RocketMQ架构及原理
RocketMQ源于阿里,原名MetaQ,后捐献给apache,支持Java、C/C++、Python、Go;是一款分布式、队列模型的开源消息中间件,经历了几年淘宝双十一的考验。
架构设计核心特性

NameServer
路由中心/注册中心,管理Broker,类似于kafka中的zookeeper,负责Broker节点注册,Producer和Consumer发送和消费消息会先去NameServer中查找可用的Broker节点;Broker节点在启动的时候就会去查找配置文件中有哪些NameServer,然后在所有的NameServer中注册自己建立长连接,之后每隔30秒发送一个心跳告诉NameServer当前节点还存活可用;而NameServer也会定时每隔10秒查看列表中哪些Broker长时间没有发送心跳,如果120秒没有发送心跳就会将Broker从列表中移除。

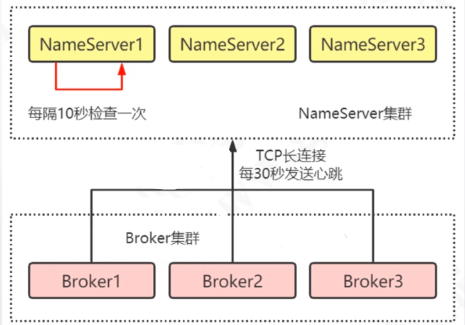
那么RocketMQ为什么不用zookeeper而选择自己造一个NameServer呢?
(1)因为基于RocketMQ的架构设计,他们仅需要一个轻量级的元数据服务器,只需要保证最终一致性,而不需要像zookeeper一样保持强一致。
(2)使用zookeeper担心服务故障,需要考虑高可用问题,需要维护
为什么NameServer之间不需要同步?如何保持一致?
(1)服务注册(Broker新增):每个Broker启动时都会查看配置文件有多少NameServer,然后向所有的NameServer注册自己保证NameServer彼此一致
(2)服务剔除(Broker关闭或宕机):Broker关闭会将自己从所有的NameServer中移除;如果Broker宕机,NameServer会10秒监测一次列表中的Broker是否存活,如果Broker挂了,也会将其移除
(3)路由发现(客户端获取最新的Broker list,初始连接、后续连接):Producer和Consumer会定期每隔30秒刷新一次本地路由列表,通过重试机制可以解决30秒内连接了宕机Broker的问题
生产者
支持同步发送、异步发送、顺序发送、单向发送,同步发送和异步发送都需要broker给一个ack应答,单向发送不需要
生产者消息发送规则
通过MessageQueueSelector实现类来定义发送规则,有以下三个实现类:
SelectMessageQueueByHash(默认):发送消息时,API底层默认使用此规则,根据队列id取绝对值和队列数取余数,然后id自增达到轮询效果
public class SelectMessageQueueByHash implements MessageQueueSelector {public SelectMessageQueueByHash() {}public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {int value = arg.hashCode();if (value < 0) {value = Math.abs(value);}value %= mqs.size();return (MessageQueue)mqs.get(value);}}
SelectMessageQueueByRandom:随机选择一个队列
public class SelectMessageQueueByRandom implements MessageQueueSelector {private Random random = new Random(System.currentTimeMillis());public SelectMessageQueueByRandom() {}public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {int value = this.random.nextInt(mqs.size());return (MessageQueue)mqs.get(value);}}
- SelectMessageQueueByMachineRoom:返回空,没有实现
也可以自定义发送规则(实现MessageQueueSelector接口):
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {Integer id = (Integer) arg;int index = id % mqs.size();return mqs.get(index);}}, i);
顺序消息
- 生产者发送消息时,到达broker是有序的,所以生产者只能用单线程顺序发送
- 写入broker时,要顺序写入,相同主题的消息集中写入,选择同一个message queue,传入相同的hashkey
- 消费者消费的时候只能单线程消费
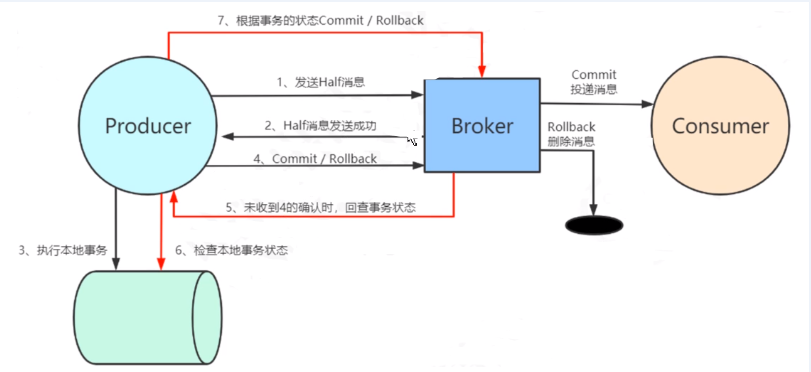
事务消息(两阶段提交)
如何保证数据库操作与MQ消息发送操作要么都成功,要么都回滚?
