分布式id解决方案
分布式高效ID生产黑科技(sequence)
开源产品介绍(微服务基础设施)
- 微服务神经元(neural)
- GITHUB:https://github.com/yu120/neural
- 码云:https://git.oschina.net/yu120/neural
简介
高效GUID产生算法(sequence),基于Snowflake实现64位自增ID算法。新增特性:
- 支持自定义允许时间回拨的范围
- 解决跨毫秒起始值每次为0开始的情况(避免末尾必定为偶数,而不便于取余使用问题)
- 解决高并发场景中获取时间戳性能问题
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
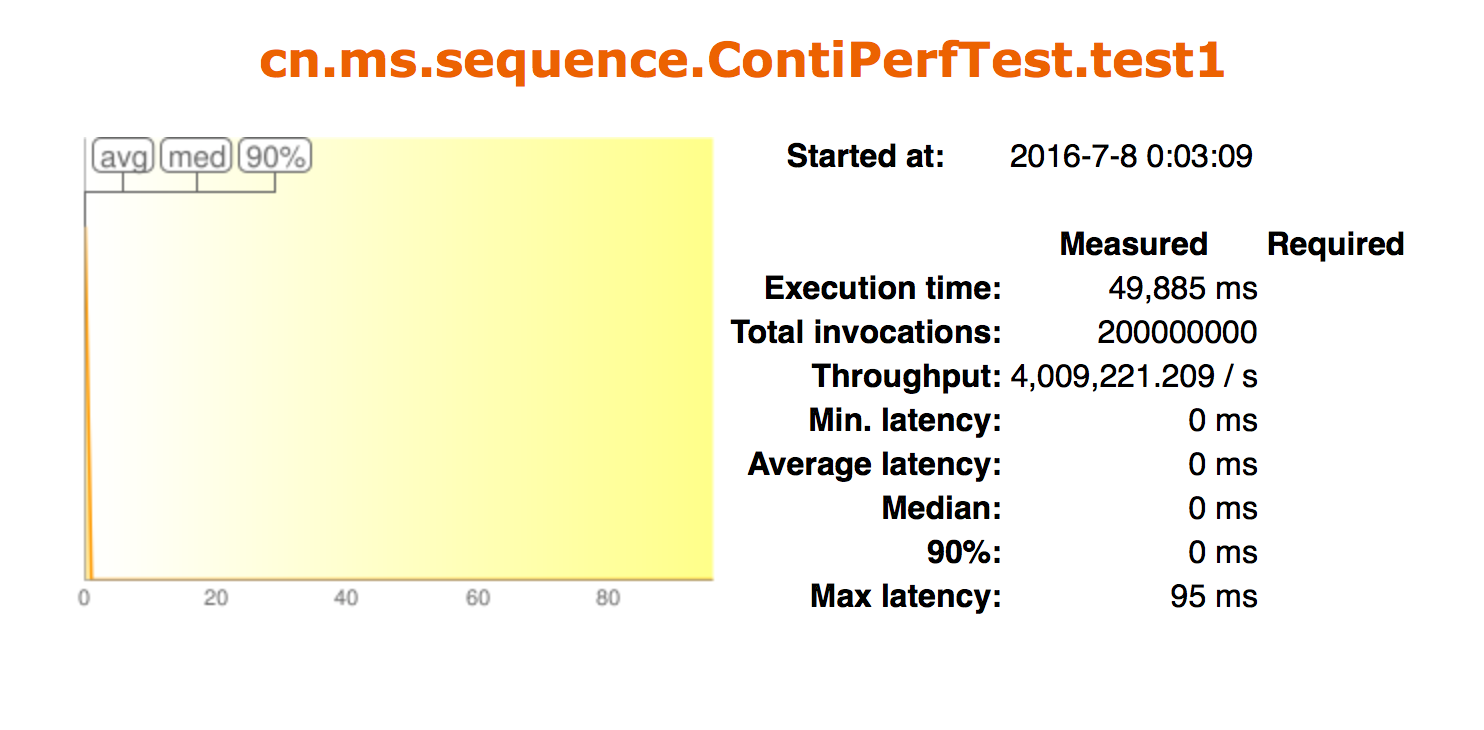
性能测试数据:

Snowflake算法核心
把时间戳,工作机器id,序列号组合在一起。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nqd8tHeC-1598942097759)(docs/snowflake-64bit.jpg)]
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。下文会具体分析。
Snowflake – 时间戳
这里时间戳的细度是毫秒级,具体代码如下,建议使用64位linux系统机器,因为有vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。
Snowflake – 工作机器id
严格意义上来说这个bit段的使用可以是进程级,机器级的话你可以使用MAC地址来唯一标示工作机器,工作进程级可以使用IP+Path来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。
Snowflake – 序列号
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
实现:
package com.mtons.mblog.modules.id;import java.net.InetAddress;import java.util.concurrent.ThreadLocalRandom;/** * 基于Twitter的Snowflake算法实现分布式高效有序ID生产黑科技(sequence)——升级版Snowflake * * <br> * SnowFlake的结构如下(每部分用-分开):<br> * <br> * 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br> * <br> * 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br> * <br> * 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截) * 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下START_TIME属性)。41位的时间截,可以使用69年,年 * T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br> * <br> * 10位的数据机器位,可以部署在1024个节点,包括5位dataCenterId和5位workerId<br> * <br> * 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br> * <br> * <br> * 加起来刚好64位,为一个Long型。<br> * SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。 * <p> * <p> * 特性: * 1.支持自定义允许时间回拨的范围<p> * 2.解决跨毫秒起始值每次为0开始的情况(避免末尾必定为偶数,而不便于取余使用问题)<p> * 3.解决高并发场景中获取时间戳性能问题<p> * 4.支撑根据IP末尾数据作为workerId * 5.时间回拨方案思考:1024个节点中分配10个点作为时间回拨序号(连续10次时间回拨的概率较小) * * @author lry * @version 3.0 */public final class Sequence {/** * 起始时间戳 **/private final static long START_TIME = 1519740777809L;/** * dataCenterId占用的位数:2 **/private final static long DATA_CENTER_ID_BITS = 2L;/** * workerId占用的位数:8 **/private final static long WORKER_ID_BITS = 8L;/** * 序列号占用的位数:12(表示只允许workId的范围为:0-4095) **/private final static long SEQUENCE_BITS = 12L;/** * workerId可以使用范围:0-255 **/private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);/** * dataCenterId可以使用范围:0-3 **/private final static long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);private final static long WORKER_ID_SHIFT = SEQUENCE_BITS;private final static long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;private final static long TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;/** * 用mask防止溢出:位与运算保证计算的结果范围始终是 0-4095 **/private final static long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);private final long workerId;private final long dataCenterId;private long sequence = 0L;private long lastTimestamp = -1L;private static byte LAST_IP = 0;private final boolean clock;private final long timeOffset;private final boolean randomSequence;private final ThreadLocalRandom tlr = ThreadLocalRandom.current();public Sequence(long