Java8新特性 - 函数式编程(Lambda)&流操作理解&接口
什么是函数式编程
在思考问题时,使用不可变值和函数,函数对一个值进行处理,映射成另一个值。
书籍《JAVA8函数式编程》
文章目录
- Java中重要的函数接口
- 重要流操作
- 2.1 collect(toList())
- 2.2 map
- 2.3 filter
- 2.4 flatMap
- 2.5 max和min
- 2.6 reduce
- 2.7 转换成其他集合
- 2.8 转换成值
- 2.9 数据分块
- 2.10 数据分组
- 2.11 字符串
- 2.12 组合收集器
- 2.13 重构和定制收集器
- @FunctionalInterface
- 默认方法
- 多重继承
- 其他特性
- 并行化流操作
- 7.1 使用并行流
1. Java中重要的函数接口
依赖于java的类型推断即类型擦除,该阶段是在编译期就完成了的。
了解前四个类型的接口类型即可

Consumer:消费型接口
抽象方法: void accept(T t),接收一个参数进行消费,但无需返回结果。
使用方式:
Consumer consumer = System.out::println;consumer.accept("hello function");
复制代码默认方法: andThen(Consumer<? super T> after),先消费然后在消费,先执行调用andThen接口的accept方法,然后在执行andThen方法参数after中的accept方法。
使用方式:
Consumer<String> consumer1 = s -> System.out.print("车名:"+s.split(",")[0]);Consumer<String> consumer2 = s -> System.out.println("-->颜色:"+s.split(",")[1]);String[] strings = { "保时捷,白色", "法拉利,红色"};for (String string : strings) {consumer1.andThen(consumer2).accept(string);}
输出:
车名:保时捷–>颜色:白色
车名:法拉利–>颜色:红色
Supplier: 供给型接口
抽象方法:T get(),无参数,有返回值。
使用方式:
Supplier<String> supplier = () -> "我要变的很有钱";System.out.println(supplier.get());
最后输出就是“我要变得很有钱”,这类接口适合提供数据的场景。
Function
抽象方法: R apply(T t),传入一个参数,返回想要的结果。
使用方式:
Function<Integer, Integer> function1 = e -> e * 6;System.out.println(function1.apply(2));
很简单的一个乘法例子,显然最后输出是12。
默认方法:
compose(Function<? super V, ? extends T> before),先执行compose方法参数before中的apply方法,然后将执行结果传递给调用compose函数中的apply方法在执行。
使用方式:
Function<Integer, Integer> function1 = e -> e * 2;Function<Integer, Integer> function2 = e -> e * e;Integer apply2 = function1.compose(function2).apply(3);System.out.println(apply2);
还是举一个乘法的例子,compose方法执行流程是先执行function2的表达式也就是33=9,然后在将执行结果传给function1的表达式也就是92=18,所以最终的结果是18。
andThen(Function<? super R, ? extends V> after),先执行调用andThen函数的apply方法,然后在将执行结果传递给andThen方法after参数中的apply方法在执行。它和compose方法整好是相反的执行顺序。
使用方式:
Function<Integer, Integer> function1 = e -> e * 2;Function<Integer, Integer> function2 = e -> e * e;Integer apply3 = function1.andThen(function2).apply(3);System.out.println(apply3);
这里我们和compose方法使用一个例子,所以是一模一样的例子,由于方法的不同,执行顺序也就不相同,那么结果是大大不同的。andThen方法是先执行function1表达式,也就是32=6,然后在执行function2表达式也就是66=36。结果就是36。
**静态方法:**identity(),获取一个输入参数和返回结果相同的Function实例。
使用方式:
Function<Integer, Integer> identity = Function.identity();Integer apply = identity.apply(3);System.out.println(apply);
平常没有遇到过使用这个方法的场景,总之这个方法的作用就是输入什么返回结果就是什么。
Predicate : 断言型接口
抽象方法: boolean test(T t),传入一个参数,返回一个布尔值。
使用方式:
Predicate<Integer> predicate = t -> t > 0;boolean test = predicate.test(1);System.out.println(test);
复制代码当predicate函数调用test方法的时候,就会执行拿test方法的参数进行t -> t > 0的条件判断,1肯定是大于0的,最终结果为true。
默认方法:
and(Predicate<? super T> other),相当于逻辑运算符中的&&,当两个Predicate函数的返回结果都为true时才返回true。
使用方式:
Predicate<String> predicate1 = s -> s.length() > 0;Predicate<String> predicate2 = Objects::nonNull;boolean test = predicate1.and(predicate2).test("&&测试");System.out.println(test);
or(Predicate<? super T> other) ,相当于逻辑运算符中的||,当两个Predicate函数的返回结果有一个为true则返回true,否则返回false。
使用方式:
Predicate<String> predicate1 = s -> false;Predicate<String> predicate2 = Objects::nonNull;boolean test = predicate1.and(predicate2).test("||测试");System.out.println(test);
negate(),这个方法的意思就是取反。
使用方式:
Predicate<String> predicate = s -> s.length() > 0;boolean result = predicate.negate().test("取反");System.out.println(result);
很明显正常执行test方法的话应该为true,但是调用negate方法后就返回为false了。
**静态方法:**isEqual(Object targetRef),对当前操作进行”=”操作,即取等操作,可以理解为 A == B。
使用方式:
boolean test1 = Predicate.isEqual("test").test("test");boolean test2 = Predicate.isEqual("test").test("equal");System.out.println(test1); //trueSystem.out.println(test2); //false
链接:https://juejin.im/post/5d2ff837f265da1bd424b710
2. 重要流操作
什么是流?
流是Java API的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。就现在来说,你可以把它们看成遍历数据集的高级迭代器。此外,流还可以透明地并行处理。
2.1 collect(toList())
List<String> list = Stream.of("a", "b", "c").collect(Collectors.toList());System.out.println(list.toString());
2.2 map
List<String> list = Stream.of("a", "b", "c").map(s -> s.toUpperCase()).collect(Collectors.toList());System.out.println(list.toString());
传给map的Lambda表达式只接受一个String类型的参数,返回一个新的String。参数和返回值不必属于同一种类型,但是Lambda表达式必须是Function接口的一个实例(如图3-4所示),Function接口是只包含一个参数的普通函数接口。
即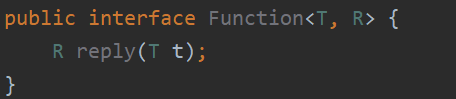

