KUDU 的缺点
前文:
Kudu的诞生解决了大数据领域的数据更新和OLAP,但是其缺点也是明显,使用时最好考虑如下。
一、情况
服务器情况:5台8Core32内存的服务器
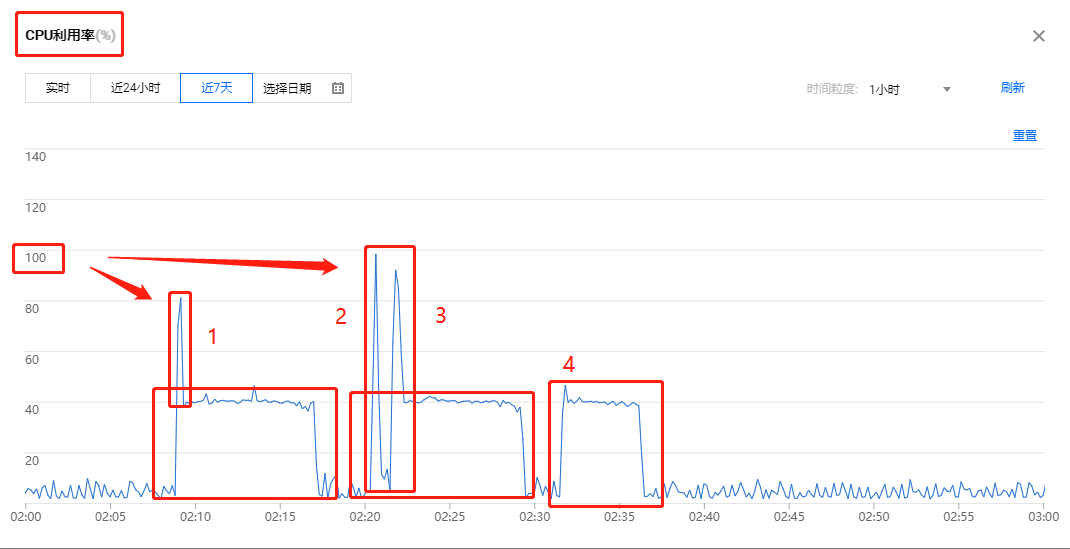
1.1 CPU使用率
" class="reference-link">1.2 磁盘读流量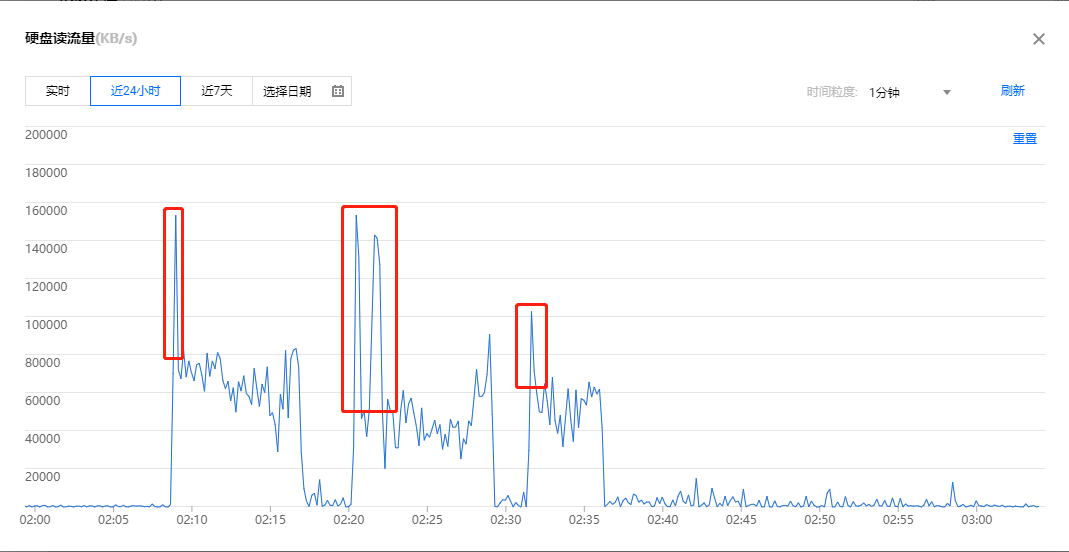
1.3 磁盘写

二、说明
2.1 操作
大量更新:
由于我们知道kudu更新的时候会有一个读过程,所以看到在更新时,读是远远大于写的。
但由于读的时候也伴随着CPU的负载的上升,瞬间打满。
2.1.1 第一个峰值说明
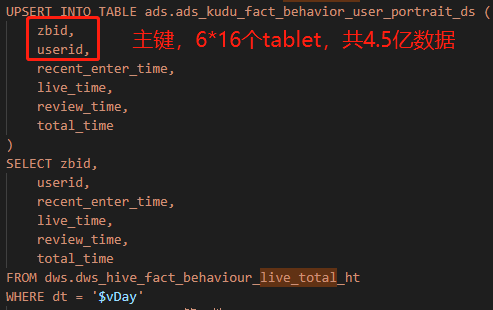
更新的数据量大概是近200万的临时表到4.5亿的用户信息表
2.1.2 第二三个峰值说明

