《UPSNet:A Unified Panoptic Segmentation Network》论文笔记
参考代码:UPSNet
1. 概述
导读:在这篇文章中提出了一种端到端的全景分割方法,其在Mask RCNN的基础上通过添加一个语义分割分支,之后使用一个无参数的全景分割预测头使用之前预测头的输出(指的是使用了这部分的参数)经过整合实现全景分割。为了解决语义分割和实例分割之间的冲突,文章在全景分割的预测结果中添加一个未知的类别(文中指出是按照规则选择一定的比例实例作为未知类别),从而使得其在性能指标上表现更佳。
全景分割解决的是实例分割/语义分割融合的方法,这篇文章中将全景分割的目标是否可数性质划分为两个类别:
- 1)目标是可数的(things),这类目标是可数的且具有具体的轮廓信息,诸如行人/车辆等;
- 2)目标是不可数的(stuff),这类目标不可数且具有不固定的轮廓,诸如天空/草地/道路等;
2. 方法设计
2.1 全景分割的pipline
文章的pipline见下图所示: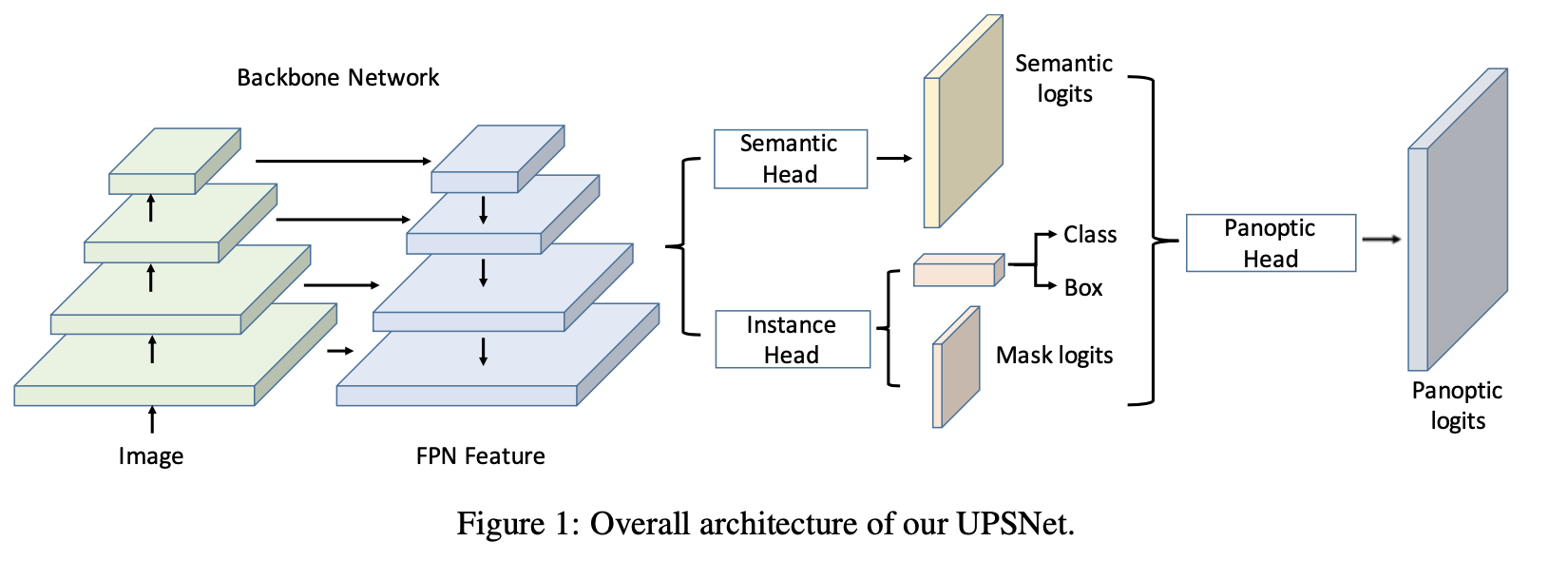
在上图中可以看到文章的方法是在Mask RCNN的基础上添加语义分割分支和全景分割分支实现的,并且通过pipeline上的巧妙设计实现了端到端的训练。
2.2 语义分割分支
语义分割部分使用了FPN输出的特征 [ P 2 , P 3 , P 4 , P 5 ] [P_2,P_3,P_4,P_5] [P2,P3,P4,P5],它们输出的channel都是256,对应的stride为 [ 1 4 , 1 8 , 1 16 , 1 32 ] [\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{32}] [41,81,161,321]。在经过共享参数的可变形卷积block之后将这些特征统一规整到尺寸为原图 1 4 \frac{1}{4} 41的尺度上,之后经过一个1*1的卷积进行输出,其结构见下图所示: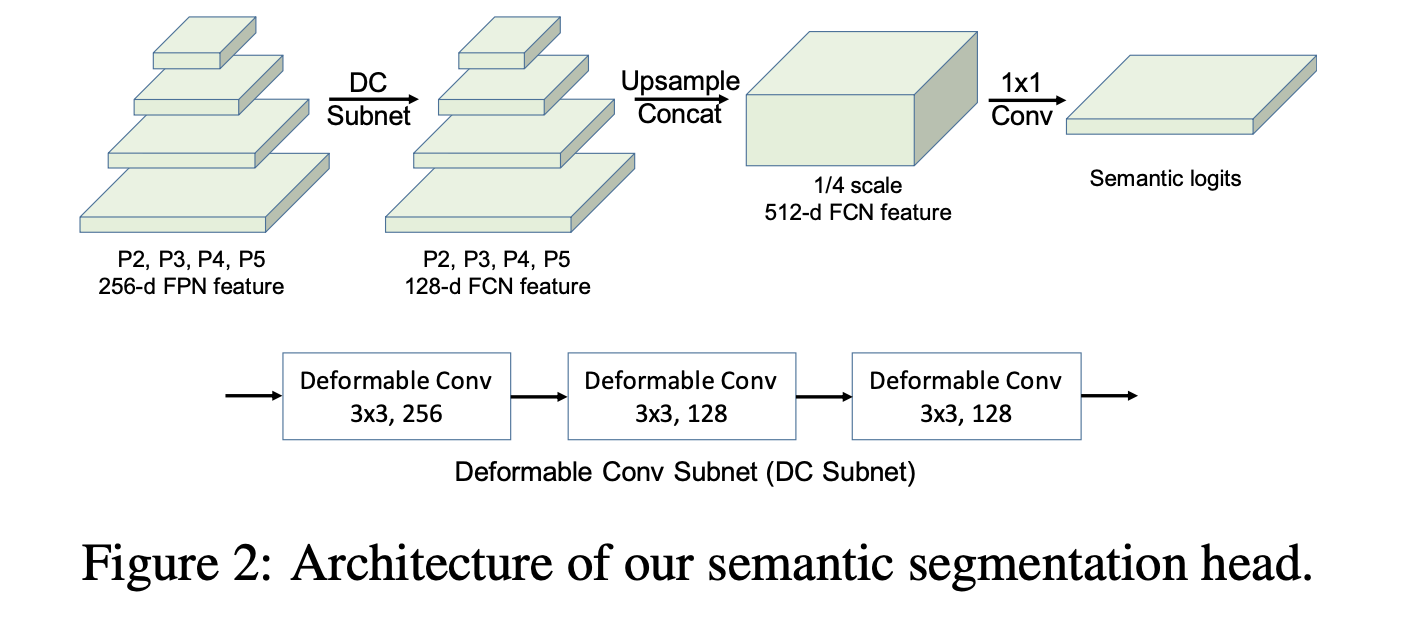
为了增加对分割结果中RoI区域的关注,文章对其引入了RoI Loss就是使用instance GT去crop上面生成的特征,之后使用共享参数的预测头去预测这部分的结果,其输出的预测结果与Mask RCNN头输出的结果大小一致,为28。从而使得网络更加关注RoI区域(但是从文章表6的结果看这部分带来的增益相当小…)。这部分的代码可以参考:
# upsnet/models/fcn.pydef forward(self, fpn_p2, fpn_p3, fpn_p4, fpn_p5, roi=None):# 使用共享参数的可变形卷积进行特征聚合fpn_p2 = self.fcn_subnet(fpn_p2)fpn_p3 = self.fcn_subnet(fpn_p3)fpn_p4 = self.fcn_subnet(fpn_p4)fpn_p5 = self.fcn_subnet(fpn_p5)fpn_p3 = F.interpolate(fpn_p3, None, 2, mode='bilinear', align_corners=False)fpn_p4 = F.interpolate(fpn_p4, None, 4, mode='bilinear', align_corners=False)fpn_p5 = F.interpolate(fpn_p5, None, 8, mode='bilinear', align_corners=False)feat = torch.cat([fpn_p2, fpn_p3, fpn_p4, fpn_p5], dim=1) # 规整到stride=2的尺寸上去# 这里的分割类别数量比实例分割的类别多为133,排列顺序为【stuff+things】,实例为81score = self.score(feat)ret = { 'fcn_score': score, 'fcn_feat': feat}if self.upsample_rate != 1:output = F.interpolate(score, None, self.upsample_rate, mode='bilinear', align_corners=False)ret.update({ 'fcn_output': output})if roi is not None: # 文章中提到的RoI Loss# 输出的大小与mask rcnn实例分割头的结果一致【28,28】roi_feat = self.roipool(feat, roi) # 将特征在instance GT的指引下进行特征图croproi_score = self.score(roi_feat) # 使用共享的预测头进行结果预测ret.update({ 'fcn_roi_score': roi_score})return ret
2.2 全景分割头
语义分割的结果表示为 X X X,其对应的输出channel数量为 N s t u f f + N t h i n g N_{stuff}+N_{thing} Nstuff+Nthing,这个顺序也是其预测结果中的排序。那么按照这个排序可以将语义分割的结果划分为 X s t u f f X_{stuff} Xstuff和 X t h i n g X_{thing} Xthing。对于另外一个实例分割分支,其输出 N i n s t N_{inst} Ninst个(这个数量根据输入图片的内容来确定)实例分割结果 Y Y Y。对于语义分割(COCO下类别为133)和实例分割(COCO下类别为81)它们之间类别的映射关系是为:
# upsnet/operators/modules/unary_logits.pyself.class_mapping = dict(zip(range(1, config.dataset.num_classes), range(num_seg_classes - config.dataset.num_classes + 1, num_seg_classes))) \if class_mapping is None else class_mapping
那么最后的全景分割头其输出的预测结果维度应该是 Z ∈ R ( N s t u f f + N i n s t ) ∗ H ∗ W Z\in R^{(N_{stuff}+N_{inst})*H*W} Z∈R(Nstuff+Ninst)∗H∗W。其整体的处理流程可参考图3所示: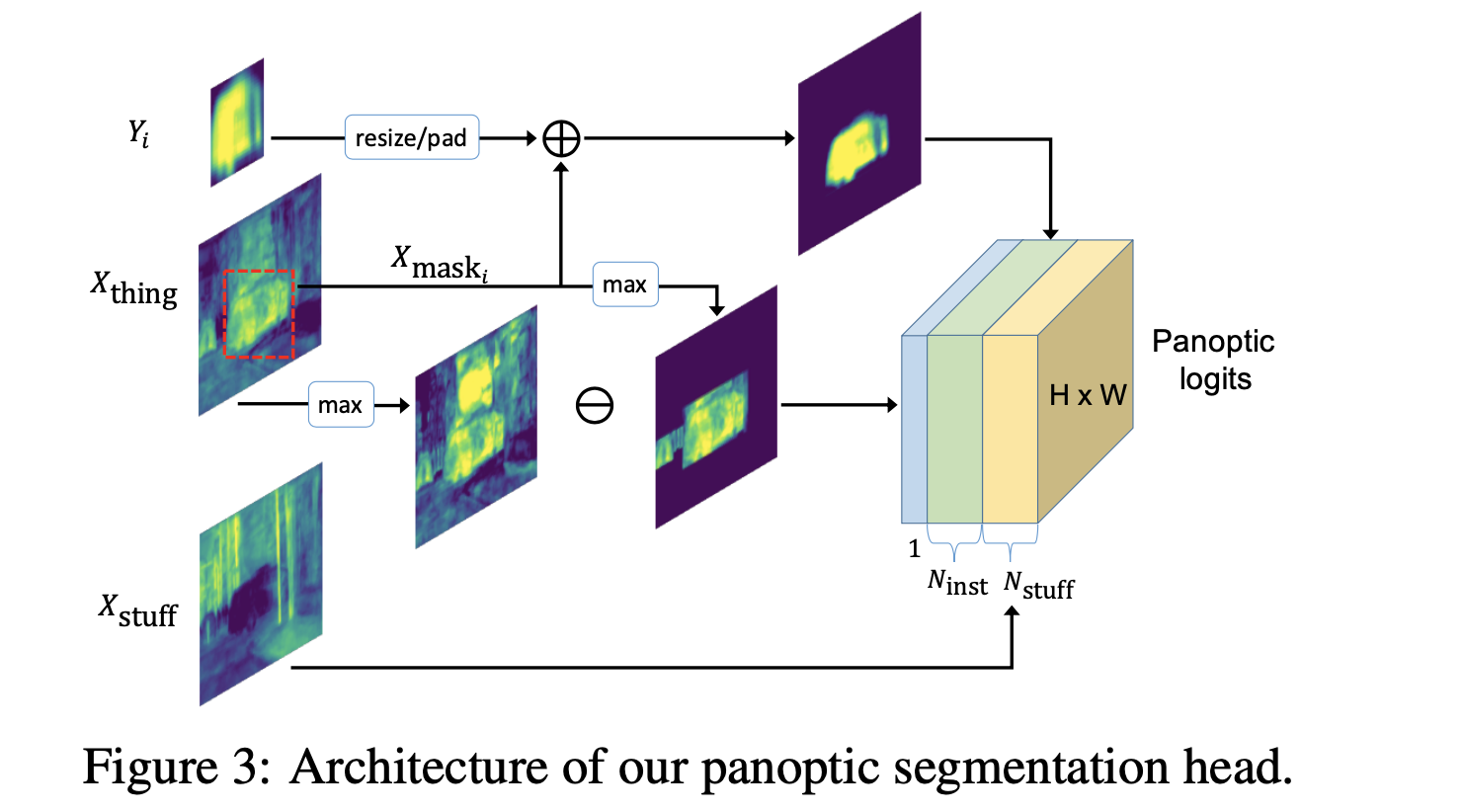
2.2.1 训练时期全景结果的整合
那么具体如何使用如何将语义分割和实例分割的结果进行组合得到最后的全景分割的结果呢?具体体现为下面一节中的几个步骤。
step1:stuff类别的处理
这部分是不可数的类别,直接将其中语义分割的结果中取出即可,不用做额外的操作,这部分描述为图3的最下面那个分支。
step2: thing类别的处理(segterm)
这部分使用GT bbox在经过映射(实例类别到分割类别的映射)类别上进行分割特征图截取从而将 X t h i n g s X_{things} Xthings按照不同的类别截取为不同类别的 X m a s k i X_{mask_{i}} Xmaski,其不同类别的集合描述为 X m a s k X_{mask} Xmask。在bbox之内的像素使用 X t h i n g s X_{things} Xthings中对应类别的信息,而在bbox之外的像素都是填充为0。
step1与step2步骤完成的工作在代码中将其称之为SegTerm,其对应的实现代码为:
# upsnet/operators/modules/unary_logits.pydef forward(self, cls_indices, seg_score, boxes):""" :param cls_indices: [num_boxes x 1] :param seg_score: [1 x num_seg_classes x h x w] :return: seg_energy: [1 x (num_seg_classes - num_inst_classes + num_boxes) x h x w] """assert seg_score.shape[0] == 1, "only support batch size = 1"cls_indices = cls_indices.cpu().numpy()seg_energy = seg_score[[0], :-self.num_inst_classes, :, :] # 取出stuff的分割结果boxes = boxes.cpu().numpy()boxes = boxes[:, 1:] * self.box_scaleif cls_indices.size == 0:return seg_energy, torch.ones_like(seg_energy[[0], [0], :, :]).view(1, 1, seg_energy.shape[2], seg_energy.shape[3]) * -10else:seg_inst_energy = torch.zeros((seg_score.shape[0], cls_indices.shape[0], seg_score.shape[2], seg_score.shape[3]), device=seg_score.device)for i in range(cls_indices.shape[0]):if cls_indices[i] == 0:continuey0 = int(boxes[i][1])y1 = int(boxes[i][3].round()+1)x0 = int(boxes[i][0])x1 = int(boxes[i][2].round()+1)# 在语义分割分支结果的基础上,按照映射的类别在GT BOX的边界引导下对分割特征进行截取seg_inst_energy[0, i, y0: y1, x0: x1] = seg_score[0, self.class_mapping[cls_indices[i]], y0: y1, x0: x1]return seg_energy, seg_inst_energy
step3:实例分割分支的处理(maskterm)
对于语义分割的一个结果 Y i Y_i Yi,其在边界框和分类信息(这里训练的时候使用的GT)的引导下通过resize和padding操作,得到与语义分割相同尺寸大小的分割图,其在代码中对应的部分为MaskTerm。其实现的代码为:
# upsnet/operators/modules/unary_logits.pydef forward(self, masks, boxes, cls_indices, seg_score):""" :param masks: [num_boxes x c x 28 x 28] :param boxes: [num_boxes x 5] :param cls_indices: [num_boxes x 1] :param seg_score: [1 x num_seg_classes x h x w] :return: mask_energy: [1 x num_boxes x h x w] """assert seg_score.shape[0] == 1, "only support batch size = 1"cls_indices = cls_indices.cpu().numpy()# remove first dim which indicate batch idboxes = boxes[:, 1:] * self.box_scaleim_shape = seg_score.shape[2:]# [n x num_boxes x h x w]mask_energy = torch.zeros((seg_score.shape[0], masks.shape[0], seg_score.shape[2], seg_score.shape[3]), device=seg_score.device)for i in range(cls_indices.shape[0]):ref_box = boxes[i, :].long()w = ref_box[2] - ref_box[0] + 1h = ref_box[3] - ref_box[1] + 1w = max(w, 1)h = max(h, 1)mask = F.upsample(masks[i, 0, :, :].view(1, 1, config.network.mask_size, config.network.mask_size), size=(h, w), mode='bilinear', align_corners=False)x_0 = max(ref_box[0], 0)x_1 = min(ref_box[2] + 1, im_shape[1])y_0 = max(ref_box[1], 0)y_1 = min(ref_box[3] + 1, im_shape[0])mask_energy[0, i, y_0:y_1, x_0:x_1] = \mask[0, 0, (y_0 - ref_box[1]):(y_1 - ref_box[1]), (x_0 - ref_box[0]):(x_1 - ref_box[0])]return mask_energy
step4:语义分割与实例分割的结合
