AI入门:神经网络实战----迁移学习
前言
学过化学的人都知道,到现在为止,世界上一共只发现118种化学元素,通过不同的排列组合,却可以得到我们丰富多彩的世界。同样的,简单的几何结构也就那么几种,但正是由它们组成了这个世界。换个角度看,这个世界中的任何物体都是简单的几何结构中的一种或几种组合而成。
从上面的描述我们可以得出一个结论:任何物体的基本结构都是相似的。这个结论跟我们今天要学习的迁移学习有什么关系呢?请看下一段,什么是迁移学习。
什么是迁移学习?
在计算机视觉中,迁移学习往往使用带有卷积的神经网络 (不记得卷积神经网络的话,请查阅前面的章节),而卷积神经网络可以提取和总结物体的特征,这样就得到了一些基本结构。在前言中,我们提到任何物体的基本结构都是相似的。所以我们可以使用一些比较成熟的深度学习网络,使用它们提取特征的那部分网络参数,然后再连接到自己的网络上。这样得到的神经网络就可以只提取比较高级的特征,而不用提取一些基本结构了。这样可以在较短的时间里训练好一个效果比较好的网络。这里打个比方:把李子树的树枝嫁接到桃树上,这样就可以得到有桃子味道的李子,简称桃形李。迁移学习就是把我们自己写的部分神经网络“嫁接”到VGG等成熟的深度学习网络上,实现我们自己的功能。
理解了迁移学习的概念和目的之后,我们要介绍几种比较成熟的深度学习神经网络:VGG系列、ResNet系列。
VGG系列深度学习网络
VGG是Oxford的Visual Geometry Group的课题组在2014年的ILSVRC上提出的。该网络证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG系列深度学习网络包括VGG16和VGG19两种,两者主要是在层数上有所差别,识别效果相差不大。这里我们只介绍VGG16。这个网络至今 (2020年)已经有7年了,是一个非常古老的神经网络。

