误差反向传播(手把手教你推导如何通过反向传播更新参数)
在讲解误差反向传播之前我们 先来了解下基本概念,顺着我的思路下去,后面的推导你就可能不会糊涂。
【一些基础概念】
误差反向传播(Error Back Propagation, BP)算法
1、BP算法的基本思想是:学习过程由信号的正向传播与误差的反向传播两个过程组成。
1)正向传播:输入样本->输入层->隐藏层(处理)->输出层
举一个正向传播的例子,如下所示:

我们通过单个的神经元来观察下输入数据从输入到输出需要经历哪些步骤:
第一步:每个输入都跟一个权重相乘(红色)

第二步:加权后的输入求和,加上一个偏差b(绿色)

第三步:这个结果传递给一个激活函数f(x)
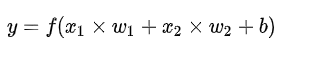
激活函数的作用是将一个无边界的输入,转变成一个可预测的形式。常用的激活函数就就是S型函数,如下所示:
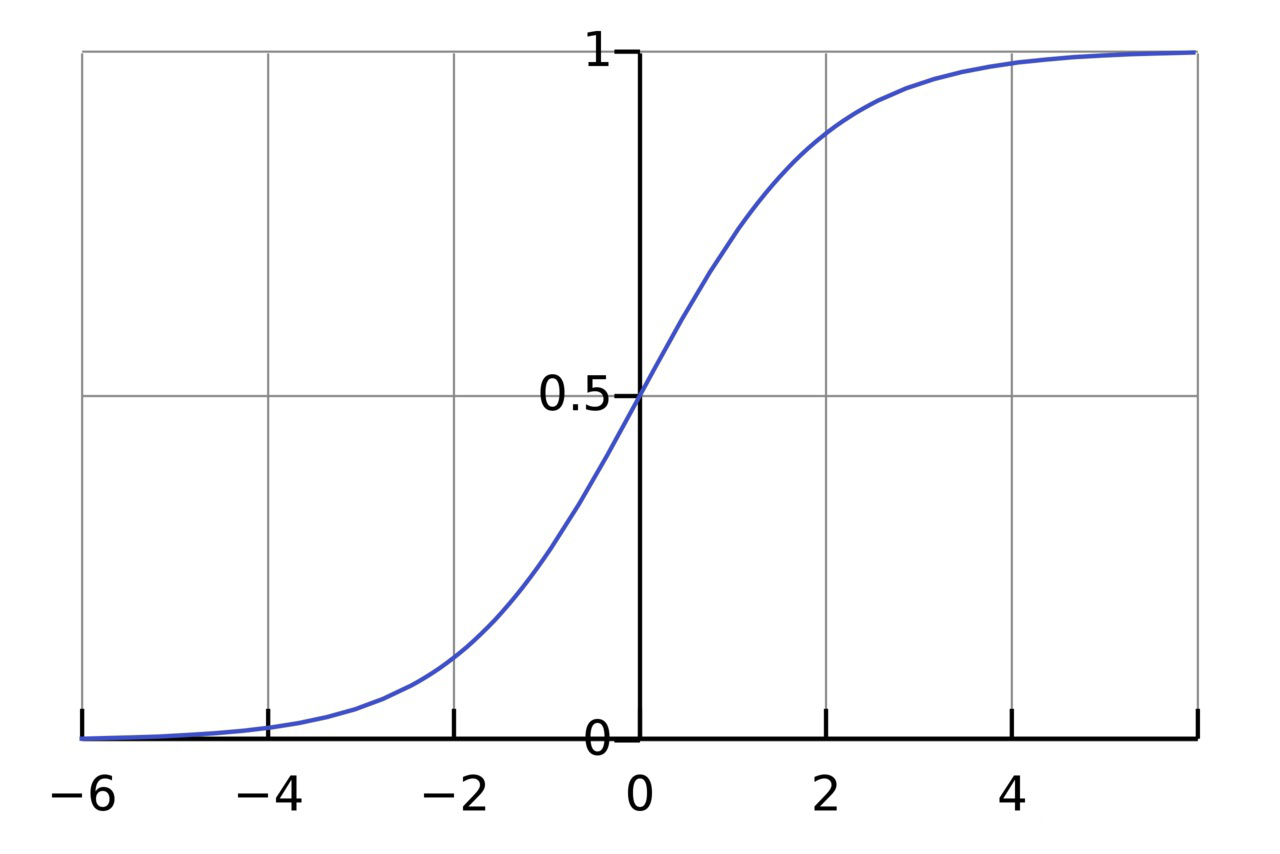
S型函数的值域是(0, 1)。简单来说,就是把(−∞, +∞)压缩到(0, 1) ,很大的负数约等于0,很大的正数约等于1。
这里我们为上面的变量赋值,然后通过正向传播得到一个结果如下所示:

