Flink代码kill掉yarn任务,并且实现自动savepoint。
一,最近在做平台,就是前后端分离的项目,简单的说就是对各种组件整合一下子,所以呢,提交任务啥的都在平台上搞了。
二,这里实现的功能很简单吧。就是代码模式,执行任务就可以kill掉yarn上的Flink任务。并且能自动生成savapoint
三,我们需要写入的参数是:
1)yarn 任务id
String appId = "application_1600222031782_0023";
2)Flink任务的jobId
String jobid = "c4d7e2ff6a35d402eaf54b9f9ca0f6c6";
3)需要savapoint地址
String savePoint = "hdfs://dev-ct6-dc-master01:8020/flink-savepoints5";
pom依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-yarn_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>
如果不成功,执行任务的时候加上hadoop_home的环境变量(下面只是参考)
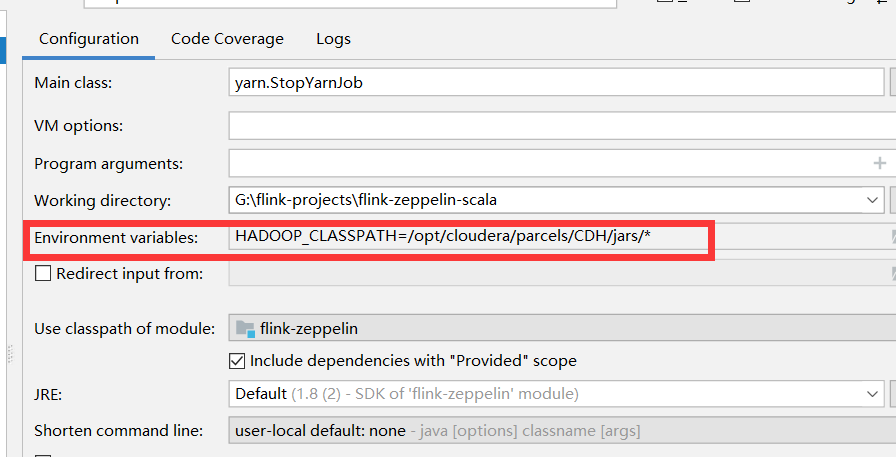
四,代码
import org.apache.flink.api.common.JobID;import org.apache.flink.client.cli.CliArgsException;import org.apache.flink.client.program.ClusterClient;import org.apache.flink.configuration.Configuration;import org.apache.flink.configuration.GlobalConfiguration;import org.apache.flink.util.FlinkException;import org.apache.flink.yarn.YarnClusterClientFactory;import org.apache.flink.yarn.YarnClusterDescriptor;import org.apache.flink.yarn.configuration.YarnConfigOptions;import org.apache.hadoop.yarn.api.records.ApplicationId;import java.util.concurrent.CompletableFuture;import java.util.concurrent.ExecutionException;public class StopYarnJob {public static void main(String[] args) throws FlinkException, CliArgsException, ExecutionException, InterruptedException {String hadoop_home = System.getProperty("HADOOP_HOME");System.out.println("hadoop_home = " + hadoop_home);String configurationDirectory = "G:/flink_working_tools/yarn-conf";String appId = "application_1600222031782_0023";String jobid = "c4d7e2ff6a35d402eaf54b9f9ca0f6c6";String savePoint = "hdfs://dev-ct6-dc-master01:8020/flink-savepoints5";//获取flink的配置Configuration flinkConfiguration = GlobalConfiguration.loadConfiguration(configurationDirectory);// Configuration flinkConfiguration = new Configuration();flinkConfiguration.set(YarnConfigOptions.APPLICATION_ID, appId);YarnClusterClientFactory clusterClientFactory = new YarnClusterClientFactory();ApplicationId applicationId = clusterClientFactory.getClusterId(flinkConfiguration);if (applicationId == null) {throw new FlinkException("No cluster id was specified. Please specify a cluster to which you would like to connect.");}YarnClusterDescriptor clusterDescriptor = clusterClientFactory.createClusterDescriptor(flinkConfiguration);ClusterClient<ApplicationId> clusterClient = clusterDescriptor.retrieve(applicationId).getClusterClient();JobID jobID = parseJobId(jobid);CompletableFuture<String> completableFuture = clusterClient.stopWithSavepoint(jobID,true,savePoint);String savepoint = completableFuture.get();System.out.println(savepoint);}private static JobID parseJobId(String jobIdString) throws CliArgsException {if (jobIdString == null) {throw new CliArgsException("Missing JobId");}final JobID jobId;try {jobId = JobID.fromHexString(jobIdString);} catch (IllegalArgumentException e) {throw new CliArgsException(e.getMessage());}return jobId;}}
五,测试效果
1)我们现实拿example的案例代码,打包提交到集群