这两部分信息的融合是在 Y m a s k i Y_{mask_i} Ymaski和 X m a s k i X_{mask_i} Xmaski上完成的,这里的 i i i代表的是不同的实例,那么将其通过element-wise add的形式组合得到对应实例的分割特征图 Z N s t u f f + i = X m a s k i + Y m a s k i Z_{N_{stuff}+i}=X_{mask_i}+Y_{mask_i} ZNstuff+i=Xmaski+Ymaski。其对应的代码实现描述为:
# upsnet/models/resnet_upsnet.py# Calc panoptic logitsseg_logits, seg_inst_logits = self.seg_term(cls_idx, fcn_output['fcn_score'], gt_rois) # 生成X_maskmask_logits = self.mask_term(mask_score, gt_rois, cls_idx, fcn_output['fcn_score']) # 生成Y_maskinst_logits = seg_inst_logits + mask_logits # X_mask + Y_mask
step5:未知预测部分的处理
这部分文章是为了减少预测错误给性能带来的影响,将那些区域(语义分割结果 X t h i n g X_{thing} Xthing比实例分割结果 Y m a s k Y_{mask} Ymask概率大,对应的区域统计结果显示错失了一些instance)。对此文章中的一个例子:在结果中将行人预测为了自行车,那么对应行人类别的FN会增加,而对应的自行车的FP也会增加,根据下面的性能评估方法:
P Q = ∑ ( p , g ) ∈ T P I o U ( p , g ) ∣ T P ∣ ∣ T P ∣ ∣ T P ∣ + 1 2 ∣ F P ∣ + 1 2 ∣ F N ∣ PQ=\frac{\sum_{(p,g)\in TP}IoU(p,g)}{|TP|}\frac{|TP|}{|TP|+\frac{1}{2}|FP|+\frac{1}{2}|FN|} PQ=∣TP∣∑(p,g)∈TPIoU(p,g)∣TP∣+21∣FP∣+21∣FN∣∣TP∣
则根据上面的公式分母增加了对应的性能得分就会下降,对此文章将其未知的类别,其特征描述被描述为:
Z u n k n o w n = m a x ( X t h i n g ) − m a x ( Y m a s k ) Z_{unknown}=max(X_{thing})-max(Y_{mask}) Zunknown=max(Xthing)−max(Ymask)