从上述示意图可以看出,VGG16可以处理224 * 224像素的彩色图片。一张图片将依次进入6个block:
block 1:包含两个卷积层,得到224 * 224 * 64的图片。再经过池化得到112 * 112 * 64的图片。
block 2:包含两个卷积层,得到112 * 112 * 128的图片,再经过池化得到56 * 56 * 128的图片。
block 3:包含三个卷积层,得到56 * 56 * 256的图片,再经过池化得到28 * 28 * 256的图片。
block 4:包含三个卷积层,得到28 * 28 * 512的图片,再经过池化得到14 *14 * 512的图片。
block 5:包含三个卷积层,得到14 * 14 * 512的图片,再经过池化得到7 * 7 * 512的图片。
block 6:把7 * 7 * 512的图片输入到4096个神经元的全连接层;最后把4096个神经元的全连接层的数据输入到1000个神经元的输出层,并用softmax进行处理。
由此可见,使用VGG16,一张图片需要经过13层卷积,5层池化,2次全连接操作才能得到最终结果。VGG16的优点是在迁移学习的效果比较好;缺点是参数量大,计算量也很大。存储VGG16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
ResNet
深度残差网络 (Deep residual network, ResNet) 的提出是CNN图像史上的一件里程碑事件,在ResNet之前,VGG19、GoogleNet (24层) 已经算是非常深的神经网络了。科学家发现神经网络在20层左右就遇到了瓶颈,继续增加网络的深度并不能有效的提高准确率。这一切随着ResNet的出现发生了改变。
ResNet算法类似于拉斯维加斯算法:在原来的神经网络的基础上增加一个可重复单元。如果增加这个单元后,网络的预测效果比原先更好,那就保留这个可重复单元,否则就用短接 (类似于电路中的短路) 的方式屏蔽这个单元。这样就可以保证增加的可重复单元不会导致神经网络的准确率变差。通过这种方式增加可重复单元,理论上可以使神经网络达到无限深度,而且这个新网络的准确率不比最初的网络差,这就是ResNet。由于添加的可重复单元数量不固定,所以ResNet有很多不同层数的版本,目前最多达到3002层,但使用的最多的是152层的ResNet。
下图红色方框中的结构就是一个可重复单元。如果输入数据x经过这个可重复单元处理后,效果还不如x本身,则通过旁边的曲线将这个可重复单元屏蔽掉。如果效果比x好,则保留这个可重复单元。ResNet就是大量使用这种可重复单元,一点一点的提高准确率,最终达到很好的效果。值得注意的是,那些不能提高准确率的单元已经被屏蔽掉了,它们不影响网络的效率,但是会占用一定的空间。所以相同大小的ResNet网络实际的计算量会比其它类型的网络小一些。
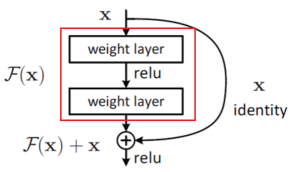
下面,我们来考虑一个问题:如果我们在VGG19的基础上构建ResNet网络,这样是不是可以得到比VGG19更好的效果?答案是:确实如此。事实上,2015年出现的ResNet就是在2014年的VGG19的基础上修改并构建得到的,只不过把网络增加到152层这样的超级深度。ResNet之后出现的网络基本上都是在ResNet的基础上进行改进,比如DenseNet采用了稠密连接,2017年ILSVRC比赛冠军SENet是在ResNet的可重复单元增加一个轻量级模块得到的。
迁移学习的问题1:为什么要用迁移学习?
我们已经学会了一般的全连接神经网络,卷积神经网络,用这些神经网络就可以识别MNIST数据集、未来也能识别CIFA数据集,或者是自己的数据集中的图片,为什么还要迁移学习?
原因是:
① 这些成熟的神经网络的效果很好,我们没有必要从头开始写网络,即使自己写,效果也不见得比现有的好。
② 从头开始训练一个神经网络是非常耗时耗力的工作,而使用迁移学习,我们只需要花费比较少的时间就可以达到较好的结果,同时可以使用较小的系统资源。
迁移学习的问题2:如何减少参数量?
在介绍卷积神经网络时,我们曾埋下一个伏笔:卷积层与全连接层之间的参数量占据整个网络的参数量的80+%。使用迁移学习时,我们也就是把自己的全连接层“嫁接”到原先网络的卷积层上,这时,我们同样会面对参数量巨大的问题。巨大的参数量意味着训练困难,占用的资源多等问题。
这个问题可以使用全局平均池化解决。所谓全局平均池化就是把卷积得到的所有子图片都池化成一个值。例如VGG16的卷积层最后输出一共512张子图片,每张子图片的尺寸为7 * 7。下面的全连接层有4096个神经元,则一共需要512 * 7 * 7 * 4096 = 1.03亿个参数 (只考虑w,不考虑b)。
使用全局平均池化后,子图片的尺寸变成1 * 1,则参数量变成512 * 1 * 1 * 4096 = 210万个 (只考虑w,不考虑b)。用这种方式可以减少98%的参数量。事实证明,使用全局平均池化后,参数量减少了,识别效果却没有明显变差。
迁移学习的实现:
用PyTorch实现迁移学习时,不同的网络的实现方式稍稍有点区别,所以本节将分别以VGG16和ResNet18这两种网络模型为基础实现迁移学习作为演示。
实现ResNet18版本的迁移学习:
跟之前使用MNIST数据集进行训练不同,这次使用的图片尺寸是不固定的。ResNet18的输入图片大小是224 * 224,所以要在读取数据的时候就把图片的尺寸转化成224 * 224。

接下去就可以定义模型了。我们在构造函数中使用ResNet18作为baseModel。参数pretrained=True表示自动下载ResNet18的模型。自动下载的ResNet18的模型存放在:C:\Users\Administrator.WIN7U-20191114A.cache\torch\hub\checkpoints,尺寸为44.6M。我们要进行迁移学习,所以一定要记得把ResNet18中的每一层的参数都设置为不可学习。然后我们查看一下resnet18的结构。

