3.2.6 spark体系之分布式计算-spark-core之离线计算-Spark的RDD和算子概念
目录
1.RDD
1.1 概念
1.2 RDD的五大特性
1.3 RDD的理解图
2.Spark任务执行原理(Standalone集群)
3.Spark代码流程
4.Transformations转换算子
4.1 概念
4.2 Transformation类算子
4.2.1 filter算子的使用
4.2.2 sample算子的使用
5.Action行动算子
5.1 概念
5.2 Action类算子
6.控制算子-RDD的持久化(都是懒执行方式)
6.1 概念
6.2 cache
6.3 persist
6.4 checkpoint
6.4.1 checkpoint 的执行原理:
6.4.2 checkpoint 使用方式
1.RDD
1.1 概念
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象(计算抽象),表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持丰富的转换操作(如map, join, filter, groupBy等),通过这种转换操作,新的RDD则包含了如何从其他RDDs衍生所必需的信息,所以说RDDs之间是有依赖关系的。基于RDDs之间的依赖,RDDs会形成一个有向无环图DAG,该DAG描述了整个流式计算的流程,实际执行的时候,RDD是通过血缘关系(Lineage)一气呵成的,即使出现数据分区丢失,也可以通过血缘关系重建分区,总结起来,基于RDD的流式计算任务可描述为:从稳定的物理存储(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的DAG,然后写回稳定存储。另外RDD还可以将数据集缓存到内存中,使得在多个操作之间可以重用数据集,基于这个特点可以很方便地构建迭代型应用(图计算、机器学习等)或者交互式数据分析应用。可以说Spark最初也就是实现RDD的一个分布式系统,后面通过不断发展壮大成为现在较为完善的大数据生态系统,简单来讲,Spark-RDD的关系类似于Hadoop-MapReduce关系。
1.2 RDD的五大特性
- RDD是由一系列的partition组成的,partition数量由读取文件的block决定。
- 函数(算子)是作用在每一个partition(split)上的。
- RDD之间有一系列的依赖关系。
- 分区器是作用在K,V格式的RDD上。
- RDD提供一系列最佳的计算位置。
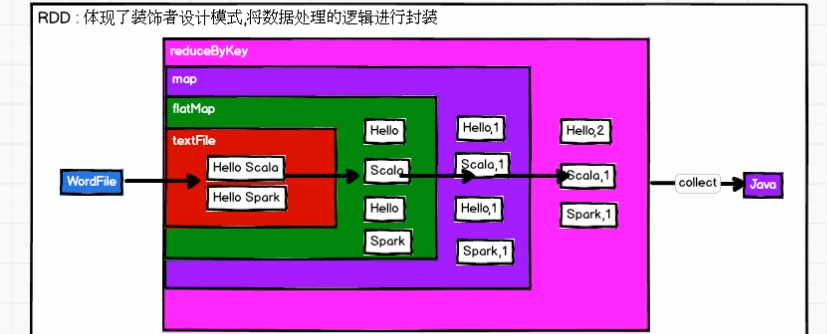
1.3 RDD的理解图

