阶段性总结问题整理
1 Java编译过程
Java程序从源文件创建到程序运行要经过两大步骤:
Java文件由编译器编译成class文件- 字节码由
java虚拟机解释运行
编译阶段:创建源文件后,程序先要被
JVM中的java编译器进行编译为.class文件。编译一个类时,若这个类所依赖的类还没有被编译,编译器会自动的先编译这个所依赖的类,然后引用;若java编译器在指定的目录下找不到该类所依赖的类的.class文件或者.java源文件,就会报"Can't found sysbol"的异常错误编译后的字节码文件格式主要分为两部分:常量池+方法字节码
常量池记录的是代码出现过的字面量(文本字符串、八种基本类型的值、被声明为final的常量等)以及符号引用(类和方法的全限定名、字段的名称和描述符、方法的名称和描述符)
运行阶段:分为两个步骤
类的加载:加载 —> 验证 —> 准备 —> 解析 —> 初始化
加载:通过类的全限定名来获取定义该类的
Class文件,在内存方法区生成一个java.lang.Class对象验证:确保
Class文件的二进制字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全准备:在方法区中进行为静态变量分配内存和设置初始值
解析:虚拟机将Class常量池内的符号引用替换为直接引用
符号引用:符号引用以一组符号来描述所引用的目标
直接引用:是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄
初始化:初始化赋值类变量和其他资源,实质是执行类构造器
<clinit>()方法的过程,它是由编译器自动收集类中所有类变量的赋值和静态代码块语句合并产生
类的运行:
JVM在程序运行时第一次主动使用类时,才会去加载,加载完毕后生成一个java.lang.Class对象,并存放在方法区。初始化类构造器<clinit>()方法只执行一次,静态代码块,类变量赋值语句只执行一次,只生成一个java.lang.Class对象
2 如何查看内联成功
Linux系统下创建一个Test.cpp
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JbE2umKv-1602235380583)(C:\Users\BONC\Desktop\表达式二叉树分享展示MD.assets\01.png)]
执行 g++ -S Test.cpp
将文件转换成汇编语言,生成.s文件,.s文件是汇编文件,其内容是汇编指令
查看 Test.s 文件,call表示函数调用指令,发现并没有内联成功
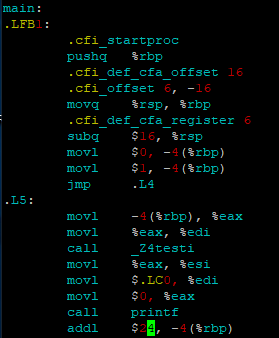
使用attribute__((always_inline)) 宏,创建一个NewTest.cpp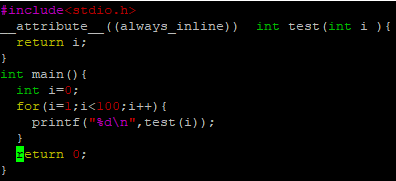
执行 g++ -S NewTest.cpp
g++弹出警告:即使使用了 attribute__((always_inline))内联函数也不一定内联成功
查看NewTest.s文件,发现没有调用test函数的指令,证明内联成功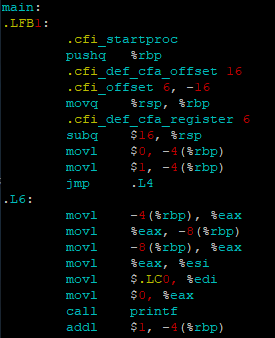
3 指针和系统还是编译器相关
最小寻址单位:内存的最小寻址单位是字节,即一个指针地址值对应内存中一个字节的空间
寻址能力:CPU最大能查找多大范围的地址,如32位的CPU寻址能力为2^32的地址,即4G,这也是32位的CPU最大能搭配4G内存的原因 ,再多CPU就找不到了
32位处理器上32位操作系统的32位编译器,指针大小4字节
32位处理器上32位操作系统的16位编译器,指针大小2字节
32位处理器上16位操作系统的16位编译器,指针大小2字节
16位处理器上16位操作系统的16位编译器,指针大小2字节
从结果来看指针的大小似乎和编译器有关,实际并不是,因为当前运行模式的寻址位数是不一样的,如下:
Intel 32位处理器32位运行模式,逻辑寻址位数32,指针也就是32位,即4个字节
Intel 32位处理器16位运行模式,逻辑寻址位数16,指针也就是16位,即2个字节
编译器的作用是根据CPU的特性将源程序编译为可在该CPU上运行的目标文件。如果一个编译器支持某32位的CPU,那么它就可以将源程序编译为可以在该CPU上运行的目标文件。该源程序中指针大小也会被编译器根据该CPU的寻址位数(如32位)编译选择为4字节
综上可得:指针大小是由当前CPU运行模式的寻址位数决定
4 结构体没内容大小及原因
在C语言下空结构体大小为0(编译器相关)
在C++下,空类和空结构体的大小是1(编译器相关)
因为C++标准中规定:任何不同的对象不能拥有相同的内存地址
“no object shall have the same address in memory as any other variable”
如果空类大小为0,我们声明一个这个类的对象数组,那么数组中的每个对象都拥有了相同的地址,这显然是违背标准的
为什么C++标准中会有这样的规定?