2.3 filter
List<String> list = Stream.of("a", "b", "c").filter(value -> isafirst(value)).collect(Collectors.toList());System.out.println(list.toString());
filter接受一个函数作为参数,该函数用Lambda表达式表示。该函数和前面示例中if条件判断语句的功能一样,如果字符串首字母为数字,则返回true。若要重构遗留代码,for循环中的if条件语句就是一个很强的信号,可用filter方法替代。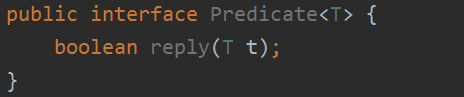

2.4 flatMap
flatMap方法可用Stream替换值,然后将多个Stream连接成一个Stream
List<Integer> list =Stream.of(Arrays.asList(1, 2), Arrays.asList(3, 4)).flatMap(numbers -> numbers.stream()).collect(Collectors.toList());System.out.println(list.toString());
前面已介绍过map操作,它可用一个新的值代替Stream中的值。但有时,用户希望让map操作有点变化,生成一个新的Stream对象取而代之。用户通常不希望结果是一连串的流,此时flatMap最能派上用场。
再来几个例子:
List<Integer> integers = Arrays.asList(1, 2, 3);List<Integer> integers1 = Arrays.asList(4, 5);List<int[]> list = integers.stream().flatMap(x ->integers1.stream().map(m -> new int[]{ x, m})).collect(Collectors.toList());for (int[] i :list) {System.out.println(Arrays.toString(i));}
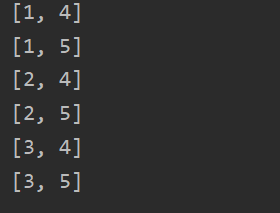
List<Integer> integers = Arrays.asList(1, 2, 3);List<Integer> integers1 = Arrays.asList(4, 5);List<int[]> list = integers.stream().flatMap(x -> integers1.stream().filter(j ->(x + j) % 3 == 0).map(m -> new int[]{ x, m})).collect(Collectors.toList());for (int[] i :list) {System.out.println(Arrays.toString(i));}

2.5 max和min
Stream上常用的操作之一是求最大值和最小值。
Integer integer = Arrays.asList(1, 2, 3, 4, 5).stream().max(Comparator.comparing(x -> x)).get();System.out.println(integer);