数据源也是一张大表,但因为主键的性质导致更新时间字段不能用作主键,每次扫描当天变化的数据时,需要扫全表对应的列,即使是列式存储数据库,但瞬间负载很高。
2.1.3 剩余时间的较高CPU说明
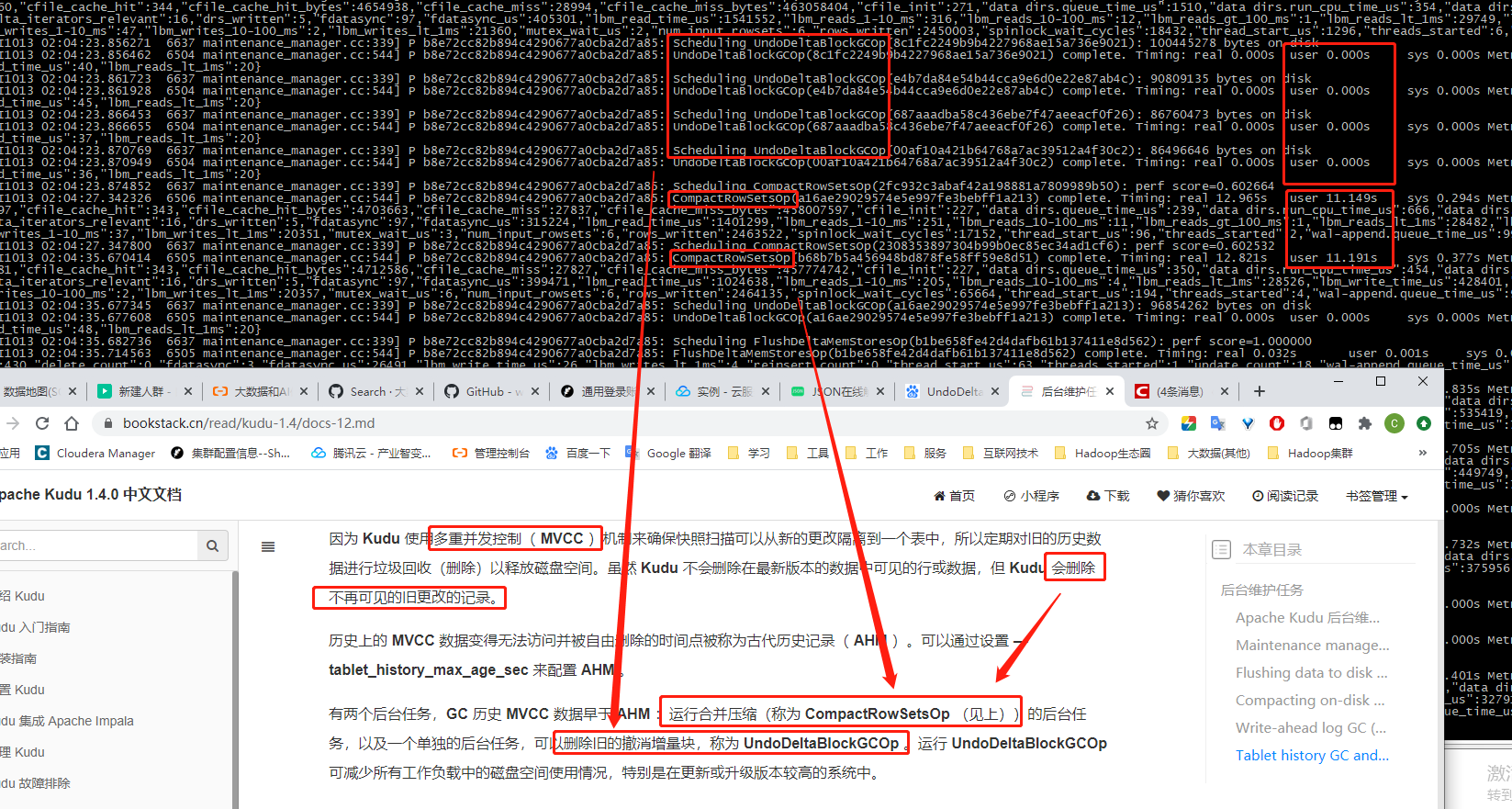
kudu在更新后,会启动多个线程对小文件进行操作。
2.2 应用场景缺点
2.2.1读性能
kudu的适用场景非常苛刻,必须走主键,否则,scan非主键列带来的是高CPU。
2.2.2大量写
kudu是牺牲了写性能而提高读性能,主要体现在主键,所以在批量更新的时候会有大量的读。
kudu可能更适用于实时场景,不断地写,这样对服务器的负载会低很多。
2.2.3合并小文件
这个机制相对于Hive其实是优点,但合并小文件的负载同样不低,取决于你底层产生的小文件有多少,也是不读地读和写。
2.3 需求缺点
2.3.1 最近N天统计
更新每个用户最近N天的观看、购物等多种行为统计,所以每天要更新的行数非常多,数据库压力巨大。
2.3.2 匿名用户统计
匿名用户的潜在危险,匿名用户是基于cookie,也需要算最近N天的行为统计,但是匿名用户的有效性一般在15天,也就是说数据库后期用户大部分是匿名用户,统计的行数也会很多。
2.4 当初选择Kudu的理由
因为用户信息(上亿)关联多张表拼接成一张用户结果表的在Hive 会比较麻烦,所以通过利用Kudu的主键特性,去更新这个用户信息。但在更新的时候遇到了Kudu的性能问题。

























 离线部署单机的rabbitmq")

虚拟机的内存结构")
")





还没有评论,来说两句吧...