我们发现ResNet18的结构很复杂,每一个模块都有一个唯一的名称,所以可以用名称指代特定的模块。例如最后两层的名称分别为avgpool和fc,我们就可以用fc表示最后一个模块。

从上图看到,fc层的输入数据个数为512。这个512可以手动指定,也可以用代码获取:

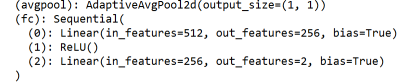
我们需要修改ResNet18的最后一个模块,也就是修改fc模块,但不修改fc模块的名称。原本的fc模块只是一个全连接,这里要替换成2个全连接层。如果愿意,也可以加入Dropout。值得注意的是,为了实现二分类任务,最后的输出是2,而不是1。(虽然我们用Sigmoid函数实现输出1个数据表示二分类,但仍然要写输出为2。)

这样就定义完了新的模型。再次显示这个模型,我们就可以发现模型的最后一层成功的变成我们新设置的2层全连接:
定义完模型后,我们就可以在forward()中使用新模型了:

接下去,我们定义模型的损失函数和优化函数:

下面我们就可以进行训练了:训练过程与之前的一样

测试代码也是大同小异:

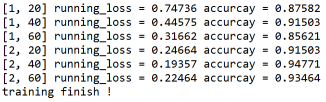
最终经过两轮学习,达到93.5%的准确率。如果增加学习次数,应该可以进一步提高准确率:
实现VGG16版本的迁移学习:
这里只简要的编写VGG16版本的迁移学习。在构造函数中,我们使用vgg16作为baseModel。该模型自动下载后,我们发现VGG16模型占用527.8M空间,是ResNet的11.8倍。显然,尺寸较小的ResNet比VGG16更加适合在移动设备中使用。

