Linux性能优化 CPU性能调优
Linux性能优化 CPU性能调优(一)
系统的平均负载
可以通过uptime命令查看系统的平均负载: (top命令可以也可以,不过显示信息更多)
$ uptime10:35:08 up 23 days, 19:29, 3 users, load average: 0.11, 0.07, 0.06
执行uptime命令,可以看到 当前时间、系统运行时间以及正在登录用户数。后面是过去 1 分钟、5 分钟、15 分钟的平均负载。
通过man uptime看一下到底什么是平均负载:
System load averages is the average number of processes that are either in a runnable or uninterruptable state.
A process in a runnable state is either using the CPU or waiting to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk.
Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time.
也就是说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。
- 可运行状态:使用CPU或者正在等待使用CPU的进程所处的状态
- 不可中断状态:进程在等待硬件设备IO等时的状态,这些进程不可打断,用kill也不能消灭。 ps状态下是D状态的进程。当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。也就是说这是一种保护机制。 (当一个机器的D状态进程较多,通常是有一些问题的)
因此,想通过平均负载来看系统的繁忙情况,需要知道自己的系统有多少个CPU 【可以通过top或者查看/proc/cpuinfo查看】。如果是单CPU并且平均负载是1,这说明CPU一直被占用。如果是4CPU的机器平均负载是1的话,说明CPU的75%是空闲的。如果是单CPU平均负载是4,那么说明大部分进程都是在竞争CPU并且竞争不到的。
一般当平均负载高于CPU数量的0.7时,就说明可能是存在问题导致高负载了,高于1的话就需要找一下问题修复了,如果更高的话可能导致响应慢等情况了。
一般来说CPU的使用率和平均负载的关系如下:
- 对于CPU 密集型进程,会单位时间使用大量 CPU ,因此平均负载会较大,这种情况二者是较为一致的
- 对于IO密集型进程,大部分时间都在等待IO,因此平均负载也会比较大,但是CPU使用率是比较低的
案例分析
工具:stress (系统压力测试工具)和sysstat (监控分析系统性能的工具) 下载方法:用yum install 即可 或者 apt-get install
环境:Xshell连接的Linux远程主机,版本3.10
需要开启多个终端,部分终端用于运行监测程序,部分终端用来运行实例模拟高负载 【虚拟机图形界面的话可以创建多个命令行即可,远程Linux则建立多个连接窗口即可】
可以看一下man stress,可以模拟多种系统压力施加
模拟高CPU密集的进程
stress -c 4 #运行4个高CPU进程
在一个终端运行stress,另外的终端用于监视系统负载以及其他性能
top监视的情况:
[root@jessy ~]# toptop - 14:33:58 up 23 days, 23:28, 4 users, load average: 4.28, 1.42, 0.54Tasks: 118 total, 6 running, 111 sleeping, 1 stopped, 0 zombie%Cpu(s): 99.7 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 stKiB Mem : 8008684 total, 5493028 free, 195948 used, 2319708 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 7506152 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3128 root 20 0 7312 96 0 R 99.3 0.0 1:25.59 stress 3126 root 20 0 7312 96 0 R 99.0 0.0 1:25.34 stress 3127 root 20 0 7312 96 0 R 99.0 0.0 1:25.38 stress 3129 root 20 0 7312 96 0 R 96.7 0.0 1:24.92 stress 3146 root 20 0 159952 2200 1500 R 0.7 0.0 0:00.13 top
可以看到平均负载逐步上升接近到4,并且可以看到有4个CPU使用率接近100%的进程,平均CPU使用率几乎达到100%,几乎所有的时间都在用户态
mpstat监视情况:
[root@jessy ~]# mpstat -P ALL 5 1Linux 3.10.0-1062.18.1.el7.x86_64 (jessy) 07/22/2020 _x86_64_ (4 CPU)02:32:47 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle02:32:52 PM all 99.74 0.00 0.19 0.00 0.00 0.06 0.00 0.00 0.00 0.0002:32:52 PM 0 99.44 0.00 0.28 0.00 0.00 0.28 0.00 0.00 0.00 0.0002:32:52 PM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0002:32:52 PM 2 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0002:32:52 PM 3 99.42 0.00 0.29 0.00 0.00 0.29 0.00 0.00 0.00 0.00Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idleAverage: all 99.74 0.00 0.19 0.00 0.00 0.06 0.00 0.00 0.00 0.00Average: 0 99.44 0.00 0.28 0.00 0.00 0.28 0.00 0.00 0.00 0.00Average: 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00Average: 2 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00Average: 3 99.42 0.00 0.29 0.00 0.00 0.29 0.00 0.00 0.00 0.00
mpstst可以看到每个cpu 的情况,可知每个CPU都有接近100%的使用率
pidstat监视的情况:
[root@jessy ~]# pidstat 1 1Linux 3.10.0-1062.18.1.el7.x86_64 (jessy) 07/22/2020 _x86_64_ (4 CPU)02:37:07 PM UID PID %usr %system %guest %CPU CPU Command02:37:08 PM 0 3126 99.01 0.00 0.00 99.01 1 stress02:37:08 PM 0 3127 100.00 0.00 0.00 100.00 2 stress02:37:08 PM 0 3128 98.02 0.00 0.00 98.02 3 stress02:37:08 PM 0 3129 99.01 0.00 0.00 99.01 0 stress02:37:08 PM UID PID %usr %system %guest %CPU CPU Command02:37:09 PM 0 3126 99.01 0.00 0.00 99.01 1 stress02:37:09 PM 0 3127 98.02 0.00 0.00 98.02 2 stress02:37:09 PM 0 3128 100.00 0.00 0.00 100.00 3 stress02:37:09 PM 0 3129 99.01 0.00 0.00 99.01 0 stress02:37:09 PM 0 3608 0.99 0.00 0.00 0.99 0 barad_agent02:37:09 PM 0 4242 0.00 0.99 0.00 0.99 1 pidstat
可以看到CPU被跑的满满的,并且可以看到是哪些进程在占据CPU
通过top和pidstat都可以找到到底是哪些进程在使CPU繁忙,因此找到根源后便可以去找更细的原因。
模拟IO密集型的进程
stress -i 3 #运行3个高IO进程
在一个终端运行stress,另外的终端用于监视系统负载以及其他性能
top监视的情况:
[root@jessy ~]# toptop - 11:37:16 up 23 days, 20:31, 4 users, load average: 3.00, 3.21, 2.85Tasks: 108 total, 3 running, 104 sleeping, 1 stopped, 0 zombie%Cpu(s): 0.2 us, 49.0 sy, 0.0 ni, 49.9 id, 0.9 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 8008684 total, 5492672 free, 187984 used, 2328028 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 7514116 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 562 root 20 0 7312 100 0 R 87.7 0.0 4:37.80 stress 563 root 20 0 7312 100 0 D 54.8 0.0 4:45.89 stress 561 root 20 0 7312 100 0 R 51.5 0.0 4:38.76 stress 3612 root 20 0 611472 15896 2376 S 2.0 0.2 101:22.29 barad_agent 9 root 20 0 0 0 0 S 0.3 0.0 3:31.87 rcu_sched 1554 root 20 0 0 0 0 S 0.3 0.0 0:00.16 kworker/u8:2
可以看到系统负载接近3,但是CPU利用率并没有那么高,并且可以看到 D 状态 (不可中断状态)
mpstat监视的情况:
[root@jessy ~]# mpstat -P ALL 5 1Linux 3.10.0-1062.18.1.el7.x86_64 (jessy) 07/22/2020 _x86_64_ (4 CPU)11:31:29 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle11:31:34 AM all 0.05 0.00 52.10 1.05 0.00 0.00 0.00 0.00 0.00 46.7911:31:34 AM 0 0.00 0.00 96.01 2.00 0.00 0.00 0.00 0.00 0.00 2.0011:31:34 AM 1 0.20 0.00 39.40 1.00 0.00 0.00 0.00 0.00 0.00 59.4011:31:34 AM 2 0.20 0.00 41.20 0.80 0.00 0.00 0.00 0.00 0.00 57.8011:31:34 AM 3 0.20 0.00 31.34 0.60 0.00 0.00 0.00 0.00 0.00 67.86Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idleAverage: all 0.05 0.00 52.10 1.05 0.00 0.00 0.00 0.00 0.00 46.79Average: 0 0.00 0.00 96.01 2.00 0.00 0.00 0.00 0.00 0.00 2.00Average: 1 0.20 0.00 39.40 1.00 0.00 0.00 0.00 0.00 0.00 59.40Average: 2 0.20 0.00 41.20 0.80 0.00 0.00 0.00 0.00 0.00 57.80Average: 3 0.20 0.00 31.34 0.60 0.00 0.00 0.00 0.00 0.00 67.86
可以看到iowait值非常高,说明IO才是当前系统负载高的主要原因,同时可以看到主要事件消耗在于系统调用上,因为IO是需要系统调用的,用户态几乎不占时间。
pidstat查看相关状态:
[root@jessy ~]# pidstat 1 1Linux 3.10.0-1062.18.1.el7.x86_64 (jessy) 07/22/2020 _x86_64_ (4 CPU)02:39:56 PM UID PID %usr %system %guest %CPU CPU Command02:39:57 PM 0 4719 0.00 61.00 0.00 61.00 0 stress02:39:57 PM 0 4720 0.00 81.00 0.00 81.00 1 stress02:39:57 PM 0 4721 0.00 50.00 0.00 50.00 2 stress02:39:57 PM 0 4926 0.00 1.00 0.00 1.00 3 pidstat02:39:57 PM UID PID %usr %system %guest %CPU CPU Command02:39:58 PM 0 4719 0.00 59.00 0.00 59.00 0 stress02:39:58 PM 0 4720 0.00 42.00 0.00 42.00 3 stress02:39:58 PM 0 4721 0.00 94.00 0.00 94.00 2 stress02:39:58 PM 0 32473 0.00 1.00 0.00 1.00 3 YDService
可以看到具体的进程占据CPU和IO的情况
通过top或者pidstat可以找到具体是哪个进程在频繁IO,从而定位问题原因
上下文切换
Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行,这是通过频繁的上下文切换、将CPU轮流分配给不同任务从而实现的。
每个进程运行时,CPU都需要知道进程已经运行到了哪里以及当前的各种状态,因此系统事先设置好 CPU 寄存器和程序计数器。CPU 上下文切换,就是先把前一个任务的 CPU 上下文(CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务,而保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。
进程上下文切换是消耗时间的,平均下文切换都需要几十纳秒到数微秒的 CPU 时间,因此如果进程上下文切换次数过多,就会导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间,实际上有效的CPU运行时间大大减少(可以认为上下文切换对用户来说是在做无用功)
上下文切换的时机:
- 根据调度策略,将CPU时间划片为对应的时间片,当时间片耗尽,就需要进行上下文切换
- 进程在系统资源不足,会在获取到足够资源之前进程挂起
- 进程通过sleep函数将自己挂起
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行,也就是被抢占
- 当发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序
现代操作系统中,线程是调度的基本单位,而进程则是资源拥有的基本单位,因此也会发生线程切换。如果是同一进程内的线程切换,由于大部分资源是共享的,因此不需要保存,只保存寄存器等不共享数据,因此这时候的线程切换是更轻量级更快的。如果不是同意进程内的线程切换,就等于进程切换了,花销稍大。
查看上下文切换:
vmstat命令可以看到系统整体的context switches次数:
[root@jessy ~]# vmstat 2procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st3 0 0 5492032 220452 2105940 0 0 0 5 2 1 0 0 100 0 03 0 0 5492412 220452 2105952 0 0 0 369 3267 2204 0 50 48 2 02 0 0 5492340 220452 2105968 0 0 0 342 3427 2477 0 49 50 1 0
- cs:每秒上下文切换的次数
- in:每秒中断的次数
- r:就绪队列的长度,即正在运行和等待 CPU 的进程数。
- b:处于不可中断睡眠状态的进程数
可以通过pidstat查看每个进程的上下文切换情况:-w
[root@jessy ~]# pidstat -wLinux 3.10.0-1062.18.1.el7.x86_64 (jessy) 07/22/2020 _x86_64_ (4 CPU)03:10:50 PM UID PID cswch/s nvcswch/s Command03:10:50 PM 0 1 1.10 0.00 systemd03:10:50 PM 0 2 0.00 0.00 kthreadd03:10:50 PM 0 4 0.00 0.00 kworker/0:0H03:10:50 PM 0 6 0.07 0.00 ksoftirqd/003:10:50 PM 0 7 0.34 0.00 migration/003:10:50 PM 0 8 0.00 0.00 rcu_bh03:10:50 PM 0 9 14.76 0.00 rcu_sched
- cswch :表示每秒自愿上下文切换的次数 是指进程无法获取所需资源,导致的上下文切换
- nvcswch :表示每秒非自愿上下文切换的次数 指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换
案例分析
工具:sysbench(一个多线程的基准测试工具)和sysstat (监控分析系统性能的工具) 下载方法:用yum install 即可 或者 apt-get install
环境:Xshell连接的Linux远程主机,版本3.10
在第一个终端里运行 sysbench ,模拟系统多线程调度的瓶颈:
# 20个线程运行,模拟多线程切换的问题$ sysbench --threads=20 threads run
在另一个终端用vmstat查看系统的上下文切换次数:
[root@jessy ~]# vmstat 1procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st5 0 0 5483872 220568 2114760 0 0 0 5 3 2 0 0 100 0 05 0 0 5483788 220568 2114760 0 0 0 0 24004 733269 35 56 9 0 05 0 0 5483804 220568 2114760 0 0 0 80 33083 688786 33 55 12 0 05 0 0 5483828 220568 2114760 0 0 0 0 21859 760155 32 58 9 0 06 0 0 5483912 220568 2114764 0 0 0 0 31601 794251 33 55 12 0 05 0 0 5483912 220568 2114764 0 0 0 0 22575 671252 35 56 9 0 0
可以看到每秒的上下文切换次数达到了70万次左右,这一定会大大影响系统性能,就绪队列中的进程数量也明显提升,已经高于CPU数量了,us和sy使用率较高,加起来在接近100%,同时in的数量非常高,说明每秒的中断次数非常高
用pidstat查看具体的情况, (-t可以显示出更具体的线程切换次数)
[root@jessy ~]# pidstat -wt -u 1Linux 3.10.0-1062.18.1.el7.x86_64 (jessy) 07/22/2020 _x86_64_ (4 CPU)03:41:38 PM UID TGID TID %usr %system %guest %CPU CPU Command03:41:39 PM 0 3612 - 0.98 0.00 0.00 0.98 2 barad_agent03:41:39 PM 0 18524 - 100.00 100.00 0.00 100.00 2 sysbench03:41:39 PM 0 - 18530 3.92 8.82 0.00 12.75 3 |__sysbench03:41:39 PM 0 - 18531 7.84 12.75 0.00 20.59 0 |__sysbench03:41:39 PM 0 - 18532 7.84 11.76 0.00 19.61 0 |__sysbench....03:41:38 PM UID TGID TID cswch/s nvcswch/s Command03:41:39 PM 0 1 - 0.98 0.00 systemd03:41:39 PM 0 - 18539 10184.31 38460.78 |__sysbench03:41:39 PM 0 - 18540 9807.84 31880.39 |__sysbench03:41:39 PM 0 - 18541 8456.86 23916.67 |__sysbench03:41:39 PM 0 - 18542 8710.78 25382.35 |__sysbench03:41:39 PM 0 - 18543 9375.49 29080.39 |__sysbench03:41:39 PM 0 - 18544 11208.82 31827.45 |__sysbench03:41:39 PM 0 18555 - 0.98 1.96 pidstat...