上面通过单个神经元来讲解的,那如果我有一个简单的神经网络该怎么正向传播,做法跟上面是一样的,比如下面的这个简单的神经网络:
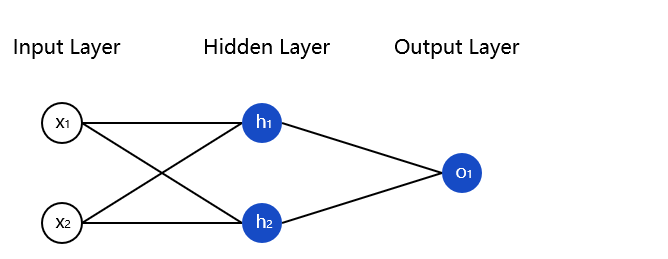
我们就使用上图所示的神经网络,并假设所有神经元的权重都为[0,1],偏置都为0,激活都使用Sigmoid函数。
我们将这些数字标记在神经网络上,如下所示:
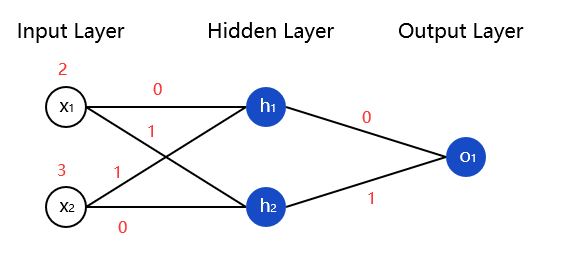
通过上面的计算,输出的过程就为:
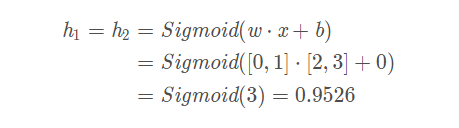

因为上面的神经网络相对简单所以计算步骤没有那么繁琐,对于一些神经元较多的神经网络我们的计算方式也是这样的。
我们通过正向传播计算出来的结果一般都需要经过损失函数来衡量,如果损失函数的值较大(也就是说实际值与预测值之差),那说明我们预测的结果往往不理想,为了解决这个问题,我们需要选择一种方法来量化神经网络预测得有多“好”,在这里我们使用的是均方误差(MSE)损失:
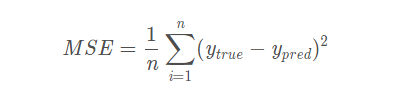
- n 是样本数量
- y 是目标量
 是真实的结果(正确答案)
是真实的结果(正确答案) 是预测的结果,就是神经网络输出的结果。
是预测的结果,就是神经网络输出的结果。
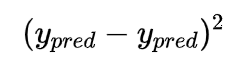 被称作方差(平方误差),我们这里的损失函数只是取所有方差的平均值(故名“均方差”“mean squared error”)。预测效果越好,损失函数的值就会越低。
被称作方差(平方误差),我们这里的损失函数只是取所有方差的平均值(故名“均方差”“mean squared error”)。预测效果越好,损失函数的值就会越低。
为了最小化损失值,接下来就要引入我们的反向传播通过改变神经网络的权重和偏置来影响它的预测结果。
2)误差反向传播:输出误差(某种形式)->隐层(逐层)->输入层
其主要目的是通过将输出误差反传,将误差分摊给各层所有单元,从而获得各层单元的误差信号,进而修正各单元的权值(其过
程,是一个权值调整的过程)。
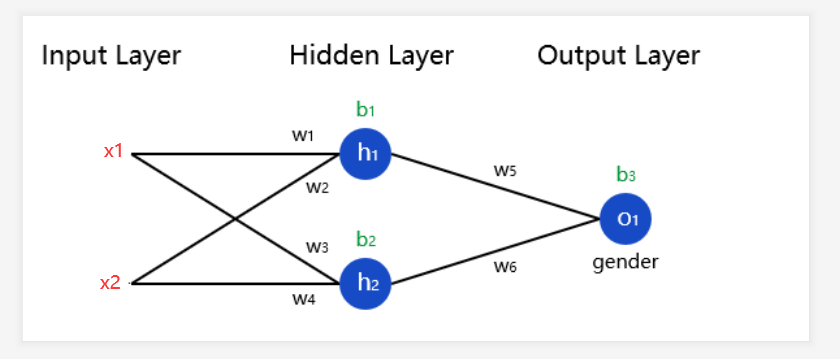
接下来我们通过上面这张图来通过反向传播进行参数的更新,但是我们第一步需要先通过正向传播来计算每个神经元里面的值。
我们先算h1和h2这两个神经元:
sum_h1 = x1*w1 + x2*w2 + b1 h1 = Sigmoid(sum_h1)
sum_h2 = x2*w4 + x2*w2 + b2 h2 = Sigmoid(sum_h2)
PS:通过激活函数求得的h1相当于输入的x1,,然后参与下一个神经元的运算
接下来再算O1这个神经元:
sum_O1 = h1*w5 + h2*w6 + b3 O1 = Sigmoid(sum_O1)
要更新神经元上相关的参数,那么我们需要使用链式法则来进行求解
这里补充下因为我们使用的是Sigmoid函数: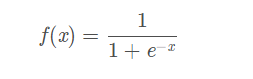
那么对f(x)求导之后f`(x) = f(x)( 1 - f(x) ),所以我在这里令Sigmoid求导后的函数为:deriv_sigmoid(x)
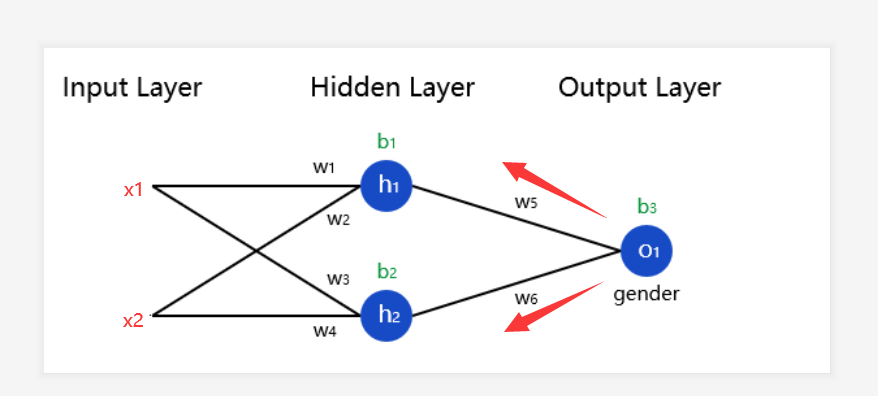
接下来我们通过从神经元O1开始对h1、h2、w5、w6、b3求梯度:
用数学知识看这个式子:sum_O1 = h1*w5 + h2*w6 + b3 然后分别求梯度,对应下面的式子
d_h1 = w5*deriv_sigmoid(sum_O1)
d_h2 = w6*deriv_sigmoid(sum_O1)
d_w5 = h1*deriv_sigmoid(sum_O1)
d_w6 = h2*deriv_sigmoid(sum_O1)
d_b3 = deriv_sigmoid(sum_O1)
接下来我们继续反向对w1、w2、w3、w4、b1、b2求梯度
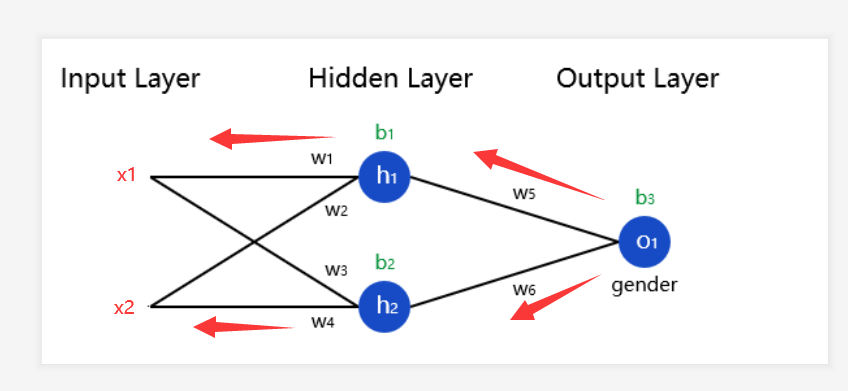
同样的,用数学知识看这个式子:sum_h1 = x1*w1 + x2*w2 + b1 sum_h2 = x1*w3 + x2*w4 + b2
分别求梯度,对应下面的式子
d_h1_w1 = x1*deriv_sigmoid(sum_h1)
d_h1_w2 = x2*deriv_sigmoid(sum_h1)
d_h2_w3= x1*deriv_sigmoid(sum_h2)
d_h2_w4 = x2*deriv_sigmoid(sum_h2)
d_h1_b1 = deriv_sigmoid(sum_h1)
d_h2_b2 = deriv_sigmoid(sum_h2)
至此,我们将上面的一些参数的梯度求解完成了,接下来我们需要做的就是对每个参数通过链式法则求偏导

