【踩坑】RuntimeError: index out of range: Tried to access index 30522 out of table with 30521 rows.
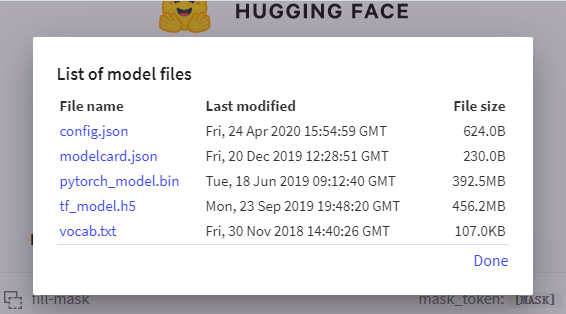
使用huggingface下载torch版本的bert-base-chinese预训练模型,格式如上图。
indexed_tokens = self.tokenizer.convert_tokens_to_ids(token)
在这里把token转成id,但是由于下载的vocab名称是”bert-base-chinese-vocab.txt”,默认读取的vocab名称是“vocab.txt”。应当将其改名为vocab.txt

踩坑
下载的模型自带英文的vocab.txt,我不知道要改名,或者把他的删除。
导致读取的英文vocab,然而config的vocab size是中文的vocab size,由此报错越界




























还没有评论,来说两句吧...