打印VGG16的模型,我们发现最后一个模块的名字是:classifier。这跟ResNet的最后一个模块的名称不一样,所以一定要查看模型的具体信息,才能获得模块名称。classifier第0层的输入参数是25088。
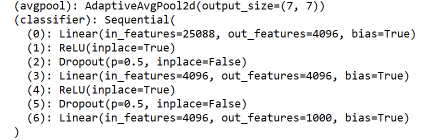
在前面提到:把卷积层最后输出的图片都池化成1*1的图片后,参数量可以减少至原先的1/49,在大幅减少参数量的同时,且不明显影响准确率。所以我们需要修改avgpool模块和classifier模块。值得注意的是,25088/49之后变成了float类型的数据,一定要转化成int才能用在后面使用。最后一个模块的修改方式跟ResNet18的方式一样。
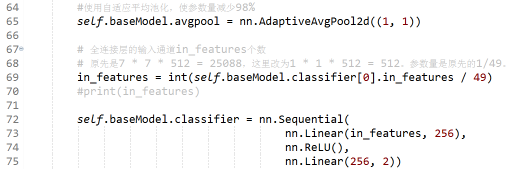
我们可以看到新模型的最后两个模块已经成功修改成我们希望的那样了:
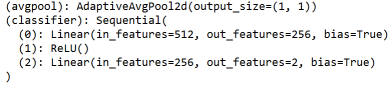
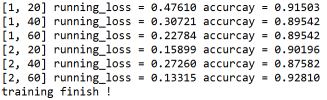
接着我们定义相同的方式计算,定义相同的损失函数、优化函数、以及相同训练代码和测试代码。我们发现使用以VGG16为baseModel的迁移学习在训练时比使用ResNet18慢很多,且准确率也要低一些。经过两轮训练,最终达到92.8%的准确率:
总结:
迁移学习本质上与自己写的深度CNN网络没有区别,但是从头开始训练一个深度CNN网络是耗时耗力的工作。为此我们使用基于VGG16和ResNet18的迁移学习,经过两轮训练就可以分别让两个网络模型达到92.8%和93.4%的准确率。这两个网络甚至可以在短时间内使用CPU完成训练。用这种方式,我们节省了大量的时间和设备投入。当然,如果确实有必要,可以重新训练VGG16和ResNet18的参数,这样也许可以得到更好的效果。
试想一下,如何在茫茫人海中寻找可能的犯罪嫌疑人?我的想法是在各个道路口上设置监控,实时检测并获得路上行人的面部照片。然后把这些照片进行解析,并与公安局中的犯罪嫌疑人的照片进行比对。如果对上了,那就表明找到犯罪嫌疑人了。其中解析行人的面部照片的过程就需要用迁移学习实现。那么我们怎么才能通过监控设备提供的视频/照片进行实时检测并获得行人的面部照片呢?请看下一节:物体检测——SSD。
VGG16的迁移学习代码:
import torchimport torch.nn as nn#from torch.nn import functional as Fimport torch.optim as optim#from torch.optim import lr_schedulerfrom torch.utils.data import DataLoaderimport torchvisionfrom torchvision.transforms import transformsfrom torchvision import models#from torchvision.models import ResNet# import numpy as np# import matplotlib.pyplot as pltimport os#import utilsdata_dir = './hymenoptera_data' #图片所在的文件夹train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),transform=transforms.Compose([transforms.RandomResizedCrop(224), #输入图片:224*224transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))]))val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),transform=transforms.Compose([transforms.RandomResizedCrop(224), #输入图片:224*224transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))]))train_dataloader = DataLoader(dataset=train_dataset, batch_size=4, shuffle=4)val_dataloader = DataLoader(dataset=val_dataset, batch_size=4, shuffle=4)# 类别名称class_names = train_dataset.classesprint('class_names:{}'.format(class_names))# 训练设备 CPU/GPUdevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')print('trian_device:{}'.format(device.type))# 定义模型选择,优化方法和学习率策略class Model():def __init__(self):super(Model, self).__init__()self.baseModel = models.vgg16(pretrained=True)#用来迁移学习的VGG16不需要学习,所以要设置不需要梯度for parma in self.baseModel.parameters():parma.requires_grad = False#查看self.baseModel很重要。#我们要替换self.baseModel中最后的全连接层,必须知道这个全连接层的名字是什么print(self.baseModel)#使用自适应平均池化,使参数量减少98%self.baseModel.avgpool = nn.AdaptiveAvgPool2d((1, 1))# 全连接层的输入通道in_features个数# 原先是7 * 7 * 512 = 25088,这里改为1 * 1 * 512 = 512。参数量是原先的1/49。in_features = int(self.baseModel.classifier[0].in_features / 49)#print(in_features)self.baseModel.classifier = nn.Sequential(nn.Linear(in_features, 256),nn.ReLU(),nn.Linear(256, 2))self.baseModel = self.baseModel.to(device)# 模型迁移到CPU/GPUdef forward(self, x):res = self.baseModel(x)return resmodel = Model()print("新的模型:")print(model.baseModel)print("模型结束")# 定义损失函数loss_fc = nn.CrossEntropyLoss()# 选择优化方法optimizer = optim.Adam(model.baseModel.classifier.parameters())#开始训练num_epochs = 2for epoch in range(num_epochs):running_loss = 0.0for i, sample_batch in enumerate(train_dataloader):x = sample_batch[0] #等学习的图片labels = sample_batch[1] # 标签x = x.to(device)# GPU/CPUlabels = labels.to(device)optimizer.zero_grad() #梯度清零outputs = model.forward(x) #前向传播,预测loss = loss_fc(outputs, labels)#计算损失值loss.backward()# loss求导,反向optimizer.step()# 优化running_loss += loss.item()#计算损失# 测试if i % 20 == 19:correct = 0total = 0model.baseModel.eval()for images_test, labels_test in val_dataloader:images_test = images_test.to(device)labels_test = labels_test.to(device)outputs_test = model.forward(images_test)_, prediction = torch.max(outputs_test, 1)correct += (torch.sum((prediction == labels_test))).item()# print(prediction, labels_test, correct)total += labels_test.size(0)print('[{}, {}] running_loss = {:.5f} accurcay = {:.5f}'.format(epoch + 1, i + 1, running_loss / 20,correct / total))running_loss = 0.0# if i % 10 == 9:# print('[{}, {}] loss={:.5f}'.format(epoch+1, i+1, running_loss / 10))# running_loss = 0.0print('training finish !')torch.save(model.baseModel.state_dict(), './model/model_VGG16.pth')
