Hadoop分布式集群安装(非虚拟机)
- 机器
准备三台服务器,网络要通。配置大致如下

- 安装jdk
比较简单,略过了
新增Linux用户hadoop
useradd hadoop
useradd hadoop
输入密码即可
授予root权限
vim /etc/sudoers
增加:

3个节点都执行一遍如上操作
- 免密登入
节点名字:master、slave1、slave2
4.1 3个节点切换到hadoop用户
su hadoop
4.2 分别执行,一直回车
ssh-keygen -t rsa
并将公钥复制为authorized_keys,3个节点都执行
cp ~/.ssh/id_rsa ~/.ssh/authorized_keys
4.3 slave1和slave2中通过scp拷贝 ~/.ssh/authorized_keys到master
如:
scp ~/.ssh/authorized_keys zhangc@master:~/.ssh/authorized_keys_slave1
4.4 在master节点将上边的 authorized_keys_slave1和authorized_keys_slave2 追加到authorized_keys
如:
cd ~/.ssh/cat authorized_keys_slave1 >> authorized_keyscat authorized_keys_slave2 >> authorized_keys
4.5 将master中的~/.ssh/authorized_keys分发到slave1、slave2节点
4.6 然后在slave节点执行
scp ~/.ssh/authorized_keys zhangc@slave1:~/.ssh/authorized_keysscp ~/.ssh/authorized_keys zhangc@slave2:~/.ssh/authorized_keys
参考:https://www.cnblogs.com/20kuaiqian/p/11202330.html
- 下载Hadoop安装包
https://hadoop.apache.org/releases.html
or
https://www.apache.org/dyn/closer.cgi/hadoop/common
解压
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local/bigdata/hadoop
环境变量
vim ~/.bashrcexport PATH=$PATH:/usr/local/bigdata/hadoop/hadoop-3.2.1/bin:/usr/local/bigdata/hadoop/hadoop-3.2.1/sbinsource ~/.bashrc
5.1 配置hadoop-env.sh,内容如下
export JAVA_HOME=/usr/local/jdkexport HDFS_NAMENODE_USER="hadoop"export HDFS_DATANODE_USER="hadoop"export HDFS_SECONDARYNAMENODE_USER="hadoop"export YARN_RESOURCEMANAGER_USER="hadoop"export YARN_NODEMANAGER_USER="hadoop"
5.2 配置core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/local/bigdata/hadoop/tmp</value><description>Abase for other temporary directories.</description></property></configuration>
其中master可以自行改成指定的ip地址,hadoop.tmp.dir记得新建
5.3 配置hdfs-site.xml
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>master:50090</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/bigdata/hadoop/hdfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/bigdata/hadoop/hdfs/data</value></property></configuration>
其中,file路径记得新建好
5.4 配置mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property></configuration>
5.5 配置yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
注:master根据具体情况配置,配置ip也可以
5.6 配置workers
slave1slave2
注:非虚拟机用两个真实ip
复制hadoop文件夹到其他节点
cd ~
sudo tar -zxvf hadoop.master.tar.gz -C /usr/local/
进入 maser的/user/local执行以下命令压缩文件夹
tar -zcf ~/hadoop.master.tar.gz ./bigdata/
进入路径
cd ~

拷贝到slave1和slave2节点
scp ./hadoop.master.tar.gz slave1:/home/hadoop/和scp ./hadoop.master.tar.gz slave2:/home/hadoop/

首次启动先格式化HDFS,一定要在master节点执行
hdfs namenode -format

- 启动
启动前关闭防火墙
进入/usr/local/bigdata/hadoop/hadoop-3.2.1/sbin执行
./start-dfs.sh
master:

slave

./start-yarn.sh
master
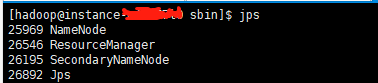
slave


安装成功。。。
查看端口
netstat -nltp
各个端口访问地址https://blog.csdn.net/qq_41851454/article/details/79938811
1、HDFS页面:500702、YARN的管理界面:80883、HistoryServer的管理界面:198884、Zookeeper的服务端口号:21815、Mysql的服务端口号:33066、Hive.server1=100007、Kafka的服务端口号:90928、azkaban界面:84439、Hbase界面:16010,6001010、Spark的界面:808011、Spark的URL:7077
- 异常解决

java.net.BindException: Port in use: master:8088at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1218)at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1240)at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1299)at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1154)at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:439)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1231)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1340)at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1535)Caused by: java.net.BindException: Cannot assign requested addressat sun.nio.ch.Net.bind0(Native Method)at sun.nio.ch.Net.bind(Net.java:436)at sun.nio.ch.Net.bind(Net.java:428)at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:214)at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)at org.eclipse.jetty.server.ServerConnector.openAcceptChannel(ServerConnector.java:351)at org.eclipse.jetty.server.ServerConnector.open(ServerConnector.java:319)at org.apache.hadoop.http.HttpServer2.bindListener(HttpServer2.java:1205)at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1236)... 7 more2020-06-17 13:28:17,806 INFO org.apache.hadoop.service.AbstractService: Service ResourceManager failed in state STARTEDorg.apache.hadoop.yarn.webapp.WebAppException: Error starting http serverat org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:443)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1231)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1340)at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1535)Caused by: java.net.BindException: Port in use: master:8088at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1218)at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1240)at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1299)at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1154)at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:439)... 4 moreCaused by: java.net.BindException: Cannot assign requested addressat sun.nio.ch.Net.bind0(Native Method)at sun.nio.ch.Net.bind(Net.java:436)at sun.nio.ch.Net.bind(Net.java:428)at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:214)at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)at org.eclipse.jetty.server.ServerConnector.openAcceptChannel(ServerConnector.java:351)at org.eclipse.jetty.server.ServerConnector.open(ServerConnector.java:319)at org.apache.hadoop.http.HttpServer2.bindListener(HttpServer2.java:1205)at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1236)... 7 more2020-06-17 13:28:17,810 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioning to standby state2020-06-17 13:28:17,810 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioned to standby state2020-06-17 13:28:17,811 FATAL org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Error starting ResourceManagerorg.apache.hadoop.yarn.webapp.WebAppException: Error starting http serverat org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:443)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1231)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1340)at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1535)Caused by: java.net.BindException: Port in use: master:8088at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1218)at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1240)at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1299)at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1154)at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:439)... 4 moreCaused by: java.net.BindException: Cannot assign requested addressat sun.nio.ch.Net.bind0(Native Method)at sun.nio.ch.Net.bind(Net.java:436)at sun.nio.ch.Net.bind(Net.java:428)at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:214)at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)at org.eclipse.jetty.server.ServerConnector.openAcceptChannel(ServerConnector.java:351)at org.eclipse.jetty.server.ServerConnector.open(ServerConnector.java:319)at org.apache.hadoop.http.HttpServer2.bindListener(HttpServer2.java:1205)at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1236)
这个异常多半是/etc/hosts下的配置有问题,我是把master这个域名直接指定到127.0.0.1就好了,其他的实事求是的看看。
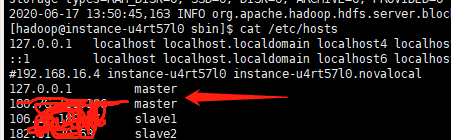
参考:
https://blog.csdn.net/dream_an/article/details/80258283
https://www.cnblogs.com/20kuaiqian/p/11202330.html
http://dblab.xmu.edu.cn/blog/install-hadoop-cluster/


























")

")





还没有评论,来说两句吧...