headers=headers)if r.status_code == 200:data = json.loads(r.text)src = data.get('translateResult')[0][0]['src']tgt = data.get('translateResult')[0][0]['tgt']print(f'翻译前 :{src}')print(f'翻译后 :{tgt}')else:print(f'请求失败 status code {r.status_code}')if __name__ == '__main__':you_dao("hello, baby")you_dao("I love you")you_dao("thank you very much")you_dao("天王盖地虎,宝塔镇河妖")
运行结果截图:

百度指数 js 破解
分析过程参考:爬虫之js加密参数破解练习-百度指数爬虫(附完整源码)_wang785994599的博客-CSDN博客_百度指数加密
Python爬虫 - 简单抓取百度指数:Python爬虫 - 简单抓取百度指数 - 知乎
Python 代码实现( 直接从浏览器拿到登录后的Cookie复制粘贴到代码中 ):
# -*- coding: utf-8 -*-import requestsimport execjsimport urllib3# 禁用警告urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)js_string = '''function decrypt(t, e) {for (var n = t.split(""), i = e.split(""), a = {}, r = [], o = 0; o < n.length / 2; o++)a[n[o]] = n[n.length / 2 + o];for (var s = 0; s < e.length; s++)r.push(a[i[s]]);return r.join("")}'''headers = {"Cookie": "直接从浏览器拿到登录后的Cookie复制粘贴","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/75.0.3770.142 Safari/537.36"}data_url = 'https://index.baidu.com/api/SearchApi/index?word={}&area=0&days=7'uniq_id_url = 'https://index.baidu.com/Interface/ptbk?uniqid={}'keys = ["all", "pc", "wise"]class BDIndex(object):def __init__(self):self.session = self.get_session()pass@staticmethoddef get_session():"""初始化 session 会话:return:"""session = requests.session()session.headers = headerssession.verify = Falsereturn session@staticmethoddef decrypt(key, data):"""得到解密后的数据:param key: key:param data: key 对应的 value:return:"""js_handler = execjs.compile(js_string)return js_handler.call('decrypt', key, data)def get_bd_index(self, key_word):"""得到百度指数:param key_word::return:"""response = self.session.get(data_url.format(key_word)).json()uniq_id = self.session.get(uniq_id_url.format(response.get("data").get("uniqid"))).json().get("data")result = []data_dict = response.get("data").get("userIndexes")[0]for key in keys:decrypt_data = self.decrypt(uniq_id, data_dict.get(key).get("data"))result.append({key: decrypt_data})return resultif __name__ == '__main__':bd = BDIndex()d = bd.get_bd_index("杨幂")print(d)
运行结果:





























还没有评论,来说两句吧...