- 生产者发送消息到broker,把消息状态标记为“未确认”,这个状态的消息无法被消费
- 如果broker可以接收成功,broker通知生产者消息接收成功
- 生产者执行数据库事务操作,并返回执行结果
- 如果事务执行成功,生成者修改消息状态为“确认”,否则丢弃消息
- 如果生产者数据库事务操作没有返回结果,broker主动查询事务执行结果
延迟消息
订单超时未支付自动关闭,怎么实现?
消息设为延迟消息,30分钟之后才发送,然后消费端查询订单是否支付,如果没有支付则关闭订单。
String content = "This is one test message";Message msg = new Message("delay-topic", "tagA", "orderId666", content.getBytes("UTF-8"));msg.setDelayTimeLevel(2); // 不同delay time level不同延迟时间
Broker
做一个中转角色,负责存储消息,转发消息,并且存储元数据(消费者offset)
Topic
表示一类消息的集合,每个主题可以存储很多消息,每个消息都属于一个topic,是rocketmq订阅消息的基本单位。
Tag:消息标签,用于在同一个主题下区分不同类型的消息
Message Queue
类似于Kafka中的partition分区,创建topic时需要指定写队列数量和读队列数量,每一个topic下都可以设置一定数量的消息队列用来数据读取;写队列数量决定了有几个message queue,用来划分存储位置,如果没有配置,服务端默认写队列数量是8,而生产端默认是4个;读队列数量决定了消费者有几个线程来消费这些消息,用来做负载。

MessageQueue有三个属性:
topic:指定当前message queue是属于topic
broker名字:指定存在哪个broker上