声明一个类型T的数组,然后再声明一个T类型的指针指向数组中间某个元素,将指针减去1,应该得到数组的另一个索引。如下代码:
T array[5];int diff = &array[3] - &array[2];// diff = 1 12345
上面的代码是一种指针运算,将两个指针相减,编译器作出如下面式子所示的转换:
diff = ((char *)&array[3] - (char *)&array[2]) / sizeof T;
很明显式子的计算依赖于sizeof T,基本上所有指针运算都依赖于sizeof T
如果允许不同的对象有相同的地址将会将没有办法通过指针运算来区分不同的对象,还有如果 sizeof T是0,就会导致编译器产生一个除0的操作。基于这个原因,如果允许结构体或者类的大小为0,编译器就需要实现一些复杂的代码来处理这些异常的指针运算
所以,C++标准规定不同的对象不能拥有相同的地址。
那么怎样才能保证这个条件被满足呢?最简单的方法就是不允许任何类型的大小为0
所以编译器为每个空类或者空结构体都增加了一个虚设的字节,这样空类和空结构的大小就不会是0,就可以保证它们的对象拥有彼此独立的地址
5 内存对齐之为什么不能跨越两个基本类型空间
性能较低:CPU每次寻址都是要消费时间的,如果一次取不完数据就要取多次。比如int类型的变量a占4Byte,且存放在0x00000003 - 0x00000006处。那么每次取4字节(32位总线)的CPU第一次取到[0x00000000 - 0x00000003],只得到变量a的1/4数据,还需要第二次取数[0x00000004 - 0x00000007],为了得到int类型变量a的值,却需要两次访问内存,并且还需要拼接处理
不具有可移植性:有些CPU在内存跨越基本类型空间的情况下,执行二进制代码会崩溃,因为不是所有的硬件平台都能访问任意地址上的任意数据
6 枚举类型被替换的时间
枚举默认是用int类型来存储的,32位系统下占4个字节。#define 定义的常量,在预编译时替换。而enum定义的常量,并不是在预编译的时候进行替换,而是在运行时替换,根据标识去常量区获取对应的值
EnumTest 枚举测试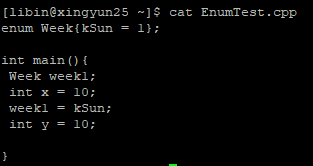
查看编译后的 EnumTest.s 文件
发现枚举变量的确在预处理阶段被做了替换,说明博客内容是错误的
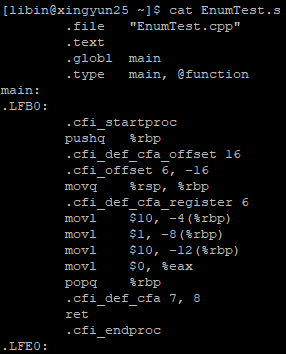
7 为什么枚举的范围是2的次方
如果某个枚举符的值均为非负值,该枚举的取值范围就是[0~2^k-1]
如果存在负的枚举符值,则该枚举的取值范围就是[-2k~2k-1]
推导过程:
例 enum kE1{a=1};
枚举最大值为 1 需要一个二进制位表示,最大值 2^0 = 2^1 - 1,因此枚举的范围为 [0,1]
例 enum kE2{a=1,b=3};
枚举最大值为 3 需要两个二进制位表示,最大值 2^1 + 2^0 = 2^2 - 1,因此枚举的范围为 [0,3]
当存在负的枚举值时
例 enum kE1{a=-1};
枚举最大值为 -1 需要两个二进制位表示,一位表示符号位,一位表示值位。
最小值 -2^1,最大值 -2^0 因此枚举的范围为 [-2,1]
8 dynamic_cast 为什么转换类指针时,基类需要虚函数
dynamic_cast依赖于RTTI信息,在转换时会检查转换的source对象是否真的可以转换为target类型,这种检查不是语法上的,而是真实情况的检查。编译器会通过vtable找到对象的RTTI信息,如果基类没有虚方法,就无法判断基类指针变量所指对象的真实类型,这时dynamic_cast只能用来做安全转换,例上行转换总结:
dynamic_cast是根据RTTI信息判断类型转换是否合法,编译器需要通过vtable来找到其RTTI信息
RTTI:即通过运行时类型识别,程序使用基类的指针来检查指针所指对象的实际派生类型
9 static为什么可以子类转父类,父类不可转子类
static_cast关键字(编译时类型检查)
用于基本数据类型之间的转换,但这种转换的安全性需开发者保证,例把int转换为char时,如果int>127或int<-127时,那么static_cast 只是简单的把
int的低8位复制到char的8位中,并直接抛弃高位把空指针转换成目标类型的空指针
把任何类型的表达式类型转换成void类型
用于类层次结构中父类和子类之间指针和引用的转换
上行转换(子类转父类)和下行转换(父类转子类),对于static_cast,上行转换是安全的,而下行转换时不安全的。因为static_cast的转换是粗暴的,它仅根据尖括号中的类型来进行转换,由于子类总是包含父类的数据成员和函数成员,因此从子类转换到父类的指针对象是安全的。而对于下行转换,static_cast 只在编译时进行了类型检查,没有运行时类型检查,因此不安全
