Hive高级应用(一)
目录
- 一、Hive架构
- 二、Hive的优点和使用场景
- 三、Hive和HBase的区别
- 四、Hive常用的命令
- 五、Hive常用属性配置
- 六、Hive中数据库的操作方式
- 七、Hive中数据库表的创建方式(三种)
- 八、Hive表的操作及表创建的场景
Apache Hive是一个构建在hadoop基础设施之上的数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语言最终被转化为MapReduce. 虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询–因为它只能够在Haoop上批量的执行Hadoop。
一、Hive架构
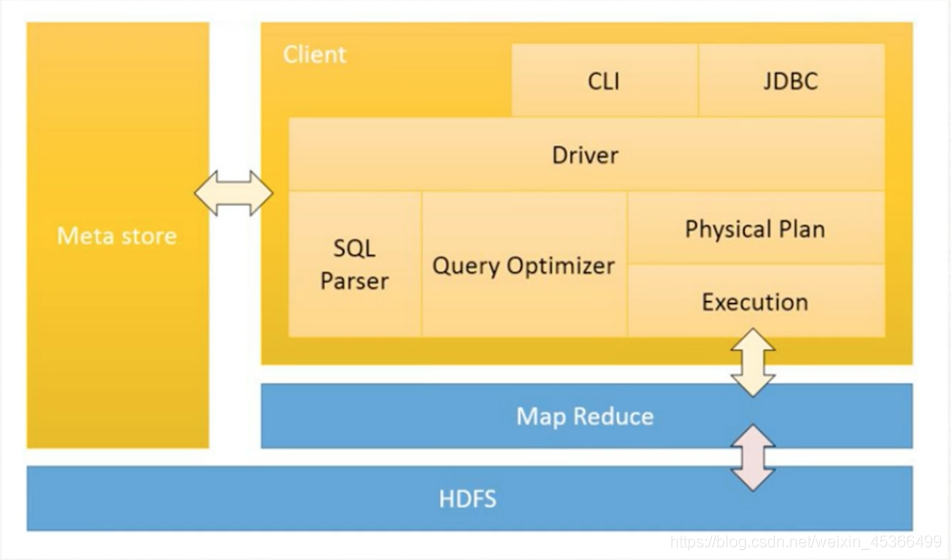
1.用户接口:Client
CLI(hive shell) JDBC(java访问hive) WEBUI(浏览器访问hive)
2.元数据(Metastore)-数据库
元数据包括:表名称、表所属的数据库、表的拥有者、列/分区字段名、表的类型(外部/内部)、表的数据所在的目录
默认存储在自带的derby的数据库中,推荐使用Mysql来存储元数据
3.hadoop
hive使用HDFS进行数据的存储,使用MR进行数据的计算
4.驱动器:driver
包含:
解析器 -> 优化器 -> 编译器 -> 执行器
二、Hive的优点和使用场景
1.简单易用(操作接口采用类SQL语法,提供快速开发的能力)
2.避免我们去写MR,减少开发人员的学习成本
3.统一的元数据管理,可与impala、spark等共享数据
4.易扩展
5.数据的离线处理:比如日志分析,海量结构化数据离线分析
6.Hive的执行延迟比较高,因此Hive常用于数据离线分析,适合实时性要求不高的场景
7.Hive优势在于处理大数据,对于处理小数据没有优势,因为hive的执行延迟性很高。
三、Hive和HBase的区别
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
共同点:
- hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储
区别: - Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
- 想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
- Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
- Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。
- hive借用hadoop的MapReduce来完成一些hive中的命令的执行
- hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
- hbase是列存储。
- hdfs作为底层存储,hdfs是存放文件的系统,而Hbase负责组织文件。
- hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
四、Hive常用的命令
1.显示数据库
show databases;
2.创建数据库
create database db_hive;
3.删除数据库
drop database db_hive;
4.使用数据库
use db_hive;
5.创建表:
CREATE TABLE u_data (userid INT,movieid INT,rating STRING,unixtime STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILE;
6.加载数据
load data local inpath '/opt/datas/ratings.txt' into table u_data;
7.查看表中数据
select * from u_data;select userid from u_data;select count(1) u_count from u_data;
8.查看表结构
desc u_data;desc extended u_data;desc formatted u_data;
9.查看hive中自带的函数
show functions;
10.查看hive中自带的函数的用法
desc function upper;desc function extended upper;CREATE TABLE student(userid INT,username STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILE;
11.查询userid,upper这两个字段,将username改为大写
select userid,upper(username) uppper_name from student;
五、Hive常用属性配置
1.Hive数据仓库位置配置
<property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property>$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
2.Hive运行日志的配置
配置conf/hive-log4j.properties文件
hive.log.dir=/opt/modules/hive/logshive.log.file=hive.log
3.Hive运行日志的级别
hive.root.logger=info,DRFA
4.在cli命令行上显示当前数据库名称,以及查询表的表头信息
<property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property>
5.在启动hive时设置配属属性想信息
bin/hive --hiveconf <property=value>eg: bin/hvie --hiveconf hive.cli.print.header=false
此种方式的设置,仅仅在当前会话session中有效
6.查看hive当前所有的配置信息
set;set hive.cli.print.header;set hive.cli.print.header=false;优先级:set -> --hiveconf -> hive-site.xml -> hive-defualt.xml
六、Hive中数据库的操作方式
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION hdfs_path][WITH DBPROPERTIES (property_name=property_value, ...)];创建数据库1.create database db_hive;CREATE DATABASE IF NOT EXISTS db_hive --- 标准方式CREATE DATABASE IF NOT EXISTS db_kfk LOCATION '/user/kfk/kfkwarehouse';删除数据库2.drop databaseDROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];drop database IF EXISTS db_kfk;--- 标准方式drop database IF EXISTS db_hive cascade;使用数据库3.use databaseUSE database_name;
七、Hive中数据库表的创建方式(三种)
第一种:创建表按分隔符隔开
CREATE TABLE IF NOT EXISTS db_name.table_name(col_name data_type )ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILE;eg:CREATE TABLE student (userid string,username string)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILE;
第二种:克隆一份表,表结构和existing_table_or_view_name一样,但是没有数据
CREATE TABLE IF NOT EXISTS db_name.table_nameLIKE existing_table_or_view_name;eg:CREATE TABLE IF NOT EXISTS db_hive.stuLIKE db_hive.student;
第三种:创建一份表,表的结构和数据和table一样
CREATE TABLE IF NOT EXISTS db_name.table_nameAS select * from table;eg:CREATE TABLE IF NOT EXISTS db_hive.stuAS select * from db_hive.student;
八、Hive表的操作及表创建的场景
Hive数据分析完成之后的结果我们会保存在什么地方?
存储到HDFS上
存储在hive的表中(临时表)
2.drop table(删除数据表)
DROP TABLE IF EXISTS table_name;
3.truncate table (删除表结构)
TRUNCATE TABLE table_name;
4.加载数据
load data local inpath '/opt/datas/student.txt' into table student;覆盖数据:load data local inpath '/opt/datas/student.txt' overwrite into table student ;insert into table stu select * from student;加载hdfs上的数据覆盖到表中:load data inpath '/user/kfk/datas/student.txt' overwrite into table student;
上述内容笔记为Hive高级应用(一)。Hive高级应用(二)(三)后续更新!
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!

























")


还没有评论,来说两句吧...