ResNet18的迁移学习的代码:
import torchimport torch.nn as nn# from torch.nn import functional as Fimport torch.optim as optim# from torch.optim import lr_schedulerfrom torch.utils.data import DataLoaderimport torchvisionfrom torchvision.transforms import transformsfrom torchvision import models# from torchvision.models import ResNet# import numpy as np# import matplotlib.pyplot as pltimport os#import utilsdata_dir = './hymenoptera_data' #图片所在的文件夹train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),transform=transforms.Compose([transforms.RandomResizedCrop(224), #输入图片:224*224transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))]))val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),transform=transforms.Compose([transforms.RandomResizedCrop(224), #输入图片:224*224transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))]))train_dataloader = DataLoader(dataset=train_dataset, batch_size=4, shuffle=4)val_dataloader = DataLoader(dataset=val_dataset, batch_size=4, shuffle=4)# 类别名称class_names = train_dataset.classesprint('class_names:{}'.format(class_names))# 训练设备 CPU/GPUdevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')print('trian_device:{}'.format(device.type))# 定义模型选择,优化方法和学习率策略class Model():def __init__(self):super(Model, self).__init__()self.baseModel = models.resnet18(pretrained=True)#用来迁移学习的resnet18不需要学习,所以要设置不需要梯度for parma in self.baseModel.parameters():parma.requires_grad = False#查看self.baseModel很重要。#我们要替换self.baseModel中最后的全连接层,必须知道这个全连接层的名字是什么print(self.baseModel)# 全连接层的输入通道in_features个数in_features = self.baseModel.fc.in_features #512层self.baseModel.fc = nn.Sequential(nn.Linear(in_features, 256),nn.ReLU(),#nn.Dropout(p=0.5),nn.Linear(256, 2))self.baseModel = self.baseModel.to(device)# 模型迁移到CPU/GPUdef forward(self, x):res = self.baseModel(x)return resmodel = Model()print("新的模型:")print(model.baseModel)print("模型结束")# 定义损失函数loss_fc = nn.CrossEntropyLoss()# 选择优化方法optimizer = optim.Adam(model.baseModel.fc.parameters())# 学习率调整策略# 每7个epoch调整一次#exp_lr_scheduler = lr_scheduler.StepLR(optimizer=optimizer, step_size=10, gamma=0.5) # step_size# 开始训练num_epochs = 2for epoch in range(num_epochs):running_loss = 0.0#exp_lr_scheduler.step()for i, sample_batch in enumerate(train_dataloader):x = sample_batch[0] #等学习的图片labels = sample_batch[1] # 标签x = x.to(device)# GPU/CPUlabels = labels.to(device)optimizer.zero_grad() #梯度清零outputs = model.forward(x) #前向传播,预测loss = loss_fc(outputs, labels)#计算损失值loss.backward()# loss求导,反向optimizer.step()# 优化running_loss += loss.item()#计算损失# 测试if i % 20 == 19:correct = 0total = 0model.baseModel.eval()for images_test, labels_test in val_dataloader:images_test = images_test.to(device)labels_test = labels_test.to(device)outputs_test = model.forward(images_test)_, prediction = torch.max(outputs_test, 1)correct += (torch.sum((prediction == labels_test))).item()# print(prediction, labels_test, correct)total += labels_test.size(0)print('[{}, {}] running_loss = {:.5f} accurcay = {:.5f}'.format(epoch + 1, i + 1, running_loss / 20,correct / total))running_loss = 0.0# if i % 10 == 9:# print('[{}, {}] loss={:.5f}'.format(epoch+1, i+1, running_loss / 10))# running_loss = 0.0print('training finish !')torch.save(model.baseModel.state_dict(), './model/model_ResNet18.pth')




























")

")



还没有评论,来说两句吧...