10、C & C++ 中 void* 的区别
// C语言中在没有强转的情况下,允许void*赋给其他任何类型的指针// 但是C++中不允许通用类型指针赋值给特定类型指针void* test1 = (void*)0;// 编译报错 void*类型不能赋值给 int* 类型//int* test2 = (void*)0;// c和c++里 NULL的区别// c++里NULL就是0,c里面NULL是(void*)0
11、指针和引用 Test1
例一
void GetMemory(char *p){p = (char *)malloc(100);}void Test(void){char *str = NULL;GetMemory(str);strcpy(str, "hello world");printf(str);}
解决方法一
void GetMemory(char **p){*p = (char *)malloc(100);}void Test(void){char *str = NULL;GetMemory(&str);strcpy(str, "hello world");printf(str);}
解决方法二
void GetMemory(char* &p){p = (char *)malloc(100);}void Test(void){char *str = NULL;GetMemory(str);strcpy(str, "hello world");printf(str);}
12 C++中用==判断字符串会出现什么情况
C++ string 重载了 == 操作符,可以进行两个字符串相等的判断
char s1[] = "Test";char s2[] = "Test";std::string p1 = "Test";std::string* p2 = new std::string("Test");std::string* p3 = new std::string("Test");std::cout << "s1 == s2 \t" << (s1 ==s2) << std::endl; // 0std::cout << "p1 == *p2 \t" << (p1 == *p2) << std::endl; // 1std::cout << "p2 == p3 \t" << (p2 == p3) << std::endl; // 0std::cout << "*p2 == *p3 \t" << (*p2 == *p3) << std::endl; // 1
13 堆和栈哪个快
1、分配和释放,堆在分配和释放时需要调用函数(MALLOC,FREE),分配内存时会到堆去寻找足够大小的空间,而栈不需要
);
strcpy(str, "hello world");printf(str);
}
解决方法二```c++void GetMemory(char* &p){p = (char *)malloc(100);}void Test(void){char *str = NULL;GetMemory(str);strcpy(str, "hello world");printf(str);}
12 C++中用==判断字符串会出现什么情况
C++ string 重载了 == 操作符,可以进行两个字符串相等的判断
char s1[] = "Test";char s2[] = "Test";std::string p1 = "Test";std::string* p2 = new std::string("Test");std::string* p3 = new std::string("Test");std::cout << "s1 == s2 \t" << (s1 ==s2) << std::endl; // 0std::cout << "p1 == *p2 \t" << (p1 == *p2) << std::endl; // 1std::cout << "p2 == p3 \t" << (p2 == p3) << std::endl; // 0std::cout << "*p2 == *p3 \t" << (*p2 == *p3) << std::endl; // 1
13 堆和栈哪个快
1、分配和释放,堆在分配和释放时需要调用函数(MALLOC,FREE),分配内存时会到堆去寻找足够大小的空间,而栈不需要
2、访问时间,访问堆的一个具体单元,需要两次访问内存,第一次得取得指针,第二次才是真正得数据,而栈只需访问一次。且堆的内容被操作系统交换到外存的概率比栈大,栈一般不会被交换出去

































还没有评论,来说两句吧...