对solr索引库进行CRUD
1.通过solr后台管理界面对索引进行CRUD
1.删除一条索引(通过xml格式)

删除成功 Status:success
2.新增一条索引

#
新增成功 Status:success
3.query查询

" class="reference-link">
高亮显示

Request-Handler(qt):
q: 查询字符串(必须的)。:表示查询所有;keyword:东看 表示按关键字“东看”查询
fq: filter query 过滤查询。使用Filter Query可以充分利用Filter Query Cache,提高检索性能。作用:在q查询符合结果中同时是fq查询符合的(类似求交集),例如:q=mm&fq=date_time:[20081001 TO 20091031],找关键字mm,并且date_time是20081001到20091031之间的。
sort: 排序。格式如下:字段名 排序方式;如advertiserId desc 表示按id字段降序排列查询结果。
start,rows:表示查回结果从第几条数据开始显示,共显示多少条。
fl: field list。指定查询结果返回哪些字段。多个时以空格“ ”或逗号“,”分隔。不指定时,默认全返回。
df: default field默认的查询字段,一般默认指定。
Raw Query Parameters:
wt: write type。指定查询输出结果格式,我们常用的有json格式与xml格式。在solrconfig.xml中定义了查询输出格式:xml、json、python、ruby、php、phps、custom。
indent: 返回的结果是否缩进,默认关闭,用 indent=true | on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
debugQuery: 设置返回结果是否显示Debug信息。
dismax:
edismax:
hl: high light 高亮。hl=true表示启用高亮
hl.fl : 用空格或逗号隔开的字段列表(指定高亮的字段)。要启用某个字段的highlight功能,就得保证该字段在schema中是stored。如果该参数未被给出,那么就会高 亮默认字段 standard handler会用df参数,dismax字段用qf参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用 hl.requiredFieldMatch选项。
hl.simple.pre:
hl.requireFieldMatch: 如果置为true,除非该字段的查询结果不为空才会被高亮。它的默认值是false,意味 着它可能匹配某个字段却高亮一个不同的字段。如果hl.fl使用了通配符,那么就要启用该参数。尽管如此,如果你的查询是all字段(可能是使用 copy-field 指令),那么还是把它设为false,这样搜索结果能表明哪个字段的查询文本未被找到
hl.usePhraseHighlighter:如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
hl.highlightMultiTerm:如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。
facet:分组统计,在搜索关键字的同时,能够按照Facet的字段进行分组并统计。
facet.query:Facet Query利用类似于filter query的语法提供了更为灵活的Facet.通过facet.query参数,可以对任意字段进行筛选。
facet.field:需要分组统计的字段,可以多个。
facet.prefix: 表示Facet字段值的前缀。比如facet.field=cpu&facet.prefix=Intel,那么对cpu字段进行Facet查询,返回的cpu都是以Intel开头的, AMD开头的cpu型号将不会被统计在内。
spatial:
spellcheck: 拼写检查。
2.通过solrj实现索引的添加 更新 删除
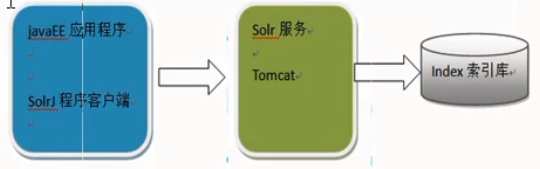
Solrj是访问Solr服务的java客户端,提供索引的创建删除更新以及查询相关API通过solrJ操作Solr流程如下图:
新建项目 添加jar包

1.添加 更新 删除
public class Solr_index_crud {public static void main(String[] args) {//添加或更新索引 如果id值来判断进行添加动作还是更新动作//addOrUpdate();//通过SorlJ进行索引的删除delete();}//查询或者添加public static void addOrUpdate() {try {//创建Solrj客户端对象,通过该对象可以与solr应用交互HttpSolrClient client = new HttpSolrClient.Builder("http://localhost:8080/solr/core1").withConnectionTimeout(10000).build();//创建文档实例 一个文档实例代表一条记录SolrInputDocument doc = new SolrInputDocument();//通过 SolrInputDocument指定列以及值的信息doc.addField("title", "苹果7s");doc.addField("price", 5000f);doc.addField("locality", "深圳富士康");client.add(doc);//提交事务client.commit();//关闭资源client.close();} catch (Exception e) {e.printStackTrace();}}public static void delete() {try {//创建Solrj客户端对象,通过该对象可以与solr应用交互HttpSolrClient client = new HttpSolrClient.Builder("http://localhost:8080/solr/core1").withConnectionTimeout(10000).build();client.deleteById("aac9e63e-0a62-449b-b644-491f8f89162d");//提交事务client.commit();//关闭资源client.close();} catch (Exception e) {e.printStackTrace();}}}
2.索引的检索 过滤 高亮等操作
//query查询public static void search() {try {//创建Solrj客户端对象,通过该对象可以与solr应用交互HttpSolrClient client = new HttpSolrClient.Builder("http://localhost:8080/solr/core1").withConnectionTimeout(10000).build();//创建SolrQuery实例 通过SolrQuery可以设置关键字 设置fl df 高亮 分页等信息SolrQuery solrQuery = new SolrQuery();solrQuery.setQuery("苹果手机");//设置默认域solrQuery.set("df", "title");//设置查询的字段solrQuery.set("fl", "id,title,price,locality");//分页查询solrQuery.setStart(0);solrQuery.setRows(2);//设置过滤条件solrQuery.set("fq", "price:[4000 TO *]");//打开高亮开关solrQuery.setHighlight(true);//指定高亮的字段solrQuery.addHighlightField("title");//设置高亮的相关格式solrQuery.setHighlightSimplePre("<font color='red'>");solrQuery.setHighlightSimplePost("<font/>");//将 solrQuery传入client中进行查询,得到QueryResponse实例 通过QueryResponse实例可以获取到所有的响应结果QueryResponse query = client.query(solrQuery);//获取结果SolrDocumentList results = query.getResults();//获取高亮后的结果集Map<String, Map<String, List<String>>> highlighting = query.getHighlighting();/** 最外层Map 集合 key:存放记录的id value:文档信息* 里面的Map集合 key:字段 value:字段对应的值* *///获取总记录数long numFound = results.getNumFound();for (SolrDocument result : results) {//高亮前的效果String id = (String) result.get("id");String title = (String) result.get("title");String locality = (String) result.get("locality");System.out.println(id+" "+title+" "+locality);//高亮后的的效果Map<String, List<String>> stringListMap = highlighting.get(id);String title1 = stringListMap.get("title").get(0);//标题可能有多个值System.out.println(title1);}client.close();} catch (Exception e) {e.printStackTrace();}}

























 —— 一个窗口显示多张图片")








还没有评论,来说两句吧...