其对应的实现代码为:
# upsnet/models/resnet_upsnet.pyvoid_logits =torch.max(fcn_output['fcn_score'][:, (config.dataset.num_seg_classes - config.dataset.num_classes + 1):, ...], dim=1, keepdim=True)[0] -torch.max(seg_inst_logits, dim=1, keepdim=True)[0]
为了在训练的过程中生成未知类别区域的训练标注,文章通过随机采样(比例为30%)的方式进行选择,通过下面方式实现:
# upsnet/models/resnet_upsnet.pyif self.enable_void: # 对全景分割选择GT框中0.7keep_inds = np.random.choice(gt_rois.shape[0], max(int(gt_rois.shape[0] * self.box_keep_fraction), 1), replace=False)gt_rois = gt_rois[keep_inds]cls_idx = cls_idx[keep_inds]
而在测试的过程中是通过实例是否为空和与之前高置信度(按照预测的分类置信度排序)实例的交叠面积判断该区域是否为未知区域,具体实现为:
# upsnet/operators/modules/mask_removal.py# 当前实例的预测为空或者与之前的实例重叠大于fraction_threshold=0.3if mask_sum == 0 or (np.logical_and(mask_image_crop >= 1, crop_mask == 1).sum() / mask_sum > self.fraction_threshold):continue
2.2.2 测试时期类别确立准则
在训练过程中instance的类别是通过GT信息确定的,那么在测试的过程中其类别信息有两个来源:Mask RCNN部分的输出和语义分割部分的输出。对此文章根据这两个部分的输出设计了instance类别确定的策略:
- 1)当语义类别和Mask RCNN类别一致的时候,则使用该一致类别就行;
- 2)当上述两者不一致时,若语义分割计算得到的类别最后为stuff,那么将其设置为stuff类别(这是由于stuff类别具有较高的可信度),否则将其设置为预测instance的类别;
2.2.3 全景分割训练GT的生成