可以看到sysbench的系统CPU占用率达到了100%,并且几乎占据了所有的usr和sys时间。也能看到sysbench的进程中存在这大量的自愿上下文切换和非自愿上下文切换
查看中断情况:
watch -d cat /proc/interrupts
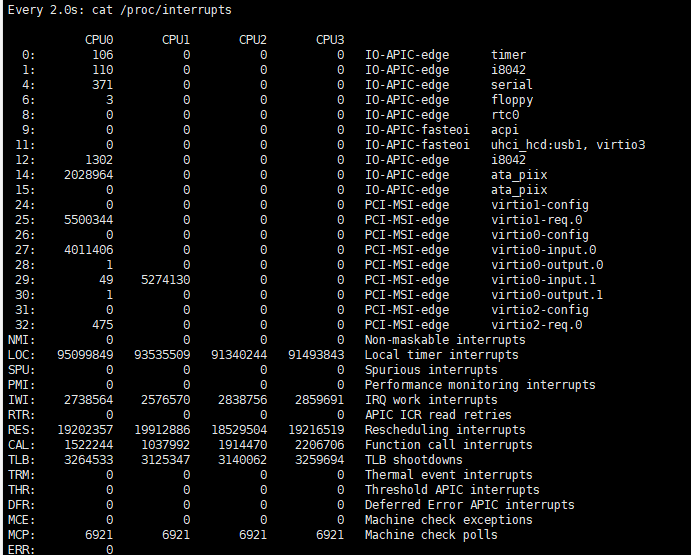
可以看到LOC和RES值非常高,LOC是计时器中断,RES是Rescheduling interrupts,也就是调度中断,因此可以基本确定,中断的产生主要是因为频繁的调度,也就是任务过多引起过多上下文切换导致的。
不可中断进程过多
僵尸进程,表示进程已经退出,但它的父进程还没有回收子进程占用的资源。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源。通常来说,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由 init 进程回收后也会消亡。但是如果父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避免。
不可中断状态,表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。当 iowait 升高时,进程很可能因为得不到硬件的响应,而长时间处于不可中断状态。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
通常可以用top命令和ps命令查看系统的进程状态:
[root@VM-238-167-centos /]# toptop - 11:43:46 up 19:21, 2 users, load average: 81.48, 35.56, 13.78Tasks: 258 total, 2 running, 253 sleeping, 1 stopped, 2 zombie%Cpu(s): 0.2 us, 0.3 sy, 0.0 ni, 34.6 id, 64.8 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 16165976 total, 8499940 free, 6695244 used, 970792 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 9338500 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 32016 root 20 0 7076 6232 808 R 1.0 0.0 3:35.52 sap100226849 root 20 0 70040 65528 44 D 0.3 0.4 0:00.02 app17626 root 20 0 0 0 0 S 0.3 0.0 0:00.06 kworker/6:2 32018 root 20 0 23336 8680 1164 S 0.3 0.1 0:21.21 sap1004 32031 root 20 0 45228 26664 5832 S 0.3 0.2 1:16.57 sap1009 1 root 20 0 53128 4336 2488 S 0.0 0.0 0:08.35 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
可以看到S即为进程状态,包括R:运行状态 S:Sleep状态 D:不可中断状态
案例分析:【该实验有可能直接导致死机,因为负载会达到非常高的地步,故根据设备配置实验】
docker镜像:https://github.com/feiskyer/linux-perf-examples/tree/master/high-iowait-process
运行了镜像实例,这是一个高IO的实例,运行这个docker程序后可以看到:
[root@VM-238-167-centos /]# ps aux | grep /approot 26564 0.0 0.0 4500 564 pts/0 Ss+ 11:39 0:00 /app -d /dev/vdb1root 26622 0.0 0.4 70040 65528 pts/0 D+ 11:39 0:00 /app -d /dev/vdb1root 26623 0.0 0.4 70040 65528 pts/0 D+ 11:39 0:00 /app -d /dev/vdb1root 26629 0.0 0.4 70040 65528 pts/0 D+ 11:39 0:00 /app -d /dev/vdb1root 26630 0.0 0.4 70040 65528 pts/0 D+ 11:39 0:00 /app -d /dev/vdb1....