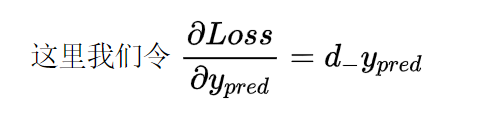
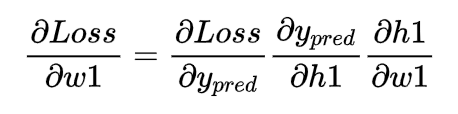
通过上面我们所求的梯度我们知道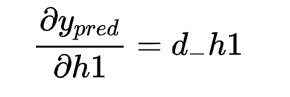
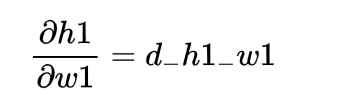
那么我们就可以得到:
然后我们将上面对应的梯度带入进去就可以求得相应的偏导
下面我们就需要去更新这些参数了,怎么更新,通过下面这个式子:

其中lr代表的是学习率,这里我们就以w1为例进行参数的更新:

同理,对于其他的参数更新我们也可以使用上面一样的方法去求解。
当然了,这里我们给出的是一次参数的更新,如果是n次的话也是这个原理,求到最后参数的值也是在不断的减小,最终求得损失函数最小化的参数就停止反向传播。
文章有写的不好的地方请多多指正。
【相关参考】
1.https://blog.csdn.net/loopy_/article/details/89742157
2.https://www.pianshen.com/article/19911551579/


























:数组排序算法")

")





还没有评论,来说两句吧...