queue编号:一个topic下有多个queue,所以需要根据编号来寻找
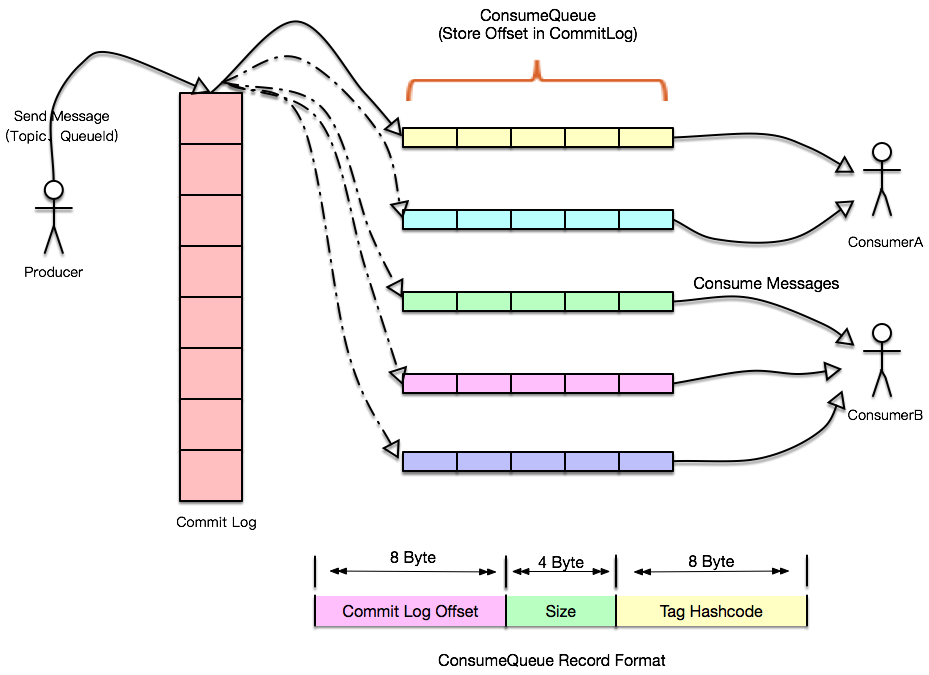
消息如何存储
从下面rocketmq官网图 可以看出,所有发送的消息都存放在commitlog中,集中存储保证顺序性,那么consumer消费时就可以实现顺序消费提升速度;然后由consumequeue来存放每个consumer与其消费的对应offset的对应关系。
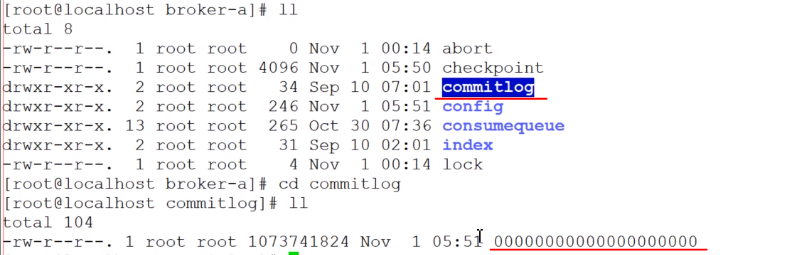
物理存储文件
commitlog:存放所有消息,文件默认最大1G,超过大小后会以最后的offset作为文件名重新创建新的文件
consumequeue:下面有多个文件目录,类似索引,和创建topic时设置的写入队列数量有关,里面记录每个consumer和其消费的Offset的对应关系,每个文件可存30W条记录
checkpoint:文件检查点,记录最后一次刷盘的时间戳
config:运行时配置信息
index:索引存储,可存2000W条记录,大概400M大小
page cache
用户调用数据,需要先从磁盘获取数据copy到内核空间,然后从内核空间copy到用户空间

mmap(memory map)
为了减少数据copy的次数,使用了mmap内存映射来实现内核缓存区与用户缓冲区映射同一块内存地址,避免内核空间与用户空间之间数据的copy
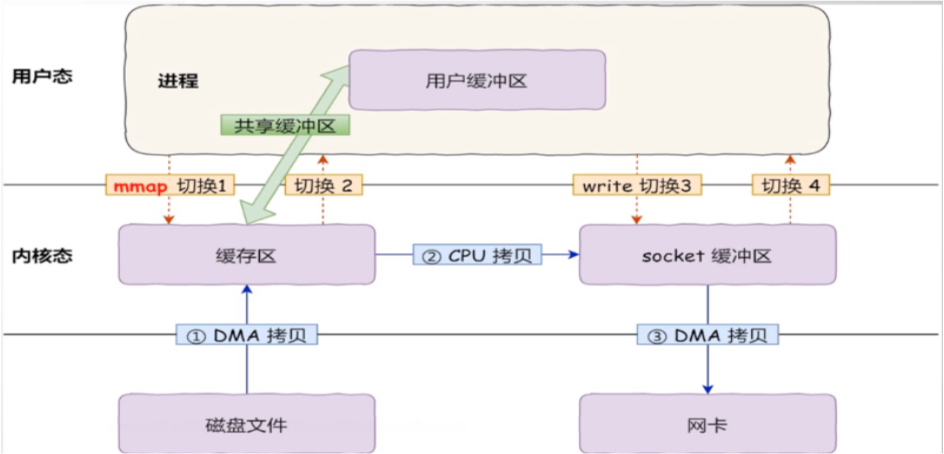
文件清理策略
- 哪些文件需要清理?
commitlog存放数据,consumequeue存放offset,这两个文件需要定期清理 - 文件怎样算是过期文件?
MessageStoreConfig类中有定义fileReservedTime属性,默认保存72小时,超过72小时即为过期 - 过期文件什么时候删除?
