Structure streaming-去除重复数据
根据唯一的 id 实现数据去重.意思就是输出过的id,下次再次输入就不会显示了
数据`
1,2019-09-14 11:50:00,dog12,2019-09-14 11:51:00,dog21,2019-09-14 11:55:00,dog33,2019-09-14 11:53:00,dog41,2019-09-14 11:50:00,dog54,2019-09-14 11:45:00,dog6import java.sql.Timestampimport org.apache.spark.sql.SparkSessionobject Drop {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("Test").getOrCreate()import spark.implicits._val lines = spark.readStream.format("socket").option("host", "hadoop102").option("port", 10001).load()val words = lines.as[String].map(line => {val arr = line.split(",")(arr(0), Timestamp.valueOf(arr(1)), arr(2))}).toDF("uid", "ts", "word")val wordcount = words.withWatermark("ts", "2 minutes").dropDuplicates("uid")wordcount.writeStream.outputMode("append").format("console").start().awaitTermination()}}
第一批

第二批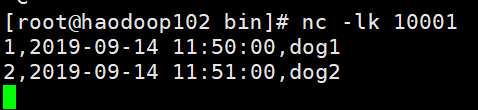
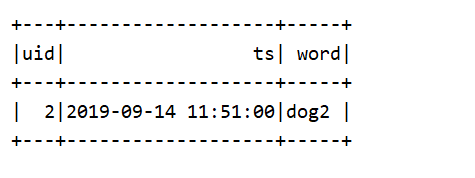
第三批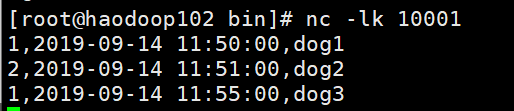
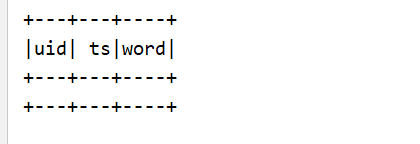
id 重复无输出
第 4 批: 3,2019-09-14 11:53:00,dog
省略
第 5 批: 1,2019-09-14 11:50:00,dog 数据重复, 并且数据过期, 所以无输出
第 6 批 4,2019-09-14 11:45:00,dog 数据过时, 所以无输出注意
注意:
- dropDuplicates 不可用在聚合之后, 即通过聚合得到的 df/ds 不能调用 dropDuplicates
- 使用 watermask - 如果重复记录的到达时间有上限,则可以在事件时间列上定义水印, 并使用guid和事件时间列进行重复数据删除。该查询将使用水印从过去的记录中删除旧 的状态数据,这些记录不会再被重复。这限制了查询必须维护的状态量。
- 没有 watermask - 由于重复记录可能到达时没有界限,查询将来自所有过去记录的数据 存储为状态。





























")




还没有评论,来说两句吧...