[root@VM-238-167-centos /]# toptop - 11:43:46 up 19:21, 2 users, load average: 81.48, 35.56, 13.78Tasks: 258 total, 2 running, 253 sleeping, 1 stopped, 2 zombie%Cpu(s): 0.2 us, 0.3 sy, 0.0 ni, 34.6 id, 64.8 wa, 0.0 hi, 0.0 si, 0.0 st
查看top可以知道平均负载极高!但是CPU利用率很低,io使用率很高,说明大概率是因为IO导致了如此高的系统负载。
在终端中运行 dstat 命令,观察 CPU 和 I/O 的使用情况:
[root@VM-238-167-centos /]# dstat 1 10----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--usr sys idl wai hiq siq| read writ| recv send| in out | int csw0 0 100 0 0 0| 682k 48k| 0 0 | 0 0 | 797 8080 0 68 32 0 0| 130M 20k| 54B 146B| 0 0 |1040 8270 0 75 25 0 0| 130M 0 | 96B 860B| 0 0 |1022 7890 0 75 25 0 0| 130M 0 | 331B 894B| 0 0 |1071 8560 0 72 28 0 0| 130M 24k| 54B 42B| 0 0 |1057 8230 0 63 37 0 0| 130M 0 | 146B 388B| 0 0 |1036 7890 0 63 37 0 0| 130M 0 | 96B 700B| 0 0 |1043 7980 0 62 37 0 0| 130M 932k| 54B 42B| 0 0 |1033 7970 0 62 37 0 0| 130M 0 | 96B 388B| 0 0 |1033 7980 0 67 33 0 0| 130M 20k|1064B 7858B| 0 0 |1054 8431 0 62 37 0 0| 130M 0 | 54B 42B| 0 0 |1074 789
可以看到 iowait 升高(wai)时,磁盘的读请求(read)都会很大。这说明 iowait 的升高跟磁盘的读请求有关,很可能就是磁盘读导致的。
因此就需要找一些是哪些进程在频繁read,用top查找:
[root@VM-238-167-centos /]# toptop - 14:44:34 up 2:45, 2 users, load average: 43.34, 15.43, 5.63Tasks: 212 total, 1 running, 209 sleeping, 0 stopped, 2 zombie%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 59.0 id, 40.8 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 16165976 total, 11210260 free, 4318284 used, 637432 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 11722680 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1160 root 20 0 70040 65524 44 D 0.3 0.4 0:00.01 app 1166 root 20 0 70040 65524 44 D 0.3 0.4 0:00.01 app 1315 root 20 0 70040 65524 44 D 0.3 0.4 0:00.01 app 7852 root 20 0 38008 19720 1168 S 0.3 0.1 0:02.06 secu-tcs-agent 9365 root 20 0 7208 6288 804 S 0.3 0.0 0:26.86 sap1002 9381 root 20 0 22612 4276 3700 S 0.3 0.0 0:04.14 sap1007
可以看到CPU负载非常高,但是CPU使用率几乎为0,而有着大量的iowait,并且看到有很多D进程状态,D进程状态是不可中断状态,因此大概率就是这些进程在占据磁盘读,具体去找这些查看查看。