MessageStoreConfig类中有定义deleteWhen属性,默认4:00am删除
或者磁盘使用率超过了85%也会批量删除文件,如果磁盘使用率达到90%就会拒绝消息写入,在DefaultMessageStore类中有定义diskSpaceCleanForciblyRatio和diskSpaceWarningLevelRatio两个属性值
消费者
消费模式
- 集群模式:消费者组里的消费者会负载消费不同的消息
广播模式:消费者组里的消费者会将消息全部消费一遍,所有消费者消费一样的消息

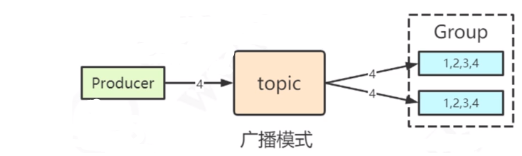
消费模型
RabbitMQ既支持Pull也支持Push,而Kafka只支持Pull;从接口而言RocketMQ也同时支持Pull和Push,但是实际上RocketMQ的Push不是真正的Push,而是通过Pull来实现的,最终启动了一个pull服务
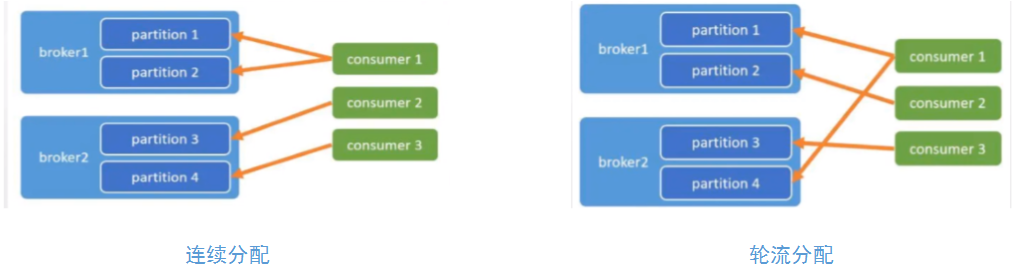
消费端负载均衡与rebalance
- AllocateMessageQueueAveragely:连续分配(默认),类似于kafka的范围分配RangeAssignor策略
- AllocateMessageQueueAveragelyByCircle:每人轮流一个,类似kafka的轮询分配RoundRobinAssignor策略
- AllocateMessageQueueByConfig:通过配置
- AllocateMessageQueueConsistentHash:一致性哈希
- AllocateMessageQueueByMachineRoom:指定一个broker中的topic中的queue消费
- AllocateMachineRoomNearby:按broker的机房就近分配
消费端重试
如果消费失败,通过捕获异常,然后返回ConsumeConcurrentlyStatus.RECONSUME_LATER,那么服务端就会创建一个%RETRY%my_test_consumer_group的队列来保存需要重试的消息实现重试
consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {for(MessageExt msg : msgs){String topic = msg.getTopic();String messageBody="";try {messageBody = new String(msg.getBody(),"utf-8");} catch (UnsupportedEncodingException e) {e.printStackTrace();// 重新消费return ConsumeConcurrentlyStatus.RECONSUME_LATER;}String tags = msg.getTags();SimpleDateFormat sf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");System.out.println("接收时间:" +sf.format(new Date()) + ",topic:"+topic+",tags:"+tags+",msg:"+messageBody);}// 消费成功return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});