dataCenterId) {this(dataCenterId, 0x000000FF & getLastIPAddress(), false, 5L, false);}public Sequence(long dataCenterId, boolean clock, boolean randomSequence) {this(dataCenterId, 0x000000FF & getLastIPAddress(), clock, 5L, randomSequence);}/** * 基于Snowflake创建分布式ID生成器 * * @param dataCenterId 数据中心ID,数据范围为0~255 * @param workerId 工作机器ID,数据范围为0~3 * @param clock true表示解决高并发下获取时间戳的性能问题 * @param timeOffset 允许时间回拨的毫秒量,建议5ms * @param randomSequence true表示使用毫秒内的随机序列(超过范围则取余) */public Sequence(long dataCenterId, long workerId, boolean clock, long timeOffset, boolean randomSequence) {if (dataCenterId > MAX_DATA_CENTER_ID || dataCenterId < 0) {throw new IllegalArgumentException("Data Center Id can't be greater than " + MAX_DATA_CENTER_ID + " or less than 0");}if (workerId > MAX_WORKER_ID || workerId < 0) {throw new IllegalArgumentException("Worker Id can't be greater than " + MAX_WORKER_ID + " or less than 0");}this.workerId = workerId;this.dataCenterId = dataCenterId;this.clock = clock;this.timeOffset = timeOffset;this.randomSequence = randomSequence;}/** * 获取ID * * @return long */public synchronized Long nextId() {long currentTimestamp = this.timeGen();// 闰秒:如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,这个时候应当抛出异常if (currentTimestamp < lastTimestamp) {// 校验时间偏移回拨量long offset = lastTimestamp - currentTimestamp;if (offset > timeOffset) {throw new RuntimeException("Clock moved backwards, refusing to generate id for [" + offset + "ms]");}try {// 时间回退timeOffset毫秒内,则允许等待2倍的偏移量后重新获取,解决小范围的时间回拨问题this.wait(offset << 1);} catch (Exception e) {throw new RuntimeException(e);}// 再次获取currentTimestamp = this.timeGen();// 再次校验if (currentTimestamp < lastTimestamp) {throw new RuntimeException("Clock moved backwards, refusing to generate id for [" + offset + "ms]");}}// 同一毫秒内序列直接自增if (lastTimestamp == currentTimestamp) {// randomSequence为true表示随机生成允许范围内的序列起始值并取余数,否则毫秒内起始值为0L开始自增long tempSequence = sequence + 1;if (randomSequence && tempSequence > SEQUENCE_MASK) {tempSequence = tempSequence % SEQUENCE_MASK;}// 通过位与运算保证计算的结果范围始终是 0-4095sequence = tempSequence & SEQUENCE_MASK;if (sequence == 0) {currentTimestamp = this.tilNextMillis(lastTimestamp);}} else {// randomSequence为true表示随机生成允许范围内的序列起始值,否则毫秒内起始值为0L开始自增sequence = randomSequence ? tlr.nextLong(SEQUENCE_MASK + 1) : 0L;}lastTimestamp = currentTimestamp;long currentOffsetTime = currentTimestamp - START_TIME;/* * 1.左移运算是为了将数值移动到对应的段(41、5、5,12那段因为本来就在最右,因此不用左移) * 2.然后对每个左移后的值(la、lb、lc、sequence)做位或运算,是为了把各个短的数据合并起来,合并成一个二进制数 * 3.最后转换成10进制,就是最终生成的id */return (currentOffsetTime << TIMESTAMP_LEFT_SHIFT) |// 数据中心位(dataCenterId << DATA_CENTER_ID_SHIFT) |// 工作ID位(workerId << WORKER_ID_SHIFT) |// 毫秒序列化位sequence;}/** * 保证返回的毫秒数在参数之后(阻塞到下一个毫秒,直到获得新的时间戳)——CAS * * @param lastTimestamp last timestamp * @return next millis */private long tilNextMillis(long lastTimestamp) {long timestamp = this.timeGen();while (timestamp <= lastTimestamp) {// 如果发现时间回拨,则自动重新获取(可能会处于无限循环中)timestamp = this.timeGen();}return timestamp;}/** * 获得系统当前毫秒时间戳 * * @return timestamp 毫秒时间戳 */private long timeGen() {return clock ? SystemClock.INSTANCE.currentTimeMillis() : System.currentTimeMillis();}/** * 用IP地址最后几个字节标示 * <p> * eg:192.168.1.30->30 * * @return last IP */public static byte getLastIPAddress() {if (LAST_IP != 0) {return LAST_IP;}try {InetAddress inetAddress = InetAddress.getLocalHost();byte[] addressByte = inetAddress.getAddress();LAST_IP = addressByte[addressByte.length - 1];} catch (Exception e) {throw new RuntimeException("Unknown Host Exception", e);}return LAST_IP;}}package com.mtons.mblog.modules.id;import java.sql.Timestamp;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.ScheduledThreadPoolExecutor;import java.util.concurrent.TimeUnit;import java.util.concurrent.atomic.AtomicLong;/** * System Clock * <p> * 利用ScheduledExecutorService实现高并发场景下System.curentTimeMillis()的性能问题的优化. * * @author lry */public enum SystemClock {// ====INSTANCE(1);private final long period;private final AtomicLong nowTime;private boolean started = false;private ScheduledExecutorService executorService;SystemClock(long period) {this.period = period;this.nowTime = new AtomicLong(System.currentTimeMillis());}/** * The initialize scheduled executor service */public void initialize() {if (started) {return;}this.executorService = new ScheduledThreadPoolExecutor(1, r -> {Thread thread = new Thread(r, "system-clock");thread.setDaemon(true);return thread;});executorService.scheduleAtFixedRate(() -> nowTime.set(System.currentTimeMillis()),this.period, this.period, TimeUnit.MILLISECONDS);Runtime.getRuntime().addShutdownHook(new Thread(this::destroy));started = true;}/** * The get current time milliseconds * * @return long time */public long currentTimeMillis() {return started ? nowTime.get() : System.currentTimeMillis();}/** * The get string current time * * @return string time */public String currentTime() {return new Timestamp(currentTimeMillis()).toString();}/** * The destroy of executor service */public void destroy() {if (executorService != null) {executorService.shutdown();}}}
调用:
package cn.ms.sequence;import org.junit.Test;public class SequenceTest1 {@Testpublic void name() {try {int times = 0, maxTimes = 1000;Sequence sequence = new Sequence(0);for (int i = 0; i < maxTimes; i++) {long id = sequence.nextId();System.out.println("生成的分布式id :" + id);if(id%2==0){times++;}Thread.sleep(10);}System.out.println("偶数:" + times + ",奇数:" + (maxTimes - times) + "!");} catch (Exception e) {e.printStackTrace();}}}
生成的分布式id(18位):
生成的分布式id :332180831769219072生成的分布式id :332180831811162112生成的分布式id :332180831853105152生成的分布式id :332180831895048192生成的分布式id :332180831936991232生成的分布式id :332180831983128576生成的分布式id :332180832025071616生成的分布式id :332180832071208960生成的分布式id :332180832113152000生成的分布式id :332180832155095040生成的分布式id :332180832201232384生成的分布式id :332180832243175424生成的分布式id :332180832285118464生成的分布式id :332180832327061504生成的分布式id :332180832369004544生成的分布式id :332180832410947584生成的分布式id :332180832452890624生成的分布式id :332180832494833664生成的分布式id :332180832536776704生成的分布式id :332180832578719744生成的分布式id :332180832620662784生成的分布式id :332180832662605824生成的分布式id :332180832704548864生成的分布式id :332180832746491904生成的分布式id :332180832792629248生成的分布式id :332180832834572288生成的分布式id :332180832876515328生成的分布式id :332180832918458368

































还没有评论,来说两句吧...