注意:
- sc.textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小(128M)。
- RDD**实际上不存储数据,这里方便理解,暂时理解为存储数据。**
- 什么是K,V格式的RDD? 如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
- 哪里体现RDD的弹性(容错)?partition数量可多可少,体现了RDD的弹性。RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
- 哪里体现RDD的分布式?RDD是由Partition组成,partition是分布在不同节点上的。
- RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
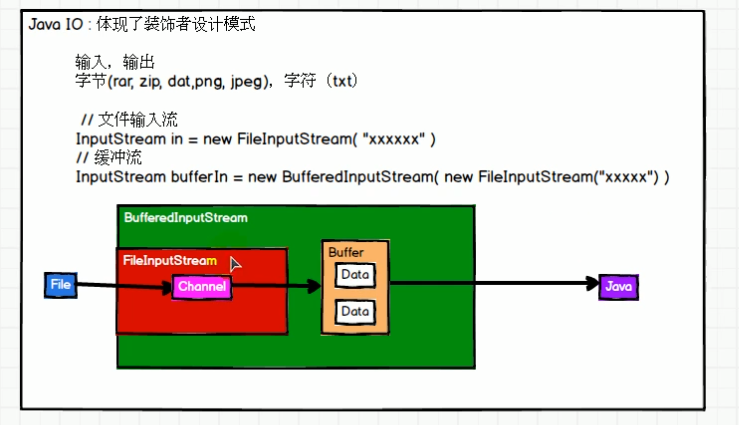
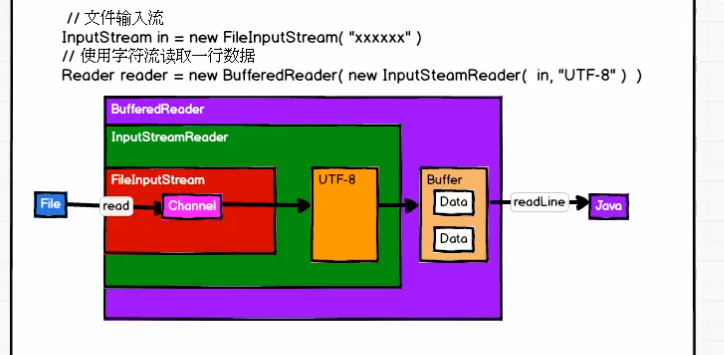
补充:javaIO
2.Spark任务执行原理(Standalone集群)
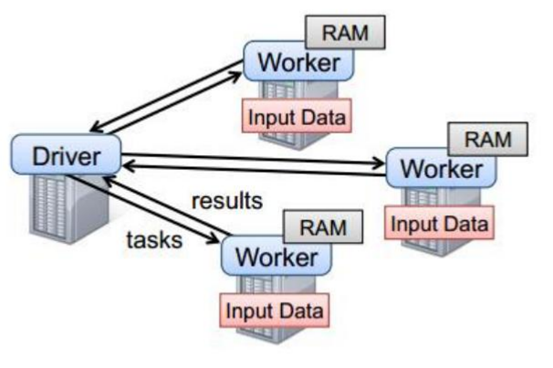
以上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
- Driver与集群节点之间有频繁的通信。
- Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了。会造成oom。
- Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程。
- Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程。
3.Spark代码流程
- 创建SparkConf对象,可以设置Application name;可以设置运行模式及资源需求。
- 创建SparkContext对象
- 基于Spark的上下文创建一个RDD,对RDD进行处理。
- 应用程序中要有Action类算子来触发Transformation类算子执行。
- 关闭Spark上下文对象SparkContext。
4.Transformations转换算子
4.1 概念
Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行,需要行动算子的触发。
4.2 Transformation类算子
- filter:过滤符合条件的记录数,true保留,false过滤掉。
- map:将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。特点:输入一条,输出一条数据。
- flatMap:先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
- sample:随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。
- reduceByKey:将相同的Key根据相应的逻辑进行处理。
- sortByKey/sortBy:作用在K,V格式的RDD上,对key进行升序或者降序排序。
4.2.1 filter算子的使用
package com.bjsxt.spark;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.api.java.function.VoidFunction;import scala.Tuple2;public class JavaSparkWordCount2 {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");conf.setAppName("JavaSparkWordCount");JavaSparkContext sc = new JavaSparkContext(conf);JavaRDD<String> lines = sc.textFile("./words.txt");// 进行过滤,这个是Transformation类算子,懒加载// true留下,false的数据会被过滤掉// new Function<String, Boolean>表示进去一行数据,出去一个boolJavaRDD<String> filter = lines.filter(new Function<String, Boolean>() {private static final long serialVersionUID = 1L;@Overridepublic Boolean call(String line) throws Exception {// 输入是每一行的数据// 相当于是打印出所有的hello hadoopreturn line.equals("hello hadoop");}});// 遍历,行动算子,可以触发filter.foreach(new VoidFunction<String>() {private static final long serialVersionUID = 1L;@Overridepublic void call(String s) throws Exception {// TODO Auto-generated method stubSystem.out.println(s);}});sc.stop();}}

其他过滤实例:

我们分析一下上面的代码:
上面的代码是有问题的,当代码执行看到第一个count的时候,count是一个行动算子,往前回溯,找到errors这个RDD,再往前是lines这个RDD,然后按照顺序执行Transformations转换算子。但是当代码执行看到第二个count的时候,还会重复这一个过程,相当于每一次执行job都会向磁盘读取数据,速度是非常慢的。我们的代码对errors进行了重复使用,我们可以将errors这个RDD保存在磁盘上。
4.2.2 sample算子的使用
package com.bjsxt.spark;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.api.java.function.VoidFunction;import scala.Tuple2;public class JavaSparkWordCount3 {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");conf.setAppName("JavaSparkWordCount");JavaSparkContext sc = new JavaSparkContext(conf);JavaRDD<String> lines = sc.textFile("./words.txt");JavaRDD<String> sample = lines.sample(true, 0.2, 1000);// 第一个参数是有无返回值,第二个是抽样比例,第三个是抽样的种子System.out.println(sample.count());sc.stop();}}
4.2.3
5.Action行动算子
5.1 概念
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
5.2 Action类算子
- count 返回数据集中的元素数。会在结果计算完成后回收到Driver端。
- take(n) 返回一个包含数据集前n个元素的集合。
- firstfirst=take(1), 返回数据集中的第一个元素。
- foreach 循环遍历数据集中的每个元素,运行相应的逻辑。
- collect 将计算结果回收到Driver端。
一个完整的Spark程序称为一个application应用程序,application是由job组成的,job就是我们理解的任务,job数量由Action行动算子决定,1个行动算子决定一个job任务。
Transformation类算子都是从RDD到RDD类型,Action类算子都是由RDD到非RDD类型。

package com.bjsxt.spark;import java.util.List;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;public class JavaSparkWordCount3 {public static void main(String[] args) {SparkConf conf = new SparkConf();conf.setMaster("local");conf.setAppName("JavaSparkWordCount");JavaSparkContext sc = new JavaSparkContext(conf);JavaRDD<String> lines = sc.textFile("./words.txt");// take取出List<String> take = lines.take(5);for (String s : take) {System.out.println(s);}// first第一行数据String first_data = lines.first();System.out.println(first_data);// collect 返回listList<String> collect = lines.collect();for (String s : collect) {System.out.println(s);}sc.stop();}}
6.控制算子-RDD的持久化(都是懒执行方式)
6.1 概念
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,三种持久化的单位都是partition。三种算子都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
6.2 cache
默认将RDD的数据持久化到内存中,cache是懒执行。
- 注意:chche () = persist()=persist(StorageLevel.Memory_Only)
测试cache文件:

6.3 persist
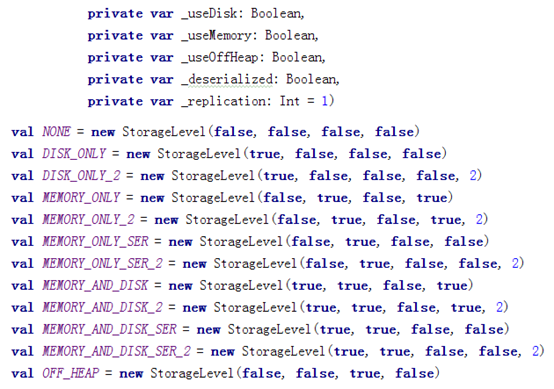
可以指定持久化的级别。最常用的是MEMORY_ONLY和MEMORY_AND_DISK(内存不够了,剩下的放磁盘)。”_2”表示有副本数。

持久化级别如下:
cache**和persist的注意事项:**
- cache和persist都是懒执行,必须有一个action类算子触发执行。
- cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
- cache和persist算子后不能立即紧跟action算子。错误:rdd.cache().count() 返回的不是持久化的RDD,而是一个数值了。
6.4 checkpoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系,也是一个懒执行方式。
6.4.1 checkpoint 的执行原理:
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
- 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记,继续回溯到源头。
- Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上(checkpoint目录中)。
优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。
6.4.2 checkpoint 使用方式
SparkConf conf = new SparkConf();conf.setMaster("local").setAppName("checkpoint");JavaSparkContext sc = new JavaSparkContext(conf);sc.setCheckpointDir("./checkpoint");JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3));parallelize.checkpoint();parallelize.count();sc.stop();




























还没有评论,来说两句吧...