为了让Stream对象按照曲目长度进行排序,需要传给它一个Comparator对象。Java 8提供了一个新的静态方法comparing,使用它可以方便地实现一个比较器。
2.6 reduce
reduce操作可以实现从一组值中生成一个值。在上述例子中用到的count、min和max方法,因为常用而被纳入标准库中。事实上,这些方法都是reduce操作。
Integer reduce = Stream.of(1, 2, 3).reduce(0, (acc, element) -> acc + element);System.out.println(reduce);
Lambda表达式就是reducer,它执行求和操作,有两个参数:传入Stream中的当前元素和acc。将两个参数相加,acc是累加器,保存着当前的累加结果。
其中BinaryOperator:
BinaryOperator<Long> add =(x,y)->x+y+1;System.out.println(add.apply(1L,2L)); //结果为4//展开 reduce 操作BinaryOperator<Integer> acount =(acc, elment) -> acc + elment;Integer apply = acount.apply(acount.apply(acount.apply(0, 1), 2), 3);System.out.println(apply);
reduce接受两个参数:
- 一个初始值,这里是0;
- 一个BinaryOperator来将两个元素结合起来产生一个新值,这里用的是lambda (a,b)-> a + b。
把流中每个元素都映射成数字1,然后用reduce求和。这相当于按顺序数流中的元素个数。
Integer integer = integers.stream().map(x -> 1).reduce(0, (a, b) -> a + b);System.out.println(integer);
还可以用count:
long count = integers.stream().count();System.out.println(count);
归约方法的优势与并行化
传递给reduce的Lambda不能更改状态(如实例变量),而且操作必须满足结合律才可以按任意顺序执行。
2.7 转换成其他集合
List<Integer> list = Arrays.asList(1, 2, 3, 4, 4, 5, 1);Set<Integer> set = list.stream().collect(Collectors.toSet());System.out.println(set.toString());
2.8 转换成值
List<Integer> list = Arrays.asList(1, 2, 3, 4, 4, 5, 1);Optional<Integer> max = list.stream().collect(Collectors.maxBy(Comparator.comparingInt(x -> x)));Optional<Integer> min = list.stream().collect(Collectors.minBy(Comparator.comparingInt(x -> x)));System.out.println(max);System.out.println(min);private static boolean isga3(int a) {return a > 3 ? true : false;}
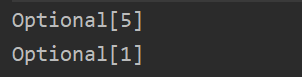
2.9 数据分块
收集器partitioningBy,它接受一个流,并将其分成两部分。它使用Predicate对象判断一个元素应该属于哪个部分,并根据布尔值返回一个Map到列表。因此,对于true List中的元素,Predicate返回true;对其他List中的元素,Predicate返回false。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 4, 5, 1);Map<Boolean, List<Integer>> collect =list.stream().collect(Collectors.partitioningBy(x -> isga3(x)));System.out.println(collect.toString());

还可以好好体味一下下面这个例子:
这个属于多级分块:
Map<Boolean, Map<Boolean, List<Integer>>> collect =integers.stream().collect(Collectors.partitioningBy(x -> isga3(x), Collectors.partitioningBy(y -> isga3(y))));System.out.println(collect.toString());

如果x小于3的分组出来false,接着将这个小于3的分组接着比较一次再进行一次分组,形成了一层嵌套;
2.10 数据分组
数据分组是一种更自然的分割数据操作,与将数据分成ture和false两部分不同,可以使用任意值对数据分组。
List<Integer> list = Arrays.asList(1, 2, 2, 2, 2, 2, 2, 3, 3, 4, 5, 3, 4, 4, 5, 1);Map<Integer, List<Integer>> collect =list.stream().collect(Collectors.groupingBy(x -> x));//以x 分组如果式对象 x.getxxxxSystem.out.println(collect.toString());
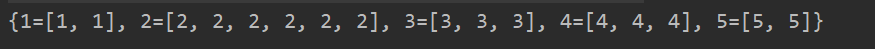
看看groupingBy:
再来一个嵌套:
Map<Integer, Long> collect = list.stream().collect(Collectors.groupingBy(x -> x, Collectors.counting()));//以x 分组如果式对象 x.getxxxxSystem.out.println(collect);

2.11 字符串
该方法可以方便地从一个流得到一个字符串,允许用户提供分隔符(用以分隔元素)、前缀和后缀。

2.12 组合收集器
就是将之前的组合起来更加强大
List<Integer> list = Arrays.asList(1, 2, 3, 4, 4, 5, 1);Map<Integer, List<Integer>> map = list.stream().collect(Collectors.toSet()).stream().collect(Collectors.groupingBy(x -> x));System.out.println(map.toString());