# upsnet/operators/modules/mask_matching.pydef forward(self, gt_segs, gt_masks, keep_inds=None):""" :param gt_segs: [1 x h x w] 语义分割的分割标注 :param gt_masks: [num_gt_boxes x h x w] instance的分割标注 :param keep_inds: [num_kept_boxes x 1] 选中的instance索引 :return: matched_gt: [1 x h x w] 组合之后的全景分割标注 """matched_gt = torch.ones_like(gt_segs) * -1# 取出stuff的分割GT标注matched_gt = torch.where(gt_segs <= config.dataset.num_seg_classes - config.dataset.num_classes, gt_segs, matched_gt)matched_gt = torch.where(gt_segs >= 255, gt_segs, matched_gt)# 取出选中的instanceif keep_inds is not None:gt_masks = gt_masks[keep_inds]# 对选中的instance区域使用instance的GT标注进行赋值for i in range(gt_masks.shape[0]):matched_gt[(gt_masks[[i], :, :] != 0) & (gt_masks[[i], :, :] != 255)] = i + self.num_seg_classes - self.num_inst_classes# 对未被选中的区域进行处理if keep_inds is not None:matched_gt[matched_gt == -1] = self.num_seg_classes - self.num_inst_classes + gt_masks.shape[0]else:matched_gt[matched_gt == -1] = 255return matched_gt
3. 实验结果
MS-COCO数据集: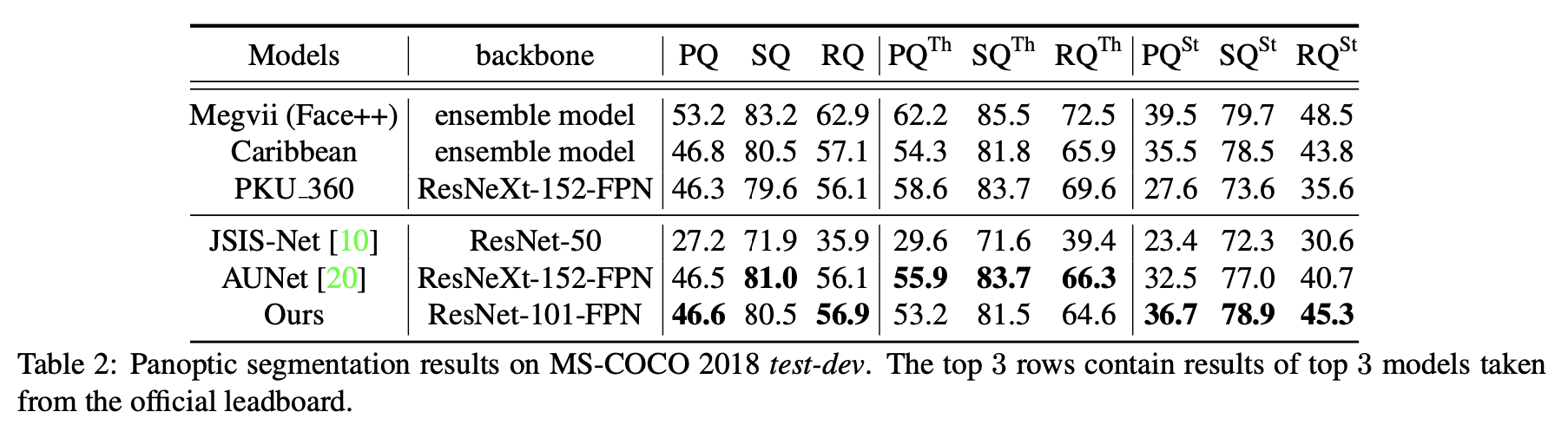
CityScaps数据集: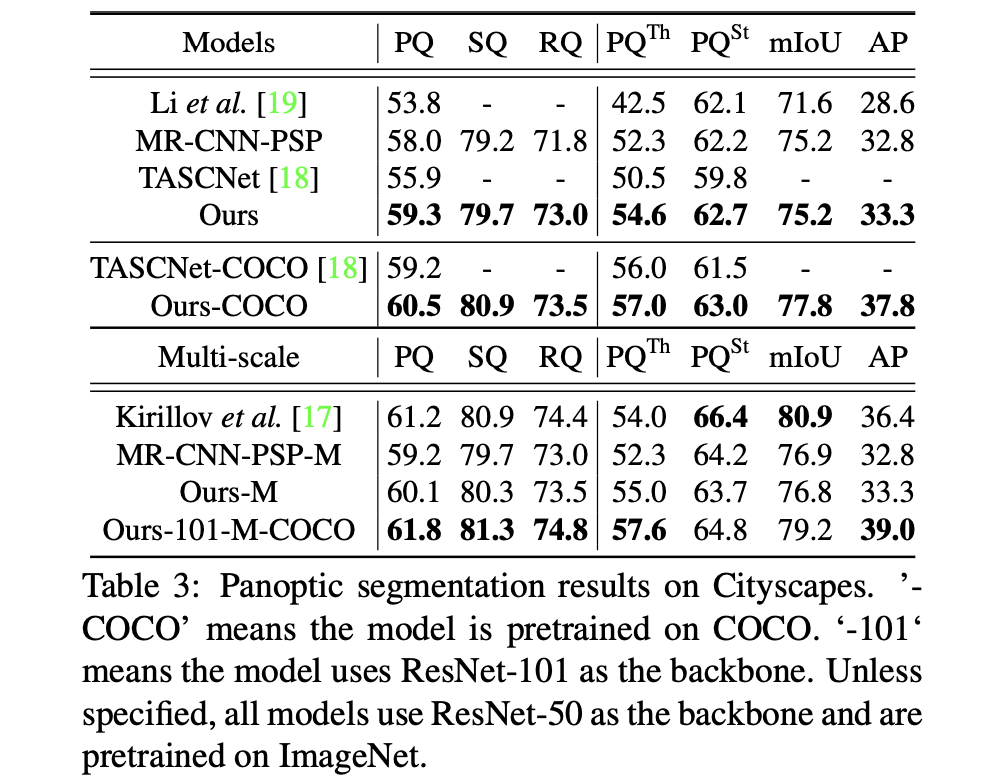
文章各个部分的进行对比的消融实验: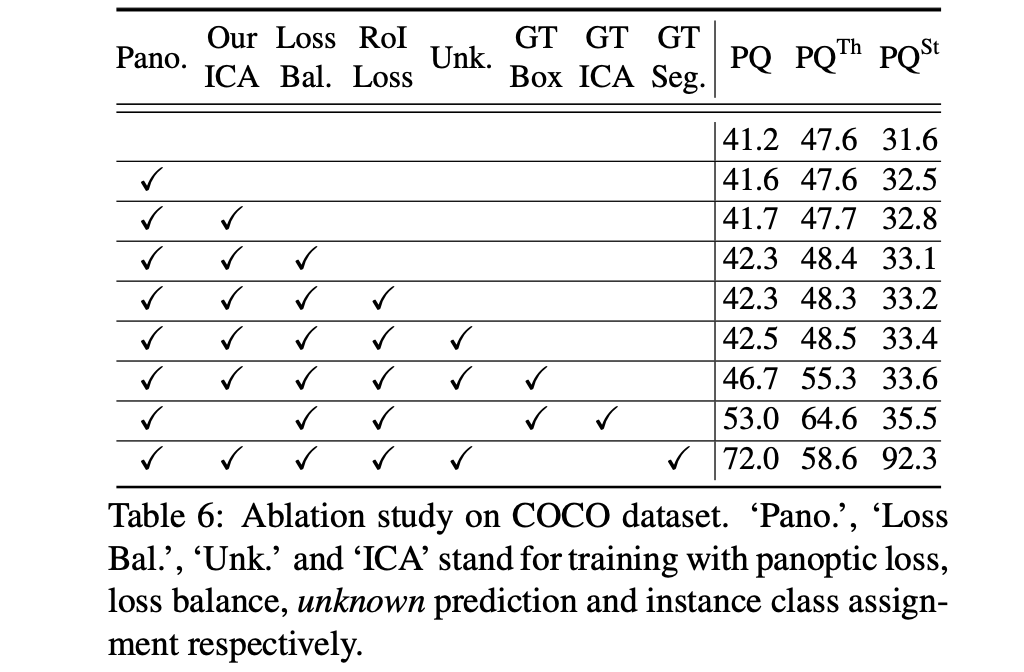



























")


")


还没有评论,来说两句吧...