因为top看到1160处于D状态,因此查看是否是该进程的原因:
[root@VM-238-167-centos /]# pidstat -d -p 1160 1 3Linux 3.10.107-1-tlinux2_kvm_guest-0049 (VM-238-167-centos) 07/23/20 _x86_64_ (8 CPU)14:48:42 UID PID kB_rd/s kB_wr/s kB_ccwr/s Command14:48:43 0 1160 0.00 0.00 0.00 app14:48:44 0 1160 0.00 0.00 0.00 app14:48:45 0 1160 0.00 0.00 0.00 appAverage: 0 1160 0.00 0.00 0.00 app
显然,并不是,因为读写都是0。同理发现其他几个也是这样的情况。
索性直接pidstat查看所有的进程情况来分析:
[root@VM-238-167-centos /]# pidstat -d 1 5Linux 3.10.107-1-tlinux2_kvm_guest-0049 (VM-238-167-centos) 07/23/20 _x86_64_ (8 CPU)14:54:33 UID PID kB_rd/s kB_wr/s kB_ccwr/s Command14:54:34 0 3204 503.50 0.00 0.00 app14:54:34 0 3216 520.50 0.00 0.00 app14:54:34 0 3331 16128.00 0.00 0.00 app14:54:34 0 3332 1024.00 0.00 0.00 app14:54:34 0 3337 16128.00 0.00 0.00 app14:54:34 0 3338 16128.00 0.00 0.00 app14:54:34 0 3344 16128.00 0.00 0.00 app14:54:34 0 3349 16128.00 0.00 0.00 app14:54:34 0 3356 16128.00 0.00 0.00 app14:54:34 0 3357 16128.00 0.00 0.00 app14:54:34 0 3364 16128.00 0.00 0.00 app14:54:34 0 3365 16128.00 0.00 0.00 app
发现确实是app进程在运行,并且占据了非常大的read。
用strace看一下3204进程的系统调用情况:
[root@VM-238-167-centos /]# strace -p 3204strace: attach: ptrace(PTRACE_ATTACH, ...): Operation not permitted
显示没有权限,很不科学,已经是root了,那么看一下这个进程的状态:
[root@VM-238-167-centos /]# ps aux | grep 3204root 3204 0.0 0.0 0 0 pts/0 Z+ 14:53 0:00 [app] <defunct>
发现变成了僵尸状态。
用perf top分析问题所在,找到app后进入其中看看,展开调用栈分析
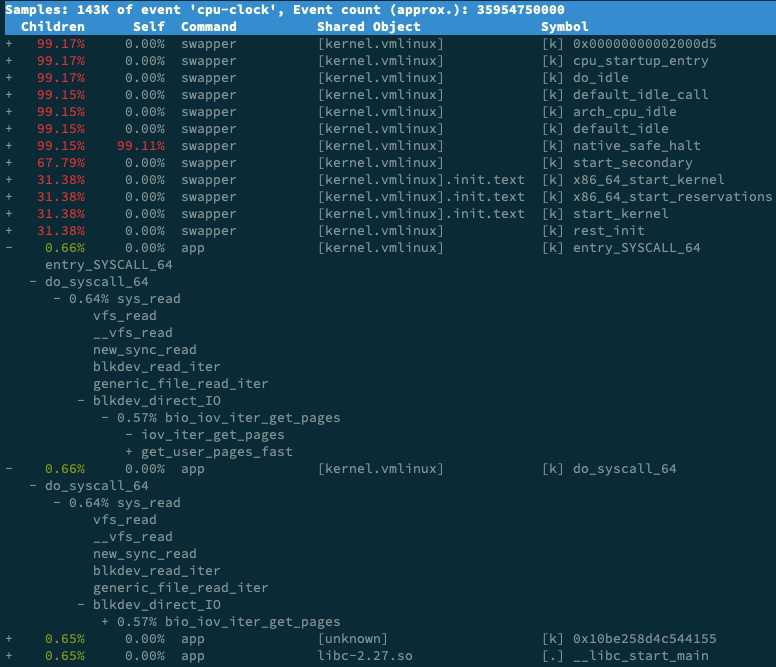
看出进程在在通过系统调用 sys_read() 读取数据。并且从 new_sync_read 和 blkdev_direct_IO 能看出,进程正在对磁盘进行直接读,也就是绕过了系统缓存,每个读请求都会从磁盘直接读。
然后分析源码,发现
open(disk, O_RDONLY|O_DIRECT|O_LARGEFILE, 0755)
O_DIRECT,直接读写磁盘,删掉该选项。然后运行发现iowait非常低,该问题找到并解决。
这个例子中磁盘 I/O 导致了 iowait 升高,不过, iowait 高不一定代表 I/O 有性能瓶颈。当系统中只有 I/O 类型的进程在运行时,iowait 也会很高,但实际上,磁盘的读写远没有达到性能瓶颈的程度。因此,碰到 iowait 升高时,需要先用 dstat、pidstat 等工具,确认是不是磁盘 I/O 的问题,然后再找是哪些进程导致了 I/O。等待 I/O 的进程一般是不可中断状态,所以用 ps 命令找到的 D 状态(即不可中断状态)的进程,多为可疑进程。然后用strace分析,或者用 perf 工具,来分析系统的 CPU 时钟事件,找到问题的原因。

























跳跃链表")


还没有评论,来说两句吧...