。。。。
2.13 重构和定制收集器
…基本用不到
3. @FunctionalInterface
该注释会强制javac检查一个接口是否符合函数接口的标准。如果该注释添加给一个枚举类型、类或另一个注释,或者接口包含不止一个抽象方法,javac就会报错。重构代码时,使用它能很容易发现问题。
即一个接口用作函数式接口的时候应该给该接口注解上@FunctionalInterface
4. 默认方法
Java 8中为Collection接口增加了stream方法,这意味着所有实现了Collection接口的类都必须增加这个新方法。对核心类库里的类来说,实现这个新方法(比如为ArrayList增加新的stream方法)就能就能使问题迎刃而解。缺憾在于,这个修改依然打破了二进制兼容性,在JDK之外实现Collection接口的类,例如MyCustomList,也仍然需要实现新增的stream方法。这个MyCustomList在Java 8中无法通过编译,即使已有一个编译好的版本,在JVM加载MyCustomList类时,类加载器仍然会引发异常。
这是所有使用第三方集合类库的梦魇,要避免这个糟糕情况,则需要在Java 8中添加新的语言特性:默认方法
Java 8通过如下方法解决该问题:Collection接口告诉它所有的子类:“如果你没有实现stream方法,就使用我的吧。” 接口中这样的方法叫作默认方法
看如下例子:
@FunctionalInterfacepublic interface DefaultInterfacedemo {void sayhello(String msg);default void say(){sayhello("nihao啊");}}public static void main(String[] args) {DefaultInterfacedemo interfacedemo = new DefaultInterfacedemo() {//匿名类@Overridepublic void sayhello(String msg) {System.out.println(msg + "重载");}};interfacedemo.say();}
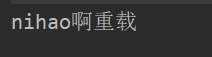
但是这样会出现一个问题:
如果类中的方法与默认方法冲突,那么该怎么解决呢?
类中的方法优先;
因为假设已实现了一个定制的列表MyCustomList,该类中有一个addAll方法,如果新的List接口也增加了一个默认方法addAll,该方法将对列表的操作代理到add方法。如果类中重写的方法没有默认方法的优先级高,那么就会破坏已有的实现。
interface ChildDefault extends DefaultInterfacedemo {@Overridedefault void say() {sayhello("child");}}static class A implements ChildDefault {@Overridepublic void sayhello(String msg) {System.out.println(msg);}@Overridepublic void say() {sayhello("A Say");}}public static void main(String[] args) {A a = new A();ChildDefault childDefault = new A();childDefault.say();DefaultInterfacedemo defaultInterfacedemo = new A();defaultInterfacedemo.say();a.say();}

5. 多重继承
1.类胜于接口。如果在继承链中有方法体或抽象的方法声明,那么就可以忽略接口中定义的方法。
2.子类胜于父类。如果一个接口继承了另一个接口,且两个接口都定义了一个默认方法,那么子类中定义的方法胜出。
3. 没有规则三。如果上面两条规则不适用,子类要么需要实现该方法,要么将该方法声明为抽象方法。
6. 其他特性
Optional判空:首先,Optional对象鼓励程序员适时检查变量是否为空,以避免代码缺陷;其次,它将一个类的API中可能为空的值文档化,这比阅读实现代码要简单很多。
接口的静态方法:如果一个方法有充分的语义原因和某个概念相关,那么就应该将该方法和相关的类或接口放在一起,而不是放到另一个工具类中。
方法引用:
标准语法为Classname::methodName。需要注意的是,虽然这是一个方法,但不需要在后面加括号,因为这里并不调用该方法。我们只是提供了和Lambda表达式等价的一种结构,在需要时才会调用。凡是使用Lambda表达式的地方,就可以使用方法引用。
x -> x.getxx
x :: getxx
7. 并行化流操作
对收集源调用parallel-Stream方法就能将集合转换为并行流。并行流就是一个把内容拆分成多个数据块,用不同线程分别处理每个数据块的流。这样一来,你就可以自动地把工作负荷分配到多核处理器的所有核,让它们都忙起来。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 4, 5, 1);Map<Integer, List<Integer>> collect = list.parallelStream().collect(Collectors.groupingBy(x -> x));System.out.println(collect.toString());List<Integer> list = Arrays.asList(1, 2, 3, 4, 4, 5, 1);int sum = list.parallelStream().mapToInt(x -> x).sum();System.out.println(sum);
其底层实现原理是:fork-join 解决问题:
7.1 使用并行流
注意:使用算法改变了某些共享状态,即存在线程安全;
- 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8中有原始类型流(IntStream、LongStream和DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
- 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8中有原始类型流(IntStream、LongStream和DoubleStream)来避免这种操作,但凡有可能都应该用这些流。(maptoint)
- 还要考虑流的操作流水线的总计算成本。
- 对于较小的数据量,不要选择并行流。
适合于并行的数据源:
但估计一般用不到并行流。




























还没有评论,来说两句吧...