死信队列
如果经过了所有的delayTimeLevel,消息仍然消费失败,则会创建一个死信队列%DLQ%topic_name,将重试失败的消息转发到死信队列中
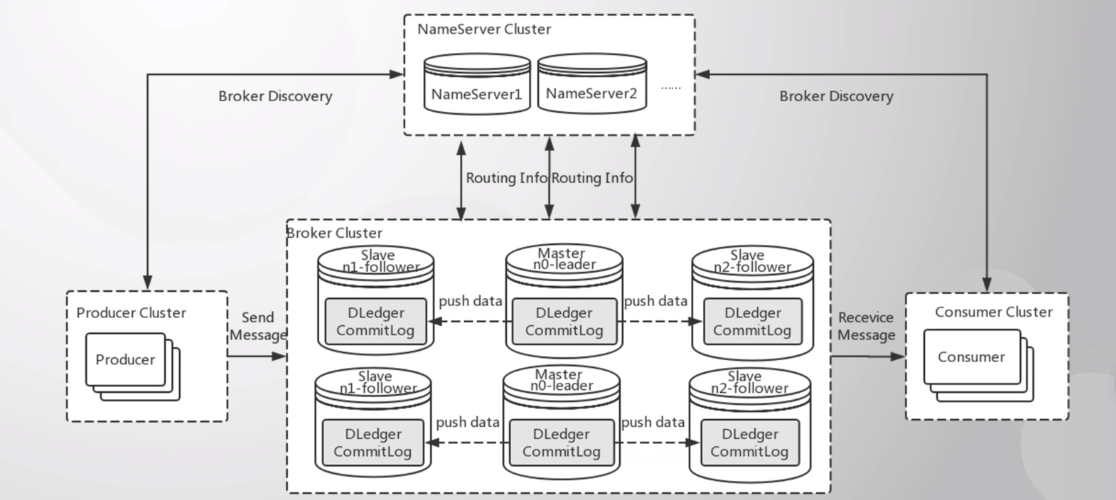
高可用架构
二主二从高可用架构图
在RocketMQ中,Slave节点既可以实现备份,其中有一个Slave还可以实现读写功能,从而分担Master节点的压力
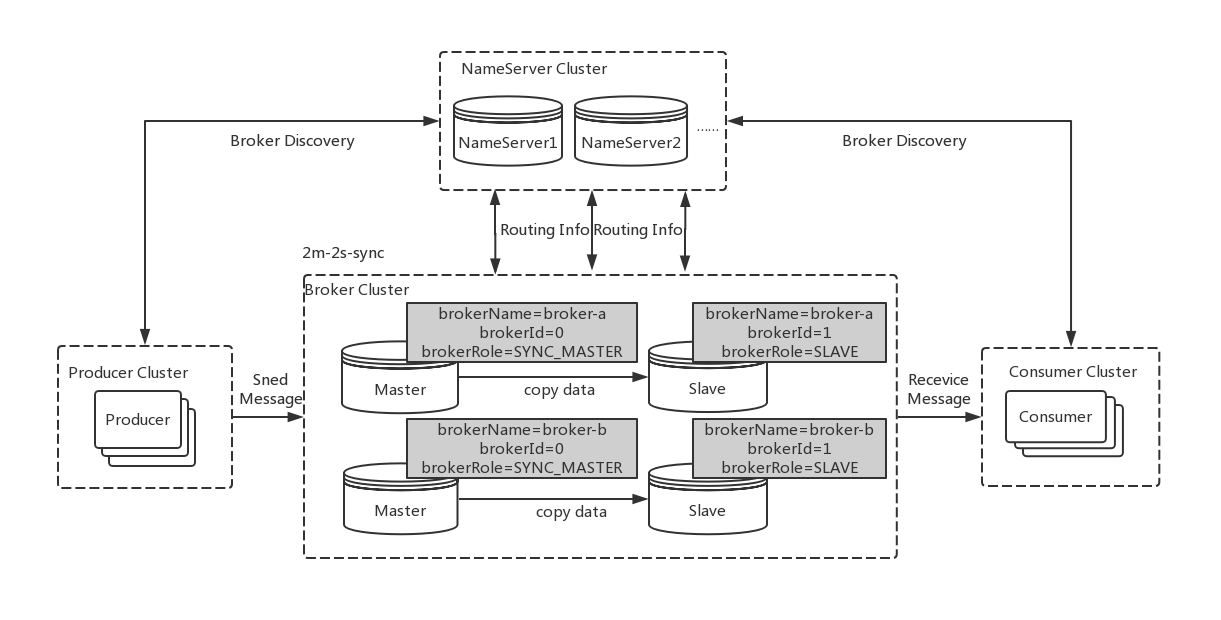
主从怎么关联在一起?
- 集群的名字相同,比如brokerClusterName=lucifer-cluster
- 连接到相同的nameserver
- 在配置文件中,brokerId=0代表是master,brokerId=1代表是slave
主从同步brokerRole
SYNC_MASTER:主从同步双写(推荐),当master和slave都写入成功后才给客户端返回成功
ASYNC_MASTER:主从异步复制,只要master写入成功,就会给客户端返回成功
flushDiskType刷盘类型
ASYNC_FLUSH:异步刷盘(默认),先把消息缓存,直接给producer返回ACK,数据可能丢失
SYNC_FLUSH:同步刷盘,每条消息都保存到磁盘后才返回ACK
主从同步流程
- slave连接到master后,每隔5s向主服务器发送commitLog文件最大偏移量拉取还未同步的消息;
- master收到服务器发送的偏移量进行解析,返回查找出来的未同步的消息给slave;
- slave收到消息后,将消息写入commitLog中,然后更新commmitLog拉去偏移量,接着继续向master拉取未同步的消息。
故障转移(Dledger)
Dledger基于raft协议共识算法, 实现commitLog的存储,实现自动选举,将commitLog都交给Dledger管理,Dledger在rocketmq-4.5.0之后的版本才有,需要开启这个功能才能实现自动选举
Dledger配置
# 是否启动DledgerenableDLegerCommitLog=true# Dledger Raft Group名字dLegerGroup=broker-a# DLedger Group内各节点的地址和端口,至少需要3个节点dLegerPeers=n0-192.168.2.101:10911;n1-192.168.2.102:10911;n2-192.168.2.103:10911;# 本节点IDdLegerSelfId=n0




























还没有评论,来说两句吧...