public class SocketWindowWordCount {private static final Logger logger = Logger.getLogger(SocketWindowWordCount.class);public static void main(String[] args) throws Exception {// the host and the port to connect tofinal String hostname;final int port;try {final ParameterTool params = ParameterTool.fromArgs(args);hostname = params.has("hostname") ? params.get("hostname") : "localhost";port = params.getInt("port");} catch (Exception e) {System.err.println("No port specified. Please run 'SocketWindowWordCount " +"--hostname <hostname> --port <port>', where hostname (localhost by default) " +"and port is the address of the text server");System.err.println("To start a simple text server, run 'netcat -l <port>' and " +"type the input text into the command line");return;}// get the execution environmentfinal StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// get input data by connecting to the socketDataStream<String> text = env.socketTextStream(hostname, port, "\n");text.print("数据源");// parse the data, group it, window it, and aggregate the countsDataStream<WordWithCount> windowCounts = text.flatMap(new FlatMapFunction<String, WordWithCount>() {@Overridepublic void flatMap(String value, Collector<WordWithCount> out) {for (String word : value.split("\\s")) {out.collect(new WordWithCount(word, 1L));}}}).keyBy(value -> "aaa").process(new KeyedProcessFunction<String, WordWithCount, WordWithCount>() {private transient ValueState<Long> valueState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);ValueStateDescriptor<Long> valueStateDescriptor = new ValueStateDescriptor("totalAmountState",TypeInformation.of(new TypeHint<Long>() {}));valueState = this.getRuntimeContext().getState(valueStateDescriptor);}@Overridepublic void processElement(WordWithCount wordWithCount, Context context, Collector<WordWithCount> out) throws Exception {Long value = valueState.value();Long counts = wordWithCount.count;if (value != null){System.out.println("打印内存state = "+value);logger.error("打印内存state = "+value);value = value+counts;valueState.update(value);out.collect(wordWithCount);}else {value = counts;valueState.update(value);}}});// print the results with a single thread, rather than in parallelwindowCounts.print().setParallelism(1);env.execute("Socket Window WordCount");}// ------------------------------------------------------------------------/*** Data type for words with count.*/public static class WordWithCount {public String word;public long count;public WordWithCount() {}public WordWithCount(String word, long count) {this.word = word;this.count = count;}@Overridepublic String toString() {return word + " : " + count;}}}
2)运行任务脚本 :
export HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/jars/*;./bin/flink run -m yarn-cluster \
-yD yarn.containers.vcores=2 \
./examples/streaming/SocketWindowWordCount.jar —hostname 192.168.6.31 —port 12345
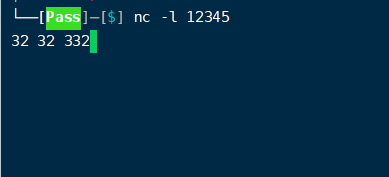
3)我们在linux环境 192.168.6.31节点执行 nc -l 12345
随意输入点数据
4)我们这个时候查看yarn任务打印输出:
假定state = 11
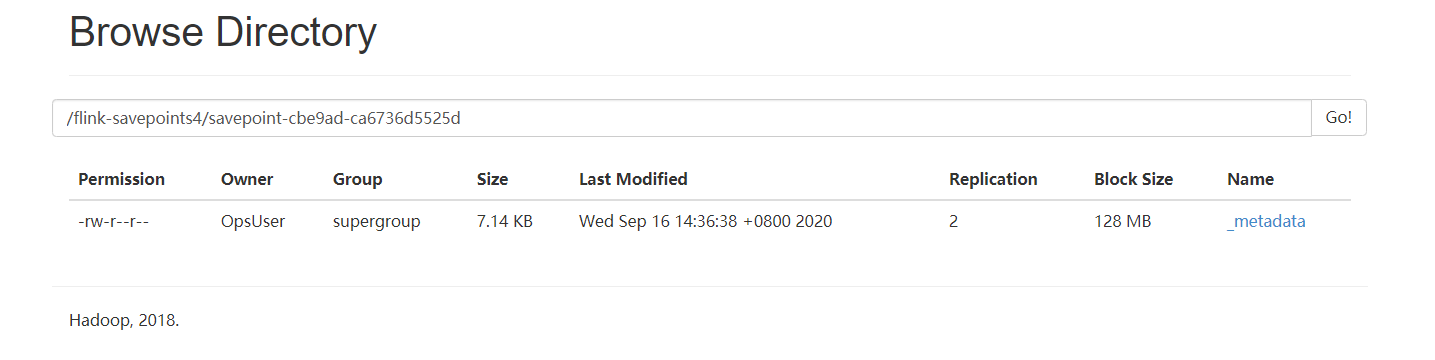
5)我们执行main方法,干掉任务,然后查看hdfs:
发现生成了文件…………..
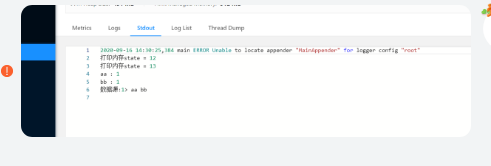
6)再次启动任务 ,输入nc -l 12345 输入一条数据,发现state打印是从上次state=12开始的,验证成功,savapoint有效果




























:轻松弄懂XHR的使用及如何封装简易axios